 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Representations of Satellite Images with Evaluations on Synoptic Weather Events
Aug 08, 2025This study applied representation learning algorithms to satellite images and evaluated the learned latent spaces with classifications of various weather events. The algorithms investigated include the classical linear transformation, i.e., principal component analysis (PCA), state-of-the-art deep learning method, i.e., convolutional autoencoder (CAE), and a residual network pre-trained with large image datasets (PT). The experiment results indicated that the latent space learned by CAE consistently showed higher threat scores for all classification tasks. The classifications with PCA yielded high hit rates but also high false-alarm rates. In addition, the PT performed exceptionally well at recognizing tropical cyclones but was inferior in other tasks. Further experiments suggested that representations learned from higher-resolution datasets are superior in all classification tasks for deep-learning algorithms, i.e., CAE and PT. We also found that smaller latent space sizes had minor impact on the classification task's hit rate. Still, a latent space dimension smaller than 128 caused a significantly higher false alarm rate. Though the CAE can learn latent spaces effectively and efficiently, the interpretation of the learned representation lacks direct connections to physical attributions. Therefore, developing a physics-informed version of CAE can be a promising outlook for the current work.
A Deep Learning Approach to Radar-based QPE
Feb 15, 2024In this study, we propose a volume-to-point framework for quantitative precipitation estimation (QPE) based on the Quantitative Precipitation Estimation and Segregation Using Multiple Sensor (QPESUMS) Mosaic Radar data set. With a data volume consisting of the time series of gridded radar reflectivities over the Taiwan area, we used machine learning algorithms to establish a statistical model for QPE in weather stations. The model extracts spatial and temporal features from the input data volume and then associates these features with the location-specific precipitations. In contrast to QPE methods based on the Z-R relation, we leverage the machine learning algorithms to automatically detect the evolution and movement of weather systems and associate these patterns to a location with specific topographic attributes. Specifically, we evaluated this framework with the hourly precipitation data of 45 weather stations in Taipei during 2013-2016. In comparison to the operational QPE scheme used by the Central Weather Bureau, the volume-to-point framework performed comparably well in general cases and excelled in detecting heavy-rainfall events. By using the current results as the reference benchmark, the proposed method can integrate the heterogeneous data sources and potentially improve the forecast in extreme precipitation scenarios.
* 22 pages, 11 figures. Published in Earth and Space Science
Identification of synoptic weather types over Taiwan area with multiple classifiers
May 21, 2019



In this study, a novel machine learning approach was used to classify three types of synoptic weather events in Taiwan area from 2001 to 2010. We used reanalysis data with three machine learning algorithms to recognize weather systems and evaluated their performance. Overall, the classifiers successfully identified 52-83% of weather events (hit rate), which is higher than the performance of traditional objective methods. The results showed that the machine learning approach gave low false alarm rate in general, while the support vector machine (SVM) with more principal components of reanalysis data had higher hit rate on all tested weather events. The sensitivity tests of grid data resolution indicated that the differences between the high- and low-resolution datasets are limited, which implied that the proposed method can achieve reasonable performance in weather forecasting with minimal resources. By identifying daily weather systems in historical reanalysis data, this method can be used to study long-term weather changes, to monitor climatological-scale variations, and to provide a better estimate of climate projections. Furthermore, this method can also serve as an alternative to model output statistics and potentially be used for synoptic weather forecasting.
* journal article, open access
A realistic and robust model for Chinese word segmentation
May 21, 2019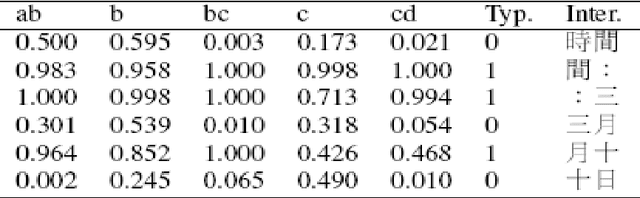
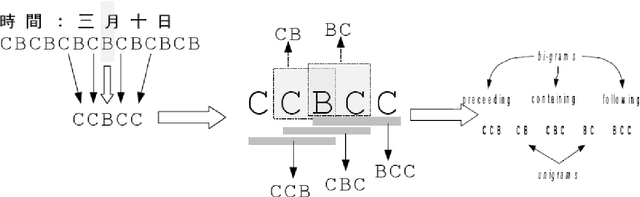
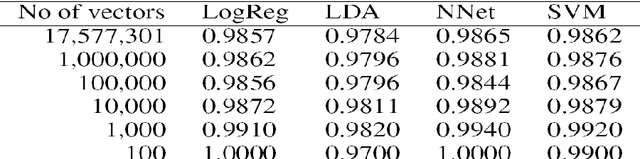
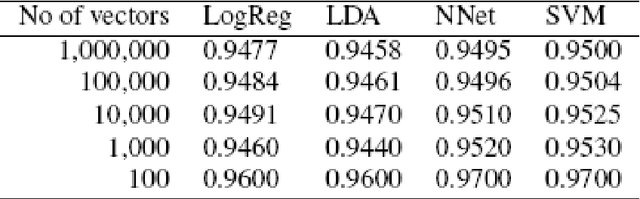
A realistic Chinese word segmentation tool must adapt to textual variations with minimal training input and yet robust enough to yield reliable segmentation result for all variants. Various lexicon-driven approaches to Chinese segmentation, e.g. [1,16], achieve high f-scores yet require massive training for any variation. Text-driven approach, e.g. [12], can be easily adapted for domain and genre changes yet has difficulty matching the high f-scores of the lexicon-driven approaches. In this paper, we refine and implement an innovative text-driven word boundary decision (WBD) segmentation model proposed in [15]. The WBD model treats word segmentation simply and efficiently as a binary decision on whether to realize the natural textual break between two adjacent characters as a word boundary. The WBD model allows simple and quick training data preparation converting characters as contextual vectors for learning the word boundary decision. Machine learning experiments with four different classifiers show that training with 1,000 vectors and 1 million vectors achieve comparable and reliable results. In addition, when applied to SigHAN Bakeoff 3 competition data, the WBD model produces OOV recall rates that are higher than all published results. Unlike all previous work, our OOV recall rate is comparable to our own F-score. Both experiments support the claim that the WBD model is a realistic model for Chinese word segmentation as it can be easily adapted for new variants with the robust result. In conclusion, we will discuss linguistic ramifications as well as future implications for the WBD approach.
A comparison of evaluation methods in coevolution
May 21, 2019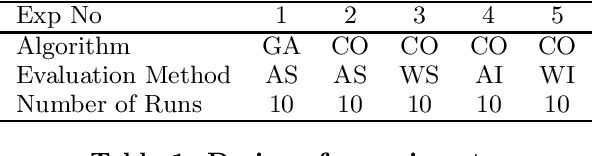

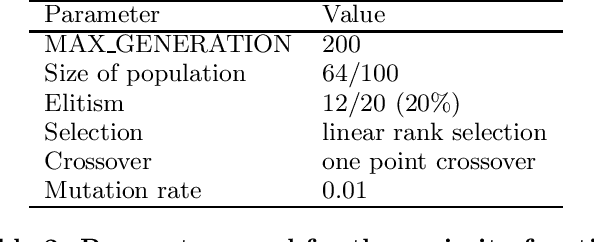
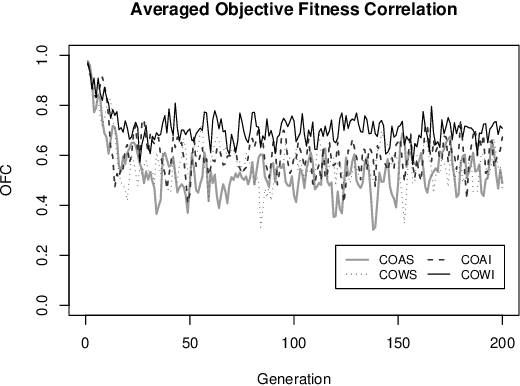
In this research, we compare four different evaluation methods in coevolution on the Majority Function problem. The size of the problem is selected such that evaluation against all possible test cases is feasible. Two measures are used for the comparisons, i.e., the objective fitness derived from evaluating solutions against all test cases, and the objective fitness correlation (OFC), which is defined as the correlation coefficient between subjective and objective fitness. The results of our experiments suggest that a combination of average score and weighted informativeness may provide a more accurate evaluation in coevolution. In order to confirm this difference, a series of t-tests on the preference between each pair of the evaluation methods is performed. The resulting significance is affirmative, and the tests for two quality measures show similar preference on four evaluation methods. %This study is the first time OFC is actually computed on a real problem. Experiments on Majority Function problems with larger sizes and Parity problems are in progress, and their results will be added in the final version.