 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2026 Task 7: Everyday Knowledge Across Diverse Languages and Cultures
May 04, 2026We present our shared task on evaluating the adaptability of LLMs and NLP systems across multiple languages and cultures. The task data consist of an extended version of our manually constructed BLEnD benchmark (Myung et al. 2024), covering more than 30 language-culture pairs, predominantly representing low-resource languages spoken across multiple continents. As the task is designed strictly for evaluation, participants were not permitted to use the data for training, fine-tuning, few-shot learning, or any other form of model modification. Our task includes two tracks: (a) Short-Answer Questions (SAQ) and (b) Multiple-Choice Questions (MCQ). Participants were required to predict labels and were allowed to submit any NLP system and adopt diverse modelling strategies, provided that the benchmark was used solely for evaluation. The task attracted more than 140 registered participants, and we received final submissions from 62 teams, along with 19 system description papers. We report the results and present an analysis of the best-performing systems and the most commonly adopted approaches. Furthermore, we discuss shared insights into open questions and challenges related to evaluation, misalignment, and methodological perspectives on model behaviour in low-resource languages and for under-represented cultures.
LingBench++: A Linguistically-Informed Benchmark and Reasoning Framework for Multi-Step and Cross-Cultural Inference with LLMs
Jul 24, 2025



We propose LingBench++, a linguistically-informed benchmark and reasoning framework designed to evaluate large language models (LLMs) on complex linguistic tasks inspired by the International Linguistics Olympiad (IOL). Unlike prior benchmarks that focus solely on final answer accuracy, LingBench++ provides structured reasoning traces, stepwise evaluation protocols, and rich typological metadata across over 90 low-resource and cross-cultural languages. We further develop a multi-agent architecture integrating grammatical knowledge retrieval, tool-augmented reasoning, and deliberate hypothesis testing. Through systematic comparisons of baseline and our proposed agentic models, we demonstrate that models equipped with external knowledge sources and iterative reasoning outperform single-pass approaches in both accuracy and interpretability. LingBench++ offers a comprehensive foundation for advancing linguistically grounded, culturally informed, and cognitively plausible reasoning in LLMs.
Spontaneous Speech Variables for Evaluating LLMs Cognitive Plausibility
May 22, 2025


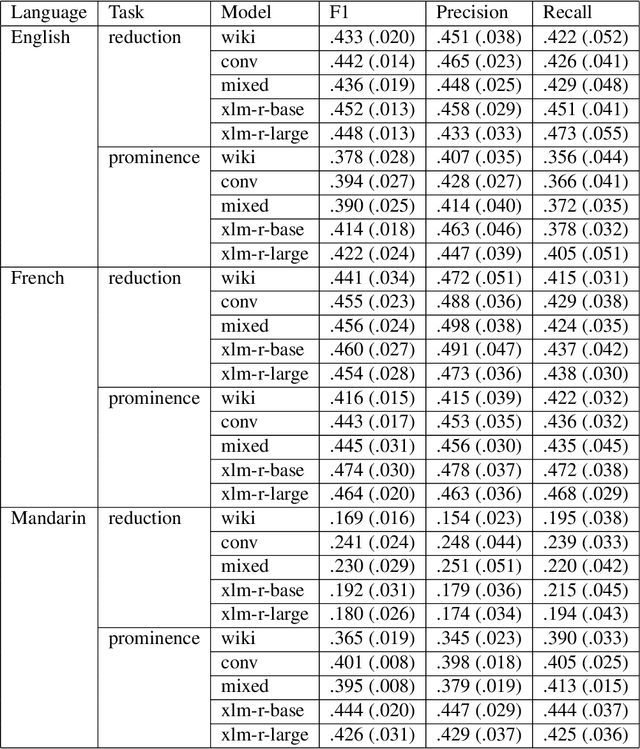
The achievements of Large Language Models in Natural Language Processing, especially for high-resource languages, call for a better understanding of their characteristics from a cognitive perspective. Researchers have attempted to evaluate artificial models by testing their ability to predict behavioral (e.g., eye-tracking fixations) and physiological (e.g., brain responses) variables during language processing (e.g., reading/listening). In this paper, we propose using spontaneous speech corpora to derive production variables (speech reductions, prosodic prominences) and applying them in a similar fashion. More precisely, we extract. We then test models trained with a standard procedure on different pretraining datasets (written, spoken, and mixed genres) for their ability to predict these two variables. Our results show that, after some fine-tuning, the models can predict these production variables well above baselines. We also observe that spoken genre training data provides more accurate predictions than written genres. These results contribute to the broader effort of using high-quality speech corpora as benchmarks for LLMs.
Continual Pre-Training is (not) What You Need in Domain Adaption
Apr 18, 2025The recent advances in Legal Large Language Models (LLMs) have transformed the landscape of legal research and practice by automating tasks, enhancing research precision, and supporting complex decision-making processes. However, effectively adapting LLMs to the legal domain remains challenging due to the complexity of legal reasoning, the need for precise interpretation of specialized language, and the potential for hallucinations. This paper examines the efficacy of Domain-Adaptive Continual Pre-Training (DACP) in improving the legal reasoning capabilities of LLMs. Through a series of experiments on legal reasoning tasks within the Taiwanese legal framework, we demonstrate that while DACP enhances domain-specific knowledge, it does not uniformly improve performance across all legal tasks. We discuss the trade-offs involved in DACP, particularly its impact on model generalization and performance in prompt-based tasks, and propose directions for future research to optimize domain adaptation strategies in legal AI.
Probing Large Language Models in Reasoning and Translating Complex Linguistic Puzzles
Feb 02, 2025This paper investigates the utilization of Large Language Models (LLMs) for solving complex linguistic puzzles, a domain requiring advanced reasoning and adept translation capabilities akin to human cognitive processes. We explore specific prompting techniques designed to enhance ability of LLMs to reason and elucidate their decision-making pathways, with a focus on Input-Output Prompting (IO), Chain-of-Thought Prompting (CoT), and Solo Performance Prompting (SPP). Utilizing datasets from the Puzzling Machine Competition and various Linguistics Olympiads, we employ a comprehensive set of metrics to assess the performance of GPT-4 0603, a prominent LLM, across these prompting methods. Our findings illuminate the potential of LLMs in linguistic reasoning and complex translation tasks, highlighting their capabilities and identifying limitations in the context of linguistic puzzles. This research contributes significantly to the broader field of Natural Language Processing (NLP) by providing insights into the optimization of LLM applications for improved reasoning and translation accuracy, thereby enriching the ongoing dialogue in NLP advancements.
Reasoning Over the Glyphs: Evaluation of LLM's Decipherment of Rare Scripts
Jan 29, 2025We explore the capabilities of LVLMs and LLMs in deciphering rare scripts not encoded in Unicode. We introduce a novel approach to construct a multimodal dataset of linguistic puzzles involving such scripts, utilizing a tokenization method for language glyphs. Our methods include the Picture Method for LVLMs and the Description Method for LLMs, enabling these models to tackle these challenges. We conduct experiments using prominent models, GPT-4o, Gemini, and Claude 3.5 Sonnet, on linguistic puzzles. Our findings reveal the strengths and limitations of current AI methods in linguistic decipherment, highlighting the impact of Unicode encoding on model performance and the challenges of modeling visual language tokens through descriptions. Our study advances understanding of AI's potential in linguistic decipherment and underscores the need for further research.
A Topic-aware Comparable Corpus of Chinese Variations
Nov 17, 2024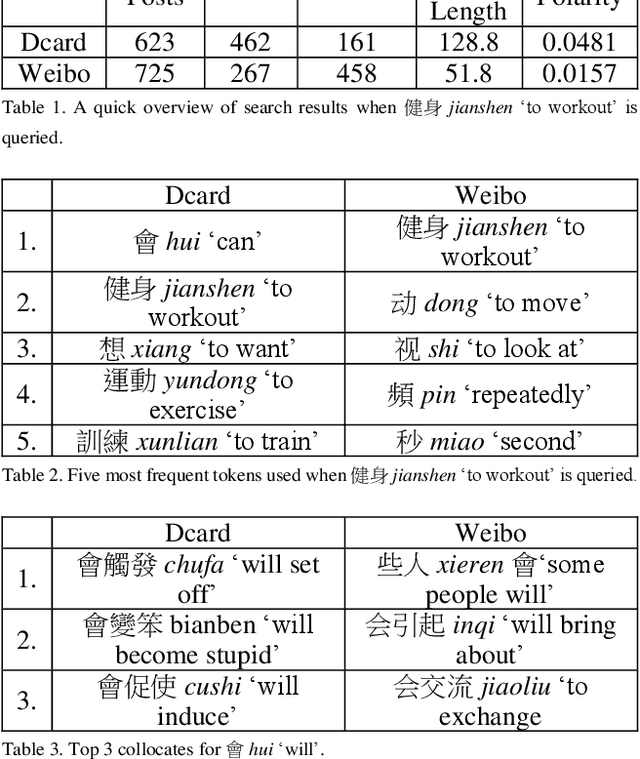
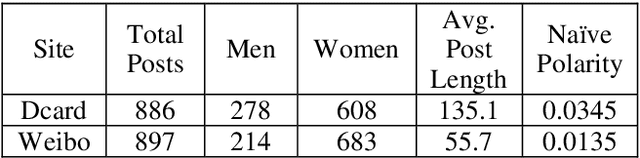
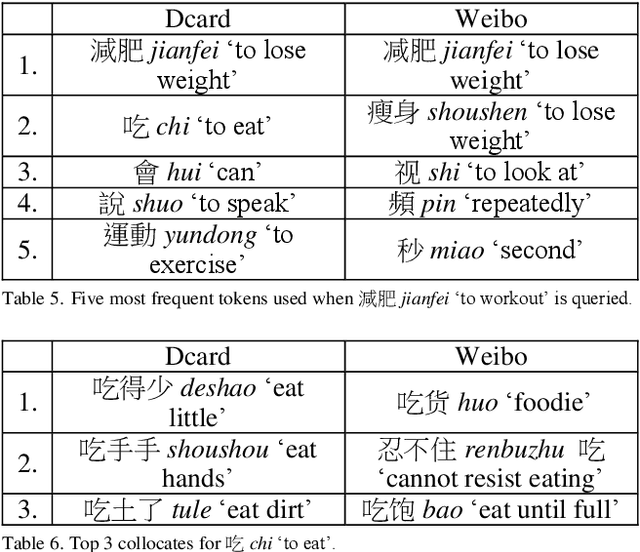
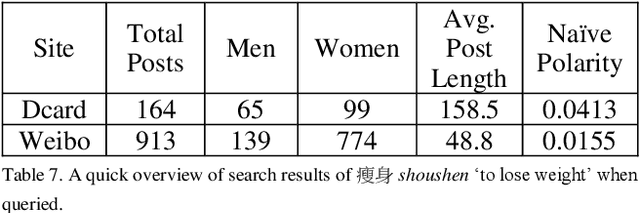
This study aims to fill the gap by constructing a topic-aware comparable corpus of Mainland Chinese Mandarin and Taiwanese Mandarin from the social media in Mainland China and Taiwan, respectively. Using Dcard for Taiwanese Mandarin and Sina Weibo for Mainland Chinese, we create a comparable corpus that updates regularly and reflects modern language use on social media.
Resolving Regular Polysemy in Named Entities
Jan 18, 2024



Word sense disambiguation primarily addresses the lexical ambiguity of common words based on a predefined sense inventory. Conversely, proper names are usually considered to denote an ad-hoc real-world referent. Once the reference is decided, the ambiguity is purportedly resolved. However, proper names also exhibit ambiguities through appellativization, i.e., they act like common words and may denote different aspects of their referents. We proposed to address the ambiguities of proper names through the light of regular polysemy, which we formalized as dot objects. This paper introduces a combined word sense disambiguation (WSD) model for disambiguating common words against Chinese Wordnet (CWN) and proper names as dot objects. The model leverages the flexibility of a gloss-based model architecture, which takes advantage of the glosses and example sentences of CWN. We show that the model achieves competitive results on both common and proper nouns, even on a relatively sparse sense dataset. Aside from being a performant WSD tool, the model further facilitates the future development of the lexical resource.
Vec2Gloss: definition modeling leveraging contextualized vectors with Wordnet gloss
May 29, 2023Contextualized embeddings are proven to be powerful tools in multiple NLP tasks. Nonetheless, challenges regarding their interpretability and capability to represent lexical semantics still remain. In this paper, we propose that the task of definition modeling, which aims to generate the human-readable definition of the word, provides a route to evaluate or understand the high dimensional semantic vectors. We propose a `Vec2Gloss' model, which produces the gloss from the target word's contextualized embeddings. The generated glosses of this study are made possible by the systematic gloss patterns provided by Chinese Wordnet. We devise two dependency indices to measure the semantic and contextual dependency, which are used to analyze the generated texts in gloss and token levels. Our results indicate that the proposed `Vec2Gloss' model opens a new perspective to the lexical-semantic applications of contextualized embeddings.
Lexical Retrieval Hypothesis in Multimodal Context
May 28, 2023Multimodal corpora have become an essential language resource for language science and grounded natural language processing (NLP) systems due to the growing need to understand and interpret human communication across various channels. In this paper, we first present our efforts in building the first Multimodal Corpus for Languages in Taiwan (MultiMoco). Based on the corpus, we conduct a case study investigating the Lexical Retrieval Hypothesis (LRH), specifically examining whether the hand gestures co-occurring with speech constants facilitate lexical retrieval or serve other discourse functions. With detailed annotations on eight parliamentary interpellations in Taiwan Mandarin, we explore the co-occurrence between speech constants and non-verbal features (i.e., head movement, face movement, hand gesture, and function of hand gesture). Our findings suggest that while hand gestures do serve as facilitators for lexical retrieval in some cases, they also serve the purpose of information emphasis. This study highlights the potential of the MultiMoco Corpus to provide an important resource for in-depth analysis and further research in multimodal communication studies.