 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord-specific tonal realizations in Mandarin
May 11, 2024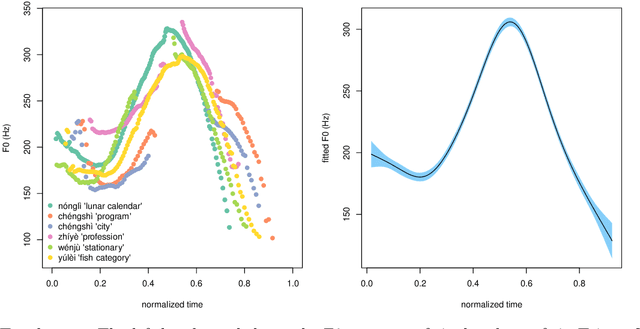
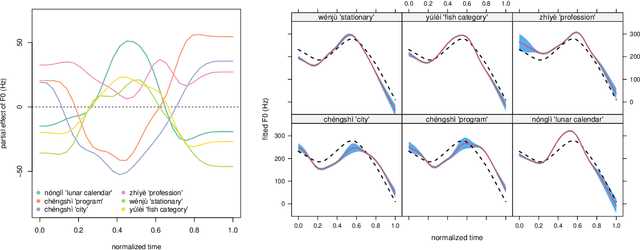
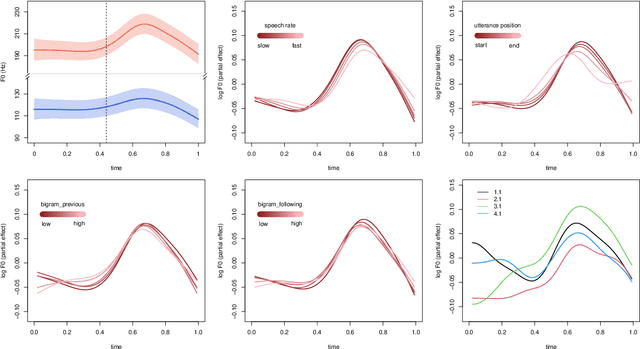
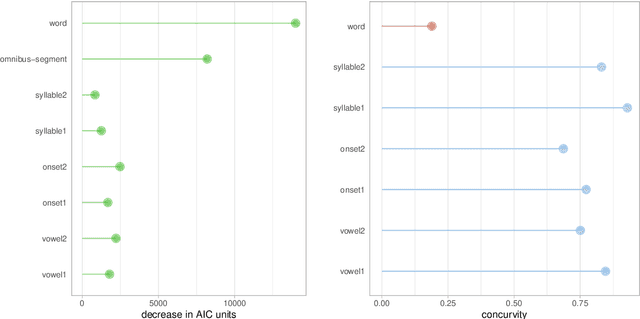
The pitch contours of Mandarin two-character words are generally understood as being shaped by the underlying tones of the constituent single-character words, in interaction with articulatory constraints imposed by factors such as speech rate, co-articulation with adjacent tones, segmental make-up, and predictability. This study shows that tonal realization is also partially determined by words' meanings. We first show, on the basis of a Taiwan corpus of spontaneous conversations, using the generalized additive regression model, and focusing on the rise-fall tone pattern, that after controlling for effects of speaker and context, word type is a stronger predictor of pitch realization than all the previously established word-form related predictors combined. Importantly, the addition of information about meaning in context improves prediction accuracy even further. We then proceed to show, using computational modeling with context-specific word embeddings, that token-specific pitch contours predict word type with 50% accuracy on held-out data, and that context-sensitive, token-specific embeddings can predict the shape of pitch contours with 30% accuracy. These accuracies, which are an order of magnitude above chance level, suggest that the relation between words' pitch contours and their meanings are sufficiently strong to be functional for language users. The theoretical implications of these empirical findings are discussed.
Resolving Regular Polysemy in Named Entities
Jan 18, 2024



Word sense disambiguation primarily addresses the lexical ambiguity of common words based on a predefined sense inventory. Conversely, proper names are usually considered to denote an ad-hoc real-world referent. Once the reference is decided, the ambiguity is purportedly resolved. However, proper names also exhibit ambiguities through appellativization, i.e., they act like common words and may denote different aspects of their referents. We proposed to address the ambiguities of proper names through the light of regular polysemy, which we formalized as dot objects. This paper introduces a combined word sense disambiguation (WSD) model for disambiguating common words against Chinese Wordnet (CWN) and proper names as dot objects. The model leverages the flexibility of a gloss-based model architecture, which takes advantage of the glosses and example sentences of CWN. We show that the model achieves competitive results on both common and proper nouns, even on a relatively sparse sense dataset. Aside from being a performant WSD tool, the model further facilitates the future development of the lexical resource.
Vec2Gloss: definition modeling leveraging contextualized vectors with Wordnet gloss
May 29, 2023Contextualized embeddings are proven to be powerful tools in multiple NLP tasks. Nonetheless, challenges regarding their interpretability and capability to represent lexical semantics still remain. In this paper, we propose that the task of definition modeling, which aims to generate the human-readable definition of the word, provides a route to evaluate or understand the high dimensional semantic vectors. We propose a `Vec2Gloss' model, which produces the gloss from the target word's contextualized embeddings. The generated glosses of this study are made possible by the systematic gloss patterns provided by Chinese Wordnet. We devise two dependency indices to measure the semantic and contextual dependency, which are used to analyze the generated texts in gloss and token levels. Our results indicate that the proposed `Vec2Gloss' model opens a new perspective to the lexical-semantic applications of contextualized embeddings.
Lexical Retrieval Hypothesis in Multimodal Context
May 28, 2023Multimodal corpora have become an essential language resource for language science and grounded natural language processing (NLP) systems due to the growing need to understand and interpret human communication across various channels. In this paper, we first present our efforts in building the first Multimodal Corpus for Languages in Taiwan (MultiMoco). Based on the corpus, we conduct a case study investigating the Lexical Retrieval Hypothesis (LRH), specifically examining whether the hand gestures co-occurring with speech constants facilitate lexical retrieval or serve other discourse functions. With detailed annotations on eight parliamentary interpellations in Taiwan Mandarin, we explore the co-occurrence between speech constants and non-verbal features (i.e., head movement, face movement, hand gesture, and function of hand gesture). Our findings suggest that while hand gestures do serve as facilitators for lexical retrieval in some cases, they also serve the purpose of information emphasis. This study highlights the potential of the MultiMoco Corpus to provide an important resource for in-depth analysis and further research in multimodal communication studies.
Exploring the Grounding Issues in Image Caption
May 24, 2023This paper explores the grounding issue concerning multimodal semantic representation from a computational cognitive-linguistic view. Five perceptual properties of groundedness are annotated and analyzed: Affordance, Perceptual salience, Object number, Gaze cueing, and Ecological Niche Association (ENA). We annotated selected images from the Flickr30k dataset with exploratory analyses and statistical modeling of their captions. Our findings suggest that a comprehensive understanding of an object or event requires cognitive attention, semantic distinctions in linguistic expression, and multimodal construction. During this construction process, viewers integrate situated meaning and affordance into multimodal semantics, which is consolidated into image captions used in the image-text dataset incorporating visual and textual elements. Our findings suggest that situated meaning and affordance grounding are critical for grounded natural language understanding systems to generate appropriate responses and show the potential to advance the understanding of human construal in diverse situations.