 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe timing bottleneck: Why timing and overlap are mission-critical for conversational user interfaces, speech recognition and dialogue systems
Jul 28, 2023Speech recognition systems are a key intermediary in voice-driven human-computer interaction. Although speech recognition works well for pristine monologic audio, real-life use cases in open-ended interactive settings still present many challenges. We argue that timing is mission-critical for dialogue systems, and evaluate 5 major commercial ASR systems for their conversational and multilingual support. We find that word error rates for natural conversational data in 6 languages remain abysmal, and that overlap remains a key challenge (study 1). This impacts especially the recognition of conversational words (study 2), and in turn has dire consequences for downstream intent recognition (study 3). Our findings help to evaluate the current state of conversational ASR, contribute towards multidimensional error analysis and evaluation, and identify phenomena that need most attention on the way to build robust interactive speech technologies.
Opening up ChatGPT: Tracking openness, transparency, and accountability in instruction-tuned text generators
Jul 08, 2023Large language models that exhibit instruction-following behaviour represent one of the biggest recent upheavals in conversational interfaces, a trend in large part fuelled by the release of OpenAI's ChatGPT, a proprietary large language model for text generation fine-tuned through reinforcement learning from human feedback (LLM+RLHF). We review the risks of relying on proprietary software and survey the first crop of open-source projects of comparable architecture and functionality. The main contribution of this paper is to show that openness is differentiated, and to offer scientific documentation of degrees of openness in this fast-moving field. We evaluate projects in terms of openness of code, training data, model weights, RLHF data, licensing, scientific documentation, and access methods. We find that while there is a fast-growing list of projects billing themselves as 'open source', many inherit undocumented data of dubious legality, few share the all-important instruction-tuning (a key site where human annotation labour is involved), and careful scientific documentation is exceedingly rare. Degrees of openness are relevant to fairness and accountability at all points, from data collection and curation to model architecture, and from training and fine-tuning to release and deployment.
Building and curating conversational corpora for diversity-aware language science and technology
Mar 10, 2022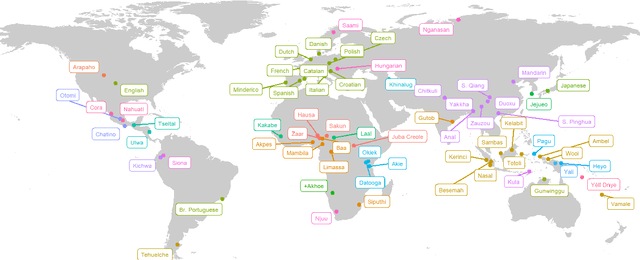
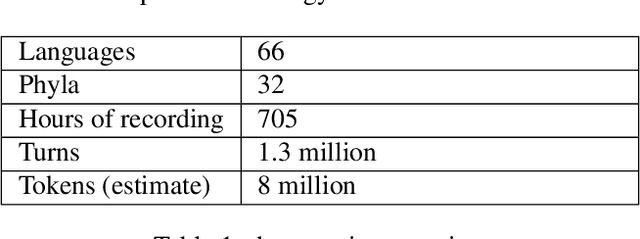
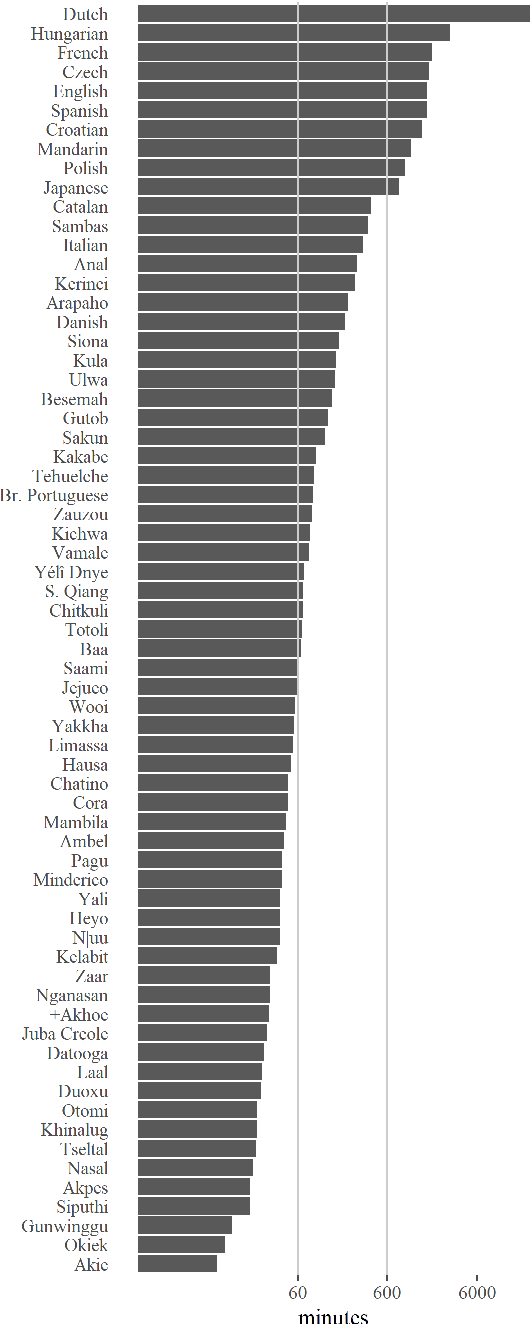

We present a pipeline and tools to build a maximally natural data set of conversational interaction that covers 66 languages and varieties from 32 phyla. We describe the curation and compilation process moving from diverse language documentation corpora to a unified format and describe an open-source tool "convo-parse" to help in quality control and assessment of conversational data. We conclude with two case studies of how diverse data sets can inform interactional linguistics and speech recognition technology and thus contribute to broadening the empirical foundations of language sciences and technologies of the future.
Predicting gender and age categories in English conversations using lexical, non-lexical, and turn-taking features
Feb 26, 2021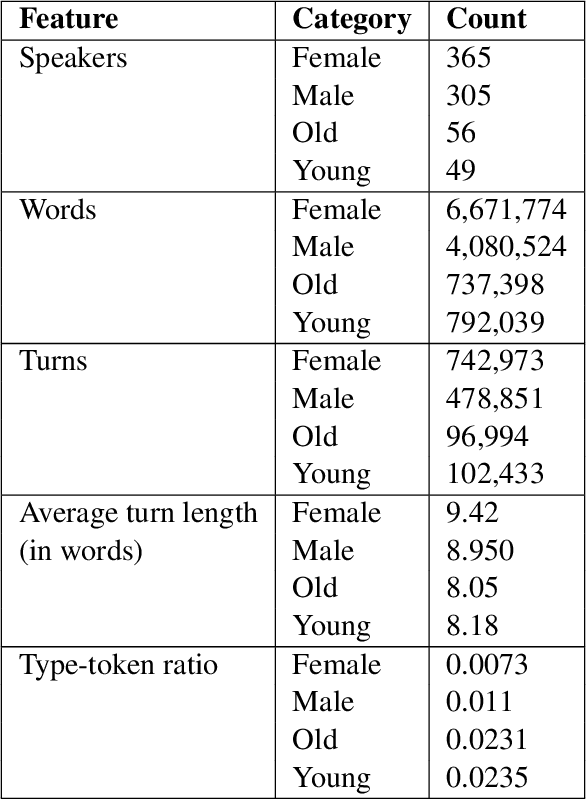

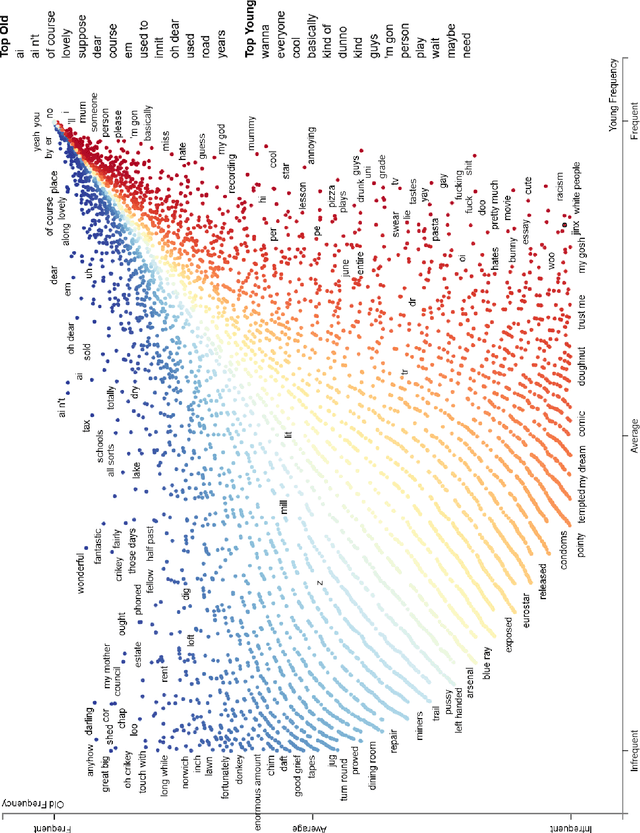
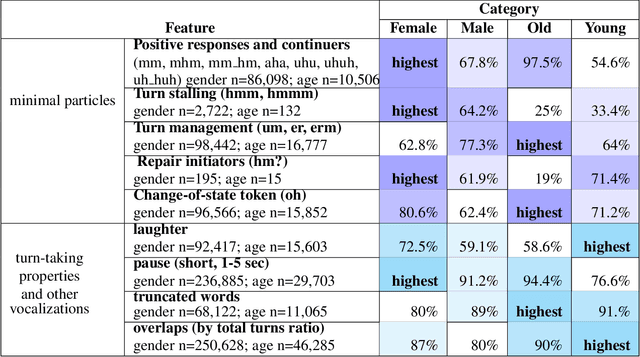
This paper examines gender and age salience and (stereo)typicality in British English talk with the aim to predict gender and age categories based on lexical, phrasal and turn-taking features. We examine the SpokenBNC, a corpus of around 11.4 million words of British English conversations and identify behavioural differences between speakers that are labelled for gender and age categories. We explore differences in language use and turn-taking dynamics and identify a range of characteristics that set the categories apart. We find that female speakers tend to produce more and slightly longer turns, while turns by male speakers feature a higher type-token ratio and a distinct range of minimal particles such as "eh", "uh" and "em". Across age groups, we observe, for instance, that swear words and laughter characterize young speakers' talk, while old speakers tend to produce more truncated words. We then use the observed characteristics to predict gender and age labels of speakers per conversation and per turn as a classification task, showing that non-lexical utterances such as minimal particles that are usually left out of dialog data can contribute to setting the categories apart.