Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding and curating conversational corpora for diversity-aware language science and technology
Paper and Code
Mar 10, 2022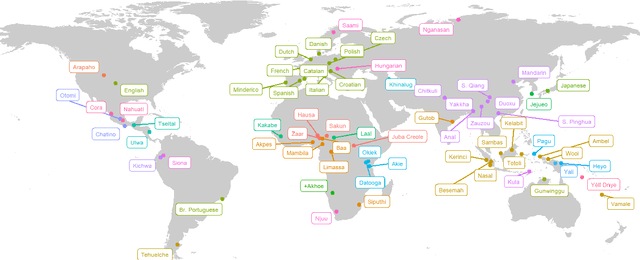
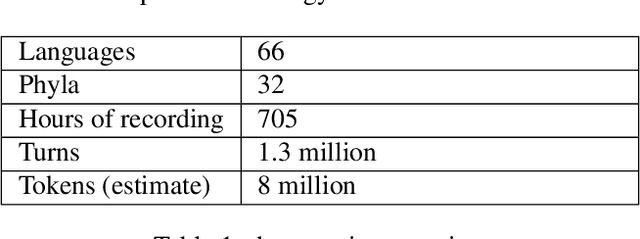
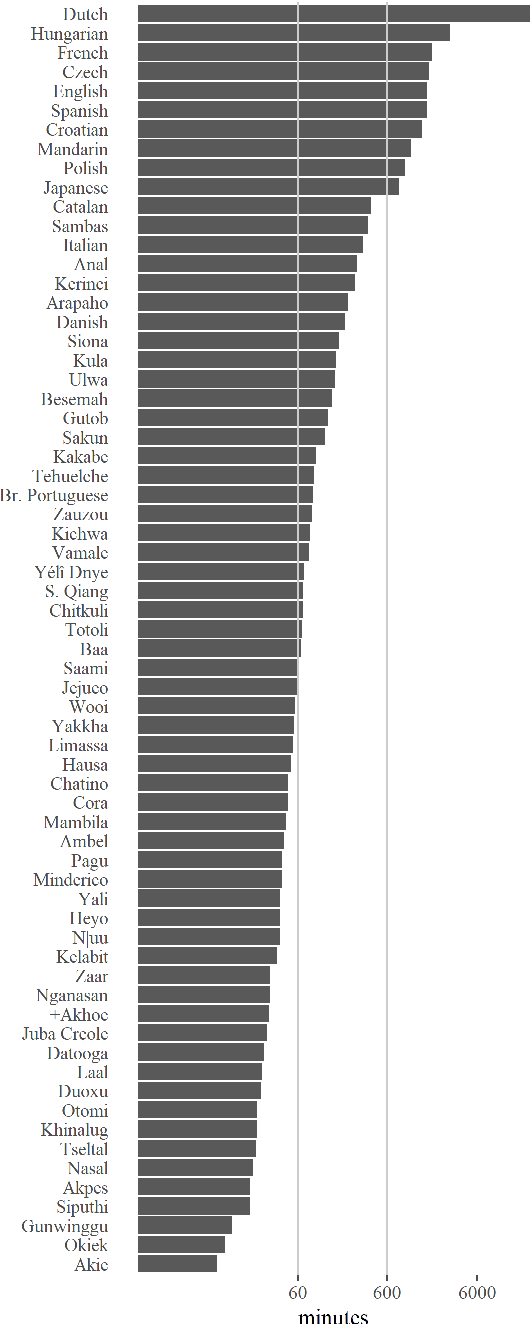

We present a pipeline and tools to build a maximally natural data set of conversational interaction that covers 66 languages and varieties from 32 phyla. We describe the curation and compilation process moving from diverse language documentation corpora to a unified format and describe an open-source tool "convo-parse" to help in quality control and assessment of conversational data. We conclude with two case studies of how diverse data sets can inform interactional linguistics and speech recognition technology and thus contribute to broadening the empirical foundations of language sciences and technologies of the future.
View paper on