 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge'Layer su Layer': Identifying and Disambiguating the Italian NPN Construction in BERT's family
Apr 04, 2026Interpretability research has highlighted the importance of evaluating Pretrained Language Models (PLMs) and in particular contextual embeddings against explicit linguistic theories to determine what linguistic information they encode. This study focuses on the Italian NPN (noun-preposition-noun) constructional family, challenging some of the theoretical and methodological assumptions underlying previous experimental designs and extending this type of research to a lesser-investigated language. Contextual vector representations are extracted from BERT and used as input to layer-wise probing classifiers, systematically evaluating information encoded across the model's internal layers. The results shed light on the extent to which constructional form and meaning are reflected in contextual embeddings, contributing empirical evidence to the dialogue between constructionist theory and neural language modelling
Coconstructions in spoken data: UD annotation guidelines and first results
Mar 30, 2026The paper proposes annotation guidelines for syntactic dependencies that span across speaker turns - including collaborative coconstructions proper, wh-question answers, and backchannels - in spoken language treebanks within the Universal Dependencies framework. Two representations are proposed: a speaker-based representation following the segmentation into speech turns, and a dependency-based representation with dependencies across speech turns. New propositions are also put forward to distinguish between reformulations and repairs, and to promote elements in unfinished phrases.
Is Semi-Automatic Transcription Useful in Corpus Creation? Preliminary Considerations on the KIParla Corpus
Mar 17, 2026This paper analyses the implementation of Automatic Speech Recognition (ASR) into the transcription workflow of the KIParla corpus, a resource of spoken Italian. Through a two-phase experiment, 11 expert and novice transcribers produced both manual and ASR-assisted transcriptions of identical audio segments across three different types of conversation, which were subsequently analyzed through a combination of statistical modeling, word-level alignment and a series of annotation-based metrics. Results show that ASR-assisted workflows can increase transcription speed but do not consistently improve overall accuracy, with effects depending on multiple factors such as workflow configuration, conversation type and annotator experience. Analyses combining alignment-based metrics, descriptive statistics and statistical modeling provide a systematic framework to monitor transcription behavior across annotators and workflows. Despite limitations, ASR-assisted transcription, potentially supported by task-specific fine-tuning, could be integrated into the KIParla transcription workflow to accelerate corpus creation without compromising transcription quality.
Constraining constructions with WordNet: pros and cons for the semantic annotation of fillers in the Italian Constructicon
Jan 10, 2025
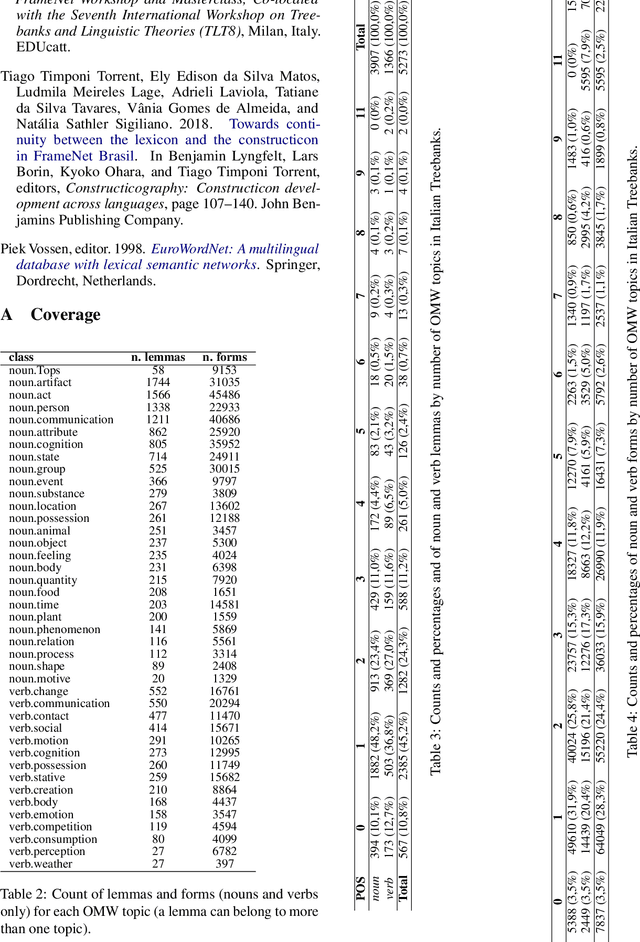
The paper discusses the role of WordNet-based semantic classification in the formalization of constructions, and more specifically in the semantic annotation of schematic fillers, in the Italian Constructicon. We outline how the Italian Constructicon project uses Open Multilingual WordNet topics to represent semantic features and constraints of constructions.
Annotating Constructions with UD: the experience of the Italian Constructicon
Nov 12, 2024The paper descirbes a first attempt of linking the Italian constructicon to UD resources
The KIPARLA Forest treebank of spoken Italian: an overview of initial design choices
Nov 10, 2024The paper presents an overview of initial design choices discussed towards the creation of a treebank for the Italian KIParla corpus
Did somebody say "Gest-IT"? A pilot exploration of multimodal data management
Oct 21, 2024



The paper presents a pilot exploration of the construction, management and analysis of a multimodal corpus. Through a three-layer annotation that provides orthographic, prosodic, and gestural transcriptions, the Gest-IT resource allows to investigate the variation of gesture-making patterns in conversations between sighted people and people with visual impairment. After discussing the transcription methods and technical procedures employed in our study, we propose a unified CoNLL-U corpus and indicate our future steps
Towards the first UD Treebank of Spoken Italian: the KIParla forest
Oct 06, 2024The present project endeavors to enrich the linguistic resources available for Italian by constructing a Universal Dependencies treebank for the KIParla corpus (Mauri et al., 2019, Ballar\`e et al., 2020), an existing and well known resource for spoken Italian.
CALaMo: a Constructionist Assessment of Language Models
Feb 07, 2023This paper presents a novel framework for evaluating Neural Language Models' linguistic abilities using a constructionist approach. Not only is the usage-based model in line with the underlying stochastic philosophy of neural architectures, but it also allows the linguist to keep meaning as a determinant factor in the analysis. We outline the framework and present two possible scenarios for its application.
A dissemination workshop for introducing young Italian students to NLP
May 14, 2021



We describe and make available the game-based material developed for a laboratory run at several Italian science festivals to popularize NLP among young students.