 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCALaMo: a Constructionist Assessment of Language Models
Feb 07, 2023This paper presents a novel framework for evaluating Neural Language Models' linguistic abilities using a constructionist approach. Not only is the usage-based model in line with the underlying stochastic philosophy of neural architectures, but it also allows the linguist to keep meaning as a determinant factor in the analysis. We outline the framework and present two possible scenarios for its application.
Novel Aficionados and Doppelgängers: a referential task for semantic representations of individual entities
Apr 20, 2021



In human semantic cognition, proper names (names which refer to individual entities) are harder to learn and retrieve than common nouns. This seems to be the case for machine learning algorithms too, but the linguistic and distributional reasons for this behaviour have not been investigated in depth so far. To tackle this issue, we show that the semantic distinction between proper names and common nouns is reflected in their linguistic distributions by employing an original task for distributional semantics, the Doppelg\"anger test, an extensive set of models, and a new dataset, the Novel Aficionados dataset. The results indicate that the distributional representations of different individual entities are less clearly distinguishable from each other than those of common nouns, an outcome which intriguingly mirrors human cognition.
Recurrent babbling: evaluating the acquisition of grammar from limited input data
Oct 09, 2020


Recurrent Neural Networks (RNNs) have been shown to capture various aspects of syntax from raw linguistic input. In most previous experiments, however, learning happens over unrealistic corpora, which do not reflect the type and amount of data a child would be exposed to. This paper remedies this state of affairs by training a Long Short-Term Memory network (LSTM) over a realistically sized subset of child-directed input. The behaviour of the network is analysed over time using a novel methodology which consists in quantifying the level of grammatical abstraction in the model's generated output (its "babbling"), compared to the language it has been exposed to. We show that the LSTM indeed abstracts new structuresas learning proceeds.
Pay Attention to Those Sets! Learning Quantification from Images
Apr 10, 2017
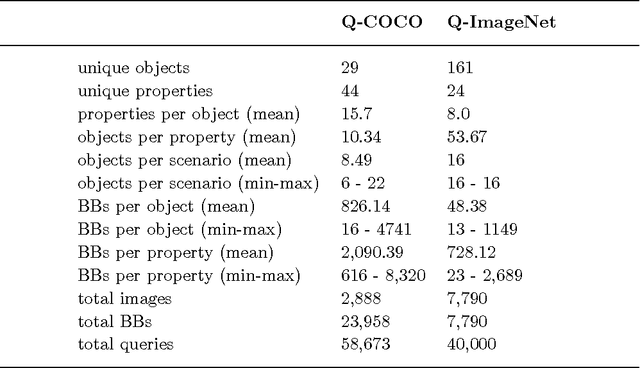

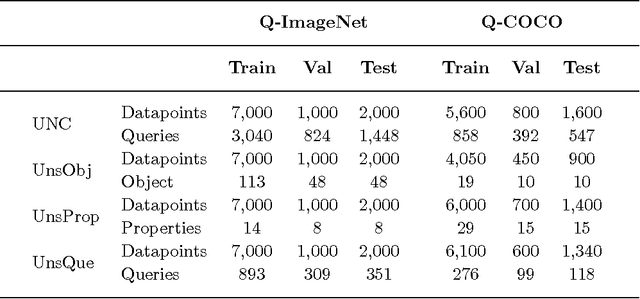
Major advances have recently been made in merging language and vision representations. But most tasks considered so far have confined themselves to the processing of objects and lexicalised relations amongst objects (content words). We know, however, that humans (even pre-school children) can abstract over raw data to perform certain types of higher-level reasoning, expressed in natural language by function words. A case in point is given by their ability to learn quantifiers, i.e. expressions like 'few', 'some' and 'all'. From formal semantics and cognitive linguistics, we know that quantifiers are relations over sets which, as a simplification, we can see as proportions. For instance, in 'most fish are red', most encodes the proportion of fish which are red fish. In this paper, we study how well current language and vision strategies model such relations. We show that state-of-the-art attention mechanisms coupled with a traditional linguistic formalisation of quantifiers gives best performance on the task. Additionally, we provide insights on the role of 'gist' representations in quantification. A 'logical' strategy to tackle the task would be to first obtain a numerosity estimation for the two involved sets and then compare their cardinalities. We however argue that precisely identifying the composition of the sets is not only beyond current state-of-the-art models but perhaps even detrimental to a task that is most efficiently performed by refining the approximate numerosity estimator of the system.