 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePay Attention to Those Sets! Learning Quantification from Images
Paper and Code

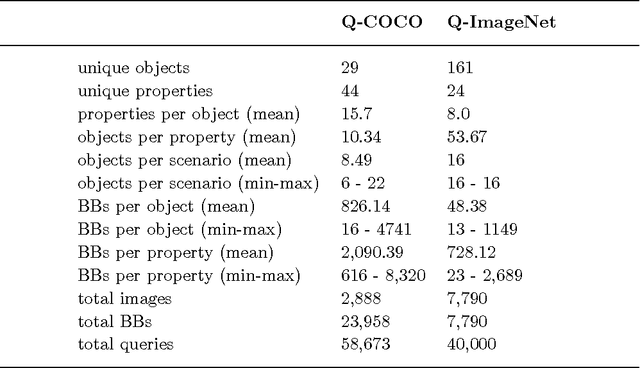

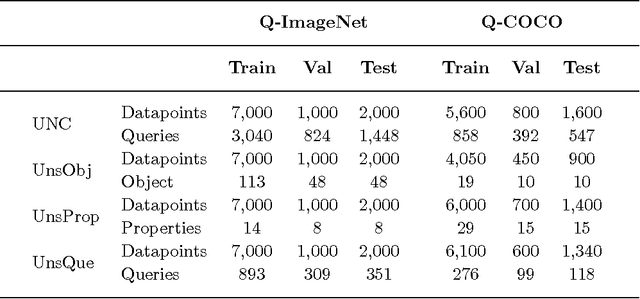
Major advances have recently been made in merging language and vision representations. But most tasks considered so far have confined themselves to the processing of objects and lexicalised relations amongst objects (content words). We know, however, that humans (even pre-school children) can abstract over raw data to perform certain types of higher-level reasoning, expressed in natural language by function words. A case in point is given by their ability to learn quantifiers, i.e. expressions like 'few', 'some' and 'all'. From formal semantics and cognitive linguistics, we know that quantifiers are relations over sets which, as a simplification, we can see as proportions. For instance, in 'most fish are red', most encodes the proportion of fish which are red fish. In this paper, we study how well current language and vision strategies model such relations. We show that state-of-the-art attention mechanisms coupled with a traditional linguistic formalisation of quantifiers gives best performance on the task. Additionally, we provide insights on the role of 'gist' representations in quantification. A 'logical' strategy to tackle the task would be to first obtain a numerosity estimation for the two involved sets and then compare their cardinalities. We however argue that precisely identifying the composition of the sets is not only beyond current state-of-the-art models but perhaps even detrimental to a task that is most efficiently performed by refining the approximate numerosity estimator of the system.