 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulating Identity, Propagating Bias: Abstraction and Stereotypes in LLM-Generated Text
Sep 10, 2025Persona-prompting is a growing strategy to steer LLMs toward simulating particular perspectives or linguistic styles through the lens of a specified identity. While this method is often used to personalize outputs, its impact on how LLMs represent social groups remains underexplored. In this paper, we investigate whether persona-prompting leads to different levels of linguistic abstraction - an established marker of stereotyping - when generating short texts linking socio-demographic categories with stereotypical or non-stereotypical attributes. Drawing on the Linguistic Expectancy Bias framework, we analyze outputs from six open-weight LLMs under three prompting conditions, comparing 11 persona-driven responses to those of a generic AI assistant. To support this analysis, we introduce Self-Stereo, a new dataset of self-reported stereotypes from Reddit. We measure abstraction through three metrics: concreteness, specificity, and negation. Our results highlight the limits of persona-prompting in modulating abstraction in language, confirming criticisms about the ecology of personas as representative of socio-demographic groups and raising concerns about the risk of propagating stereotypes even when seemingly evoking the voice of a marginalized group.
How Humans and LLMs Organize Conceptual Knowledge: Exploring Subordinate Categories in Italian
May 27, 2025People can categorize the same entity at multiple taxonomic levels, such as basic (bear), superordinate (animal), and subordinate (grizzly bear). While prior research has focused on basic-level categories, this study is the first attempt to examine the organization of categories by analyzing exemplars produced at the subordinate level. We present a new Italian psycholinguistic dataset of human-generated exemplars for 187 concrete words. We then use these data to evaluate whether textual and vision LLMs produce meaningful exemplars that align with human category organization across three key tasks: exemplar generation, category induction, and typicality judgment. Our findings show a low alignment between humans and LLMs, consistent with previous studies. However, their performance varies notably across different semantic domains. Ultimately, this study highlights both the promises and the constraints of using AI-generated exemplars to support psychological and linguistic research.
Composing or Not Composing? Towards Distributional Construction Grammars
Dec 10, 2024The mechanisms of comprehension during language processing remains an open question. Classically, building the meaning of a linguistic utterance is said to be incremental, step-by-step, based on a compositional process. However, many different works have shown for a long time that non-compositional phenomena are also at work. It is therefore necessary to propose a framework bringing together both approaches. We present in this paper an approach based on Construction Grammars and completing this framework in order to account for these different mechanisms. We propose first a formal definition of this framework by completing the feature structure representation proposed in Sign-Based Construction Grammars. In a second step, we present a general representation of the meaning based on the interaction of constructions, frames and events. This framework opens the door to a processing mechanism for building the meaning based on the notion of activation evaluated in terms of similarity and unification. This new approach integrates features from distributional semantics into the constructionist framework, leading to what we call Distributional Construction Grammars.
Annotating Constructions with UD: the experience of the Italian Constructicon
Nov 12, 2024The paper descirbes a first attempt of linking the Italian constructicon to UD resources
Word Ladders: A Mobile Application for Semantic Data Collection
Mar 29, 2024Word Ladders is a free mobile application for Android and iOS, developed for collecting linguistic data, specifically lists of words related to each other through semantic relations of categorical inclusion, within the Abstraction project (ERC-2021-STG-101039777). We hereby provide an overview of Word Ladders, explaining its game logic, motivation and expected results and applications to nlp tasks as well as to the investigation of cognitive scientific open questions
Event knowledge in large language models: the gap between the impossible and the unlikely
Dec 07, 2022



People constantly use language to learn about the world. Computational linguists have capitalized on this fact to build large language models (LLMs) that acquire co-occurrence-based knowledge from language corpora. LLMs achieve impressive performance on many tasks, but the robustness of their world knowledge has been questioned. Here, we ask: do LLMs acquire generalized knowledge about real-world events? Using curated sets of minimal sentence pairs (n=1215), we tested whether LLMs are more likely to generate plausible event descriptions compared to their implausible counterparts. We found that LLMs systematically distinguish possible and impossible events (The teacher bought the laptop vs. The laptop bought the teacher) but fall short of human performance when distinguishing likely and unlikely events (The nanny tutored the boy vs. The boy tutored the nanny). In follow-up analyses, we show that (i) LLM scores are driven by both plausibility and surface-level sentence features, (ii) LLMs generalize well across syntactic sentence variants (active vs passive) but less well across semantic sentence variants (synonymous sentences), (iii) some, but not all LLM deviations from ground-truth labels align with crowdsourced human judgments, and (iv) explicit event plausibility information emerges in middle LLM layers and remains high thereafter. Overall, our analyses reveal a gap in LLMs' event knowledge, highlighting their limitations as generalized knowledge bases. We conclude by speculating that the differential performance on impossible vs. unlikely events is not a temporary setback but an inherent property of LLMs, reflecting a fundamental difference between linguistic knowledge and world knowledge in intelligent systems.
Did the Cat Drink the Coffee? Challenging Transformers with Generalized Event Knowledge
Jul 22, 2021
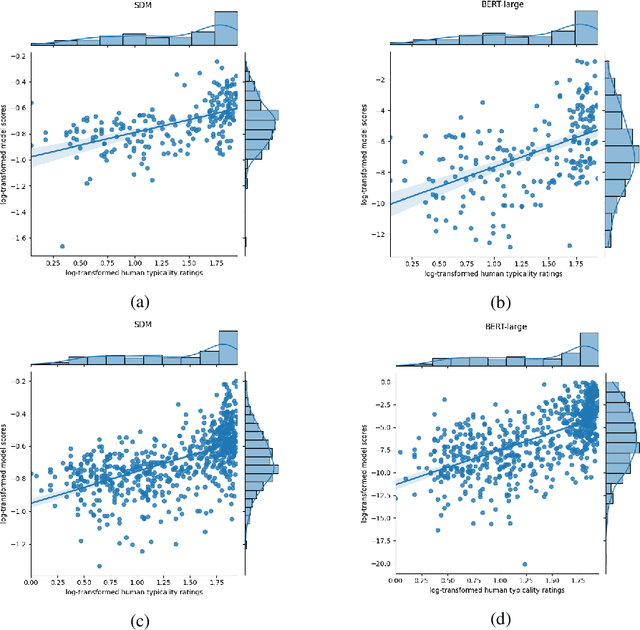

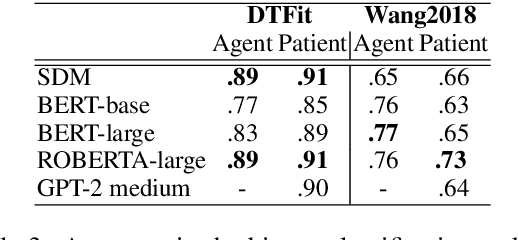
Prior research has explored the ability of computational models to predict a word semantic fit with a given predicate. While much work has been devoted to modeling the typicality relation between verbs and arguments in isolation, in this paper we take a broader perspective by assessing whether and to what extent computational approaches have access to the information about the typicality of entire events and situations described in language (Generalized Event Knowledge). Given the recent success of Transformers Language Models (TLMs), we decided to test them on a benchmark for the \textit{dynamic estimation of thematic fit}. The evaluation of these models was performed in comparison with SDM, a framework specifically designed to integrate events in sentence meaning representations, and we conducted a detailed error analysis to investigate which factors affect their behavior. Our results show that TLMs can reach performances that are comparable to those achieved by SDM. However, additional analysis consistently suggests that TLMs do not capture important aspects of event knowledge, and their predictions often depend on surface linguistic features, such as frequent words, collocations and syntactic patterns, thereby showing sub-optimal generalization abilities.
CogALex-V Shared Task: ROOT18
Nov 03, 2016
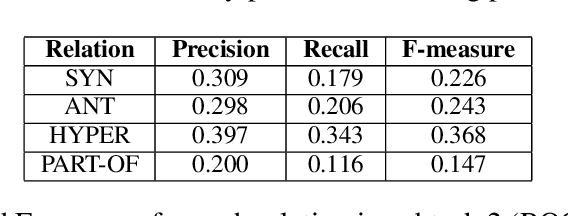

In this paper, we describe ROOT 18, a classifier using the scores of several unsupervised distributional measures as features to discriminate between semantically related and unrelated words, and then to classify the related pairs according to their semantic relation (i.e. synonymy, antonymy, hypernymy, part-whole meronymy). Our classifier participated in the CogALex-V Shared Task, showing a solid performance on the first subtask, but a poor performance on the second subtask. The low scores reported on the second subtask suggest that distributional measures are not sufficient to discriminate between multiple semantic relations at once.