 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposing or Not Composing? Towards Distributional Construction Grammars
Dec 10, 2024The mechanisms of comprehension during language processing remains an open question. Classically, building the meaning of a linguistic utterance is said to be incremental, step-by-step, based on a compositional process. However, many different works have shown for a long time that non-compositional phenomena are also at work. It is therefore necessary to propose a framework bringing together both approaches. We present in this paper an approach based on Construction Grammars and completing this framework in order to account for these different mechanisms. We propose first a formal definition of this framework by completing the feature structure representation proposed in Sign-Based Construction Grammars. In a second step, we present a general representation of the meaning based on the interaction of constructions, frames and events. This framework opens the door to a processing mechanism for building the meaning based on the notion of activation evaluated in terms of similarity and unification. This new approach integrates features from distributional semantics into the constructionist framework, leading to what we call Distributional Construction Grammars.
Did the Cat Drink the Coffee? Challenging Transformers with Generalized Event Knowledge
Jul 22, 2021
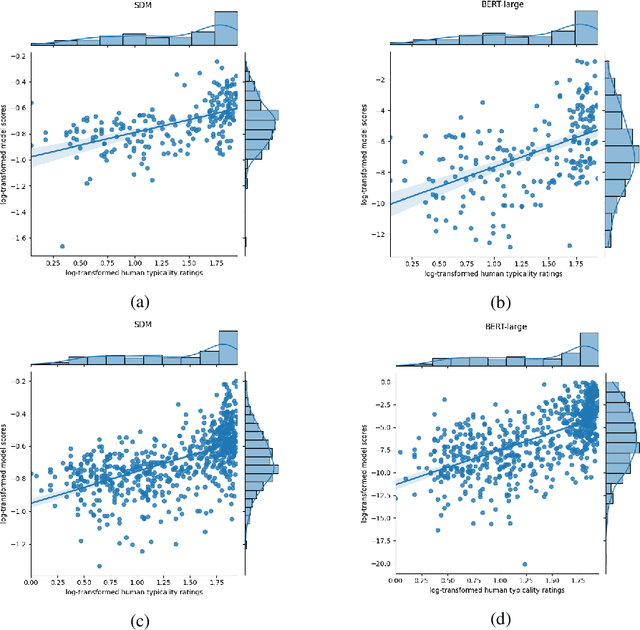

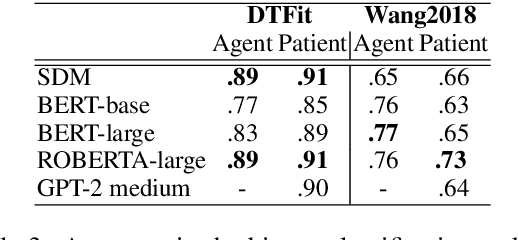
Prior research has explored the ability of computational models to predict a word semantic fit with a given predicate. While much work has been devoted to modeling the typicality relation between verbs and arguments in isolation, in this paper we take a broader perspective by assessing whether and to what extent computational approaches have access to the information about the typicality of entire events and situations described in language (Generalized Event Knowledge). Given the recent success of Transformers Language Models (TLMs), we decided to test them on a benchmark for the \textit{dynamic estimation of thematic fit}. The evaluation of these models was performed in comparison with SDM, a framework specifically designed to integrate events in sentence meaning representations, and we conducted a detailed error analysis to investigate which factors affect their behavior. Our results show that TLMs can reach performances that are comparable to those achieved by SDM. However, additional analysis consistently suggests that TLMs do not capture important aspects of event knowledge, and their predictions often depend on surface linguistic features, such as frequent words, collocations and syntactic patterns, thereby showing sub-optimal generalization abilities.
A Structured Distributional Model of Sentence Meaning and Processing
Jun 17, 2019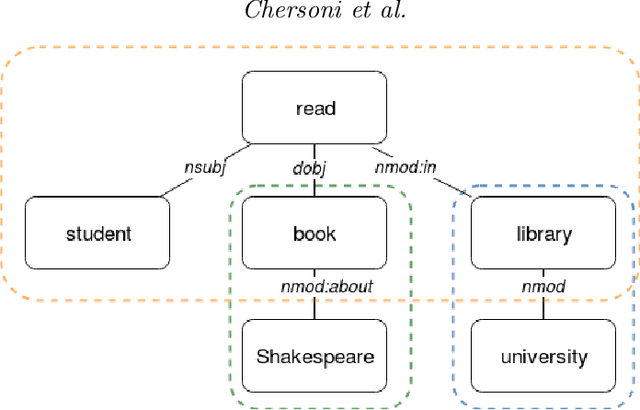

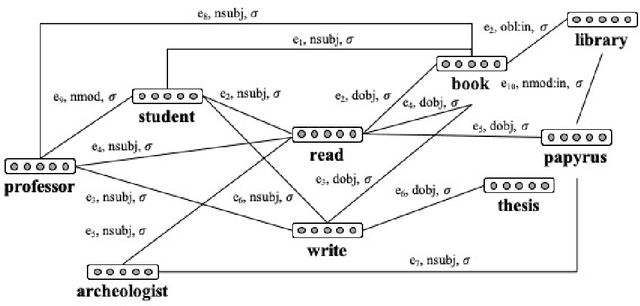
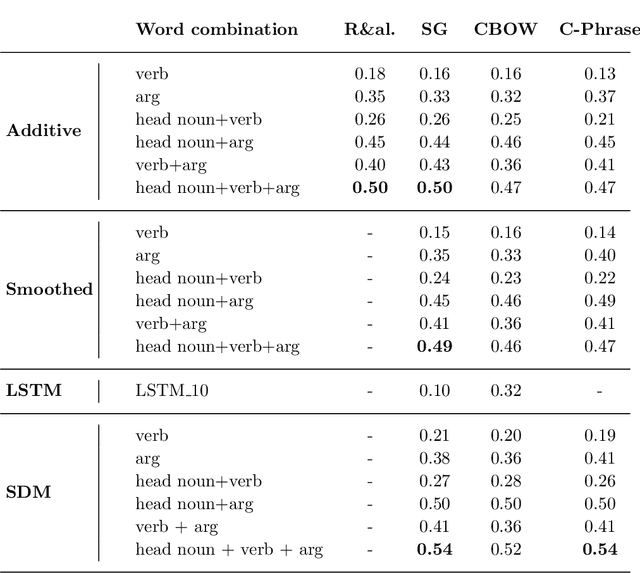
Most compositional distributional semantic models represent sentence meaning with a single vector. In this paper, we propose a Structured Distributional Model (SDM) that combines word embeddings with formal semantics and is based on the assumption that sentences represent events and situations. The semantic representation of a sentence is a formal structure derived from Discourse Representation Theory and containing distributional vectors. This structure is dynamically and incrementally built by integrating knowledge about events and their typical participants, as they are activated by lexical items. Event knowledge is modeled as a graph extracted from parsed corpora and encoding roles and relationships between participants that are represented as distributional vectors. SDM is grounded on extensive psycholinguistic research showing that generalized knowledge about events stored in semantic memory plays a key role in sentence comprehension. We evaluate SDM on two recently introduced compositionality datasets, and our results show that combining a simple compositional model with event knowledge constantly improves performances, even with different types of word embeddings.
Is Structure Necessary for Modeling Argument Expectations in Distributional Semantics?
Oct 03, 2017
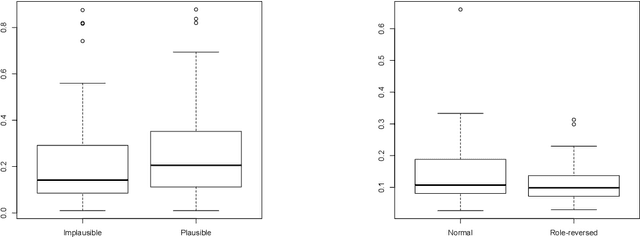
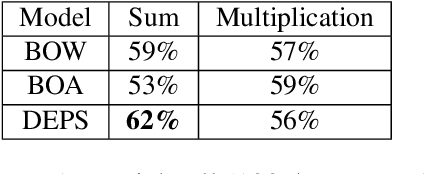

Despite the number of NLP studies dedicated to thematic fit estimation, little attention has been paid to the related task of composing and updating verb argument expectations. The few exceptions have mostly modeled this phenomenon with structured distributional models, implicitly assuming a similarly structured representation of events. Recent experimental evidence, however, suggests that human processing system could also exploit an unstructured "bag-of-arguments" type of event representation to predict upcoming input. In this paper, we re-implement a traditional structured model and adapt it to compare the different hypotheses concerning the degree of structure in our event knowledge, evaluating their relative performance in the task of the argument expectations update.
Measuring Thematic Fit with Distributional Feature Overlap
Jul 26, 2017
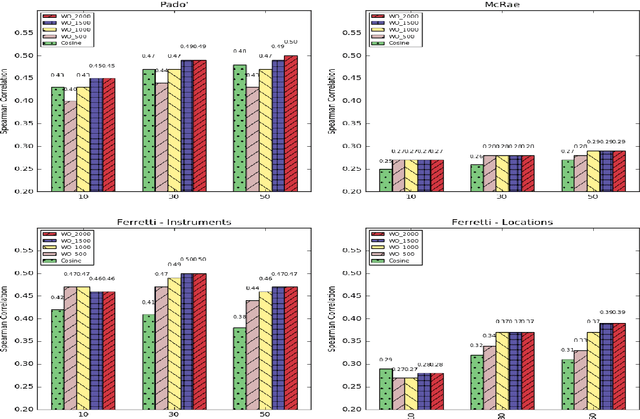
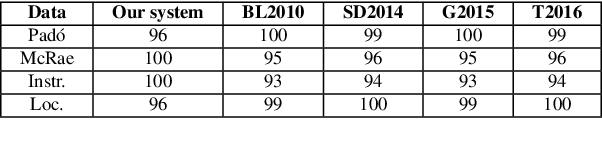
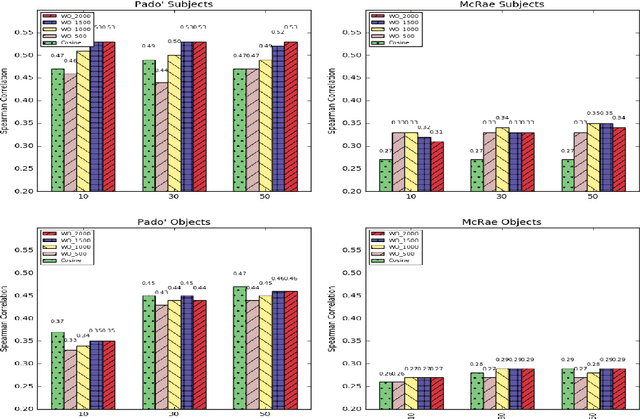
In this paper, we introduce a new distributional method for modeling predicate-argument thematic fit judgments. We use a syntax-based DSM to build a prototypical representation of verb-specific roles: for every verb, we extract the most salient second order contexts for each of its roles (i.e. the most salient dimensions of typical role fillers), and then we compute thematic fit as a weighted overlap between the top features of candidate fillers and role prototypes. Our experiments show that our method consistently outperforms a baseline re-implementing a state-of-the-art system, and achieves better or comparable results to those reported in the literature for the other unsupervised systems. Moreover, it provides an explicit representation of the features characterizing verb-specific semantic roles.
Representing Verbs with Rich Contexts: an Evaluation on Verb Similarity
Oct 05, 2016
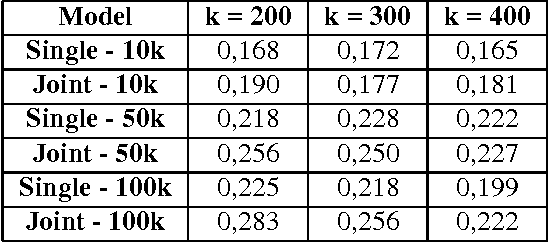
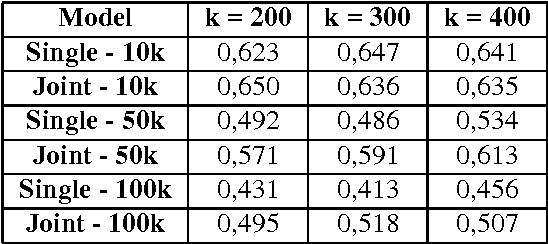
Several studies on sentence processing suggest that the mental lexicon keeps track of the mutual expectations between words. Current DSMs, however, represent context words as separate features, thereby loosing important information for word expectations, such as word interrelations. In this paper, we present a DSM that addresses this issue by defining verb contexts as joint syntactic dependencies. We test our representation in a verb similarity task on two datasets, showing that joint contexts achieve performances comparable to single dependencies or even better. Moreover, they are able to overcome the data sparsity problem of joint feature spaces, in spite of the limited size of our training corpus.
Testing APSyn against Vector Cosine on Similarity Estimation
Oct 05, 2016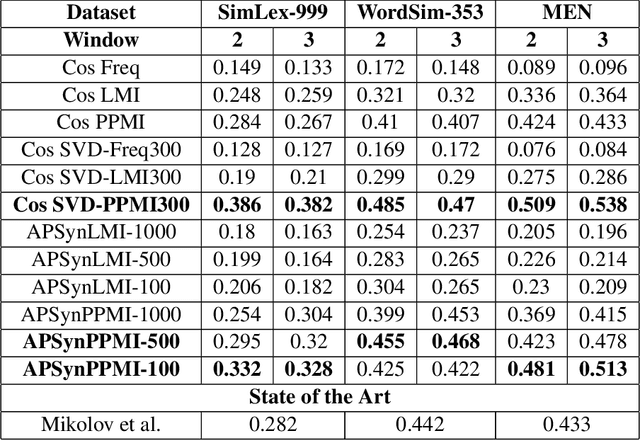
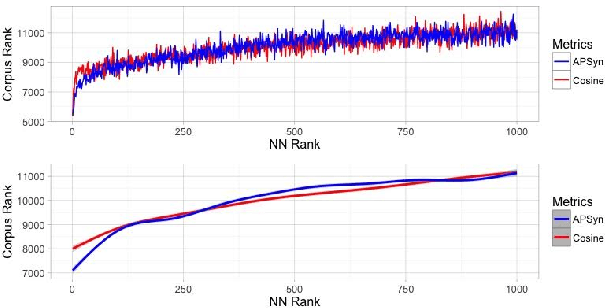
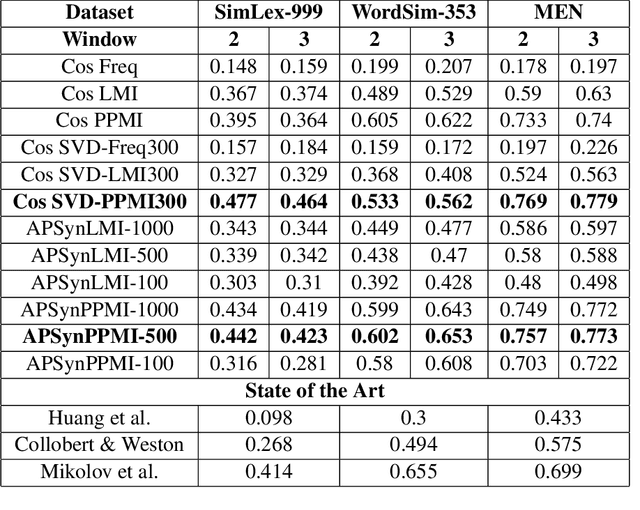
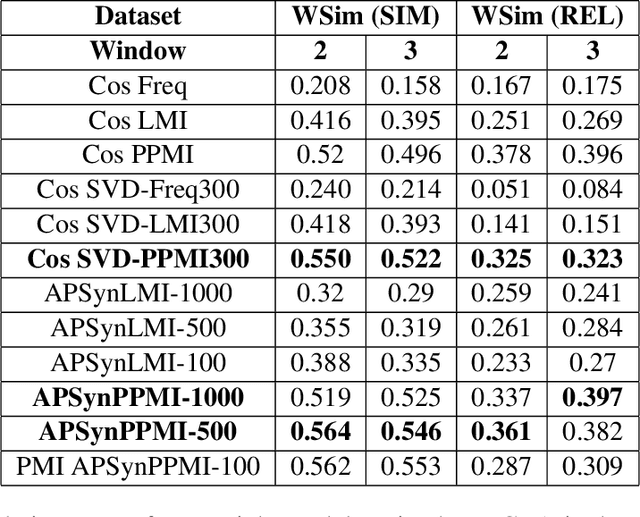
In Distributional Semantic Models (DSMs), Vector Cosine is widely used to estimate similarity between word vectors, although this measure was noticed to suffer from several shortcomings. The recent literature has proposed other methods which attempt to mitigate such biases. In this paper, we intend to investigate APSyn, a measure that computes the extent of the intersection between the most associated contexts of two target words, weighting it by context relevance. We evaluated this metric in a similarity estimation task on several popular test sets, and our results show that APSyn is in fact highly competitive, even with respect to the results reported in the literature for word embeddings. On top of it, APSyn addresses some of the weaknesses of Vector Cosine, performing well also on genuine similarity estimation.
Disambiguating with Controlled Disjunctions
Oct 14, 1997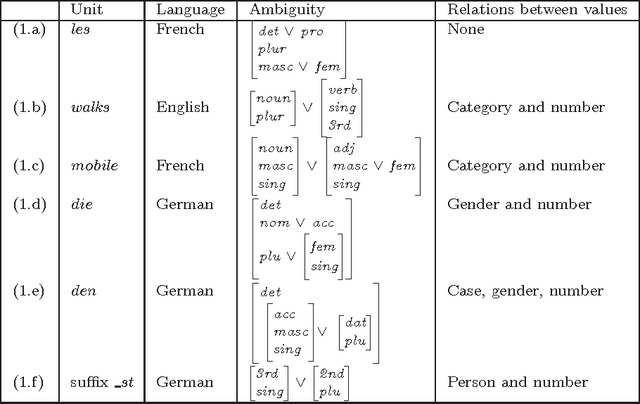
In this paper, we propose a disambiguating technique called controlled disjunctions. This extension of the so-called named disjunctions relies on the relations existing between feature values (covariation, control, etc.). We show that controlled disjunctions can implement different kind of ambiguities in a consistent and homogeneous way. We describe the integration of controlled disjunctions into a HPSG feature structure representation. Finally, we present a direct implementation by means of delayed evaluation and we develop an example within the functionnal programming paradigm.
* requires LaTeX2e, uses tree-dvips, avm
Active Constraints for a Direct Interpretation of HPSG
May 03, 1996
In this paper, we characterize the properties of a direct interpretation of HPSG and present the advantages of this approach. High-level programming languages constitute in this perspective an efficient solution: we show how a multi-paradigm approach, containing in particular constraint logic programming, offers mechanims close to that of the theory and preserves its fundamental properties. We take the example of LIFE and describe the implementation of the main HPSG mechanisms.
Constraint Logic Programming for Natural Language Processing
Apr 05, 1995This paper proposes an evaluation of the adequacy of the constraint logic programming paradigm for natural language processing. Theoretical aspects of this question have been discussed in several works. We adopt here a pragmatic point of view and our argumentation relies on concrete solutions. Using actual contraints (in the CLP sense) is neither easy nor direct. However, CLP can improve parsing techniques in several aspects such as concision, control, efficiency or direct representation of linguistic formalism. This discussion is illustrated by several examples and the presentation of an HPSG parser.