 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting the Market? A Large-Scale Meta-Analysis of GenAI in Finance NLP (2022-2025)
Sep 11, 2025



Large Language Models (LLMs) have rapidly reshaped financial NLP, enabling new tasks and driving a proliferation of datasets and diversification of data sources. Yet, this transformation has outpaced traditional surveys. In this paper, we present MetaGraph, a generalizable methodology for extracting knowledge graphs from scientific literature and analyzing them to obtain a structured, queryable view of research trends. We define an ontology for financial NLP research and apply an LLM-based extraction pipeline to 681 papers (2022-2025), enabling large-scale, data-driven analysis. MetaGraph reveals three key phases: early LLM adoption and task/dataset innovation; critical reflection on LLM limitations; and growing integration of peripheral techniques into modular systems. This structured view offers both practitioners and researchers a clear understanding of how financial NLP has evolved - highlighting emerging trends, shifting priorities, and methodological shifts-while also demonstrating a reusable approach for mapping scientific progress in other domains.
Did the Cat Drink the Coffee? Challenging Transformers with Generalized Event Knowledge
Jul 22, 2021
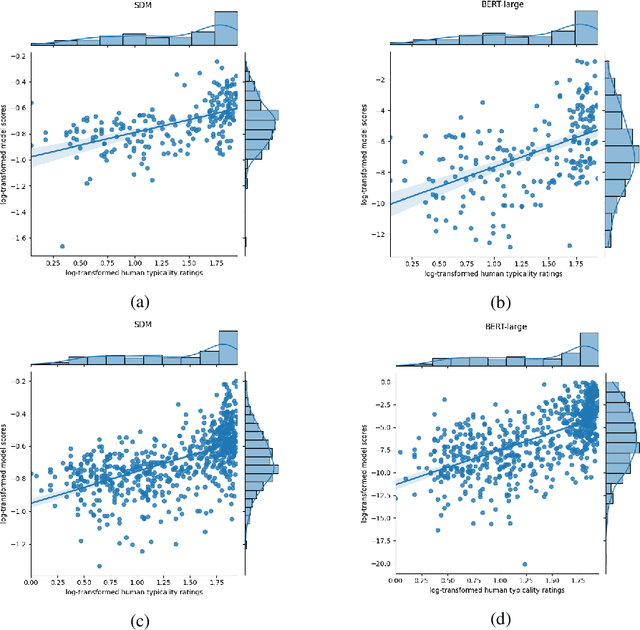

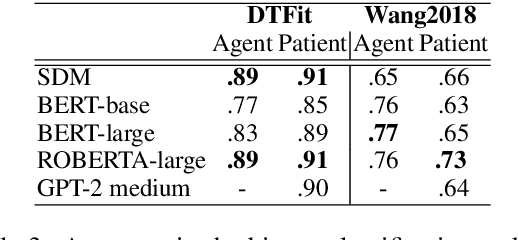
Prior research has explored the ability of computational models to predict a word semantic fit with a given predicate. While much work has been devoted to modeling the typicality relation between verbs and arguments in isolation, in this paper we take a broader perspective by assessing whether and to what extent computational approaches have access to the information about the typicality of entire events and situations described in language (Generalized Event Knowledge). Given the recent success of Transformers Language Models (TLMs), we decided to test them on a benchmark for the \textit{dynamic estimation of thematic fit}. The evaluation of these models was performed in comparison with SDM, a framework specifically designed to integrate events in sentence meaning representations, and we conducted a detailed error analysis to investigate which factors affect their behavior. Our results show that TLMs can reach performances that are comparable to those achieved by SDM. However, additional analysis consistently suggests that TLMs do not capture important aspects of event knowledge, and their predictions often depend on surface linguistic features, such as frequent words, collocations and syntactic patterns, thereby showing sub-optimal generalization abilities.