Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Measure of Word Similarity: How to Outperform Co-occurrence and Vector Cosine in VSMs
Paper and Code
Mar 30, 2016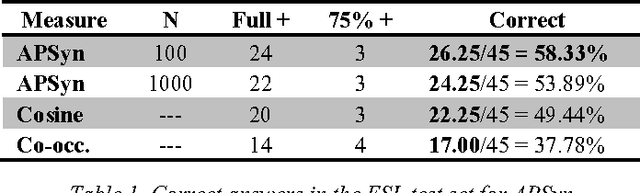
In this paper, we claim that vector cosine, which is generally considered among the most efficient unsupervised measures for identifying word similarity in Vector Space Models, can be outperformed by an unsupervised measure that calculates the extent of the intersection among the most mutually dependent contexts of the target words. To prove it, we describe and evaluate APSyn, a variant of the Average Precision that, without any optimization, outperforms the vector cosine and the co-occurrence on the standard ESL test set, with an improvement ranging between +9.00% and +17.98%, depending on the number of chosen top contexts.
* in AAAI 2016. arXiv admin note: substantial text overlap with
arXiv:1603.08701
View paper on