 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Analysis of Linguistic Features in Journal Articles of Different Academic Impacts with Feature Engineering Techniques
Nov 15, 2021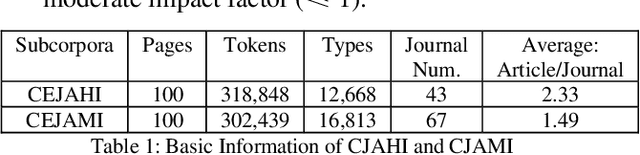

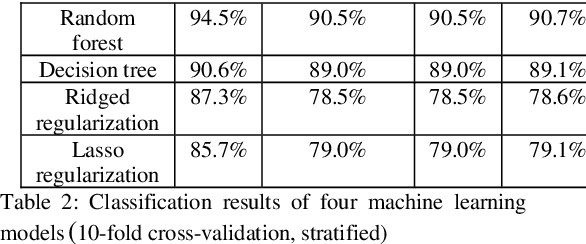
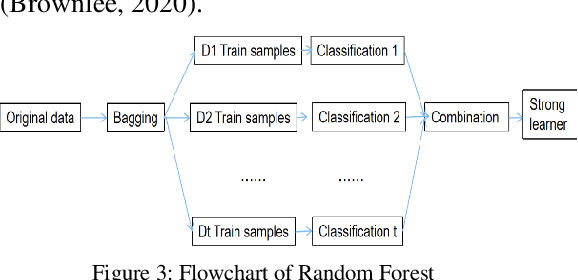
English research articles (RAs) are an essential genre in academia, so the attempts to employ NLP to assist the development of academic writing ability have received considerable attention in the last two decades. However, there has been no study employing feature engineering techniques to investigate the linguistic features of RAs of different academic impacts (i.e., the papers of high/moderate citation times published in the journals of high/moderate impact factors). This study attempts to extract micro-level linguistic features in high- and moderate-impact journal RAs, using feature engineering methods. We extracted 25 highly relevant features from the Corpus of English Journal Articles through feature selection methods. All papers in the corpus deal with COVID-19 medical empirical studies. The selected features were then validated of the classification performance in terms of consistency and accuracy through supervised machine learning methods. Results showed that 24 linguistic features such as the overlapping of content words between adjacent sentences, the use of third-person pronouns, auxiliary verbs, tense, emotional words provide consistent and accurate predictions for journal articles with different academic impacts. Lastly, the random forest model is shown to be the best model to fit the relationship between these 24 features and journal articles with high and moderate impacts. These findings can be used to inform academic writing courses and lay the foundation for developing automatic evaluation systems for L2 graduate students.