 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelta-SVD: Efficient Compression for Personalized Text-to-Image Models
Aug 23, 2025Personalized text-to-image models such as DreamBooth require fine-tuning large-scale diffusion backbones, resulting in significant storage overhead when maintaining many subject-specific models. We present Delta-SVD, a post-hoc, training-free compression method that targets the parameter weights update induced by DreamBooth fine-tuning. Our key observation is that these delta weights exhibit strong low-rank structure due to the sparse and localized nature of personalization. Delta-SVD first applies Singular Value Decomposition (SVD) to factorize the weight deltas, followed by an energy-based rank truncation strategy to balance compression efficiency and reconstruction fidelity. The resulting compressed models are fully plug-and-play and can be re-constructed on-the-fly during inference. Notably, the proposed approach is simple, efficient, and preserves the original model architecture. Experiments on a multiple subject dataset demonstrate that Delta-SVD achieves substantial compression with negligible loss in generation quality measured by CLIP score, SSIM and FID. Our method enables scalable and efficient deployment of personalized diffusion models, making it a practical solution for real-world applications that require storing and deploying large-scale subject customizations.
MTGR: Industrial-Scale Generative Recommendation Framework in Meituan
May 24, 2025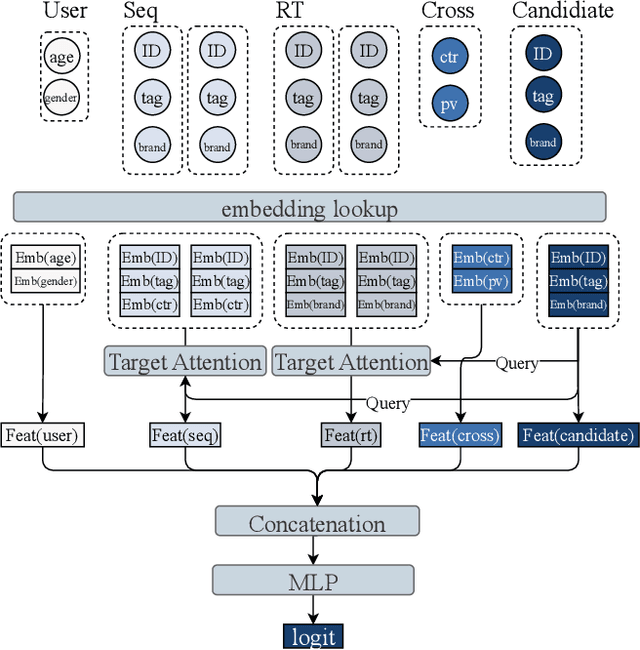
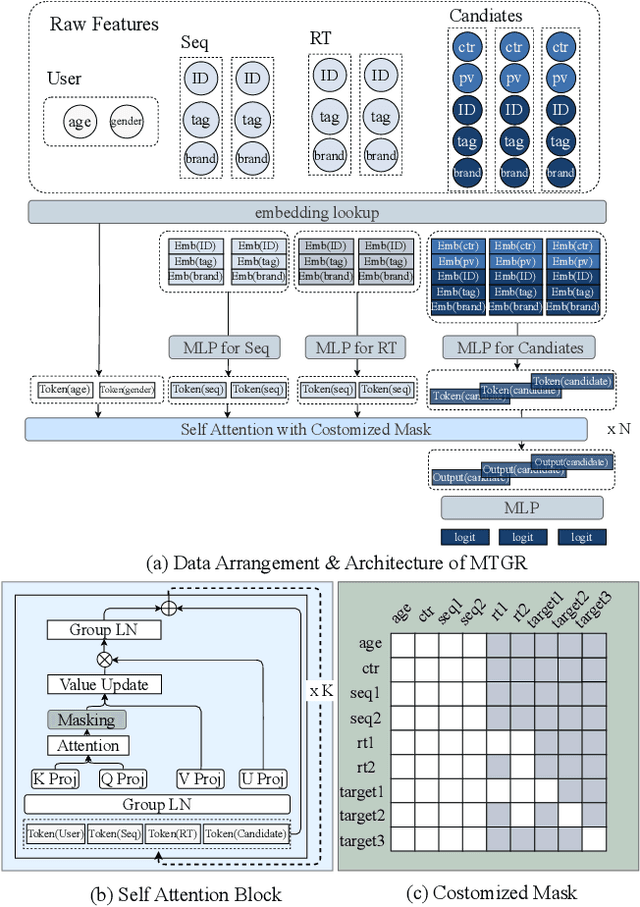

Scaling law has been extensively validated in many domains such as natural language processing and computer vision. In the recommendation system, recent work has adopted generative recommendations to achieve scalability, but their generative approaches require abandoning the carefully constructed cross features of traditional recommendation models. We found that this approach significantly degrades model performance, and scaling up cannot compensate for it at all. In this paper, we propose MTGR (Meituan Generative Recommendation) to address this issue. MTGR is modeling based on the HSTU architecture and can retain the original deep learning recommendation model (DLRM) features, including cross features. Additionally, MTGR achieves training and inference acceleration through user-level compression to ensure efficient scaling. We also propose Group-Layer Normalization (GLN) to enhance the performance of encoding within different semantic spaces and the dynamic masking strategy to avoid information leakage. We further optimize the training frameworks, enabling support for our models with 10 to 100 times computational complexity compared to the DLRM, without significant cost increases. MTGR achieved 65x FLOPs for single-sample forward inference compared to the DLRM model, resulting in the largest gain in nearly two years both offline and online. This breakthrough was successfully deployed on Meituan, the world's largest food delivery platform, where it has been handling the main traffic.
PaRa: Personalizing Text-to-Image Diffusion via Parameter Rank Reduction
Jun 09, 2024



Personalizing a large-scale pretrained Text-to-Image (T2I) diffusion model is challenging as it typically struggles to make an appropriate trade-off between its training data distribution and the target distribution, i.e., learning a novel concept with only a few target images to achieve personalization (aligning with the personalized target) while preserving text editability (aligning with diverse text prompts). In this paper, we propose PaRa, an effective and efficient Parameter Rank Reduction approach for T2I model personalization by explicitly controlling the rank of the diffusion model parameters to restrict its initial diverse generation space into a small and well-balanced target space. Our design is motivated by the fact that taming a T2I model toward a novel concept such as a specific art style implies a small generation space. To this end, by reducing the rank of model parameters during finetuning, we can effectively constrain the space of the denoising sampling trajectories towards the target. With comprehensive experiments, we show that PaRa achieves great advantages over existing finetuning approaches on single/multi-subject generation as well as single-image editing. Notably, compared to the prevailing fine-tuning technique LoRA, PaRa achieves better parameter efficiency (2x fewer learnable parameters) and much better target image alignment.
Apollonion: Profile-centric Dialog Agent
Apr 10, 2024



The emergence of Large Language Models (LLMs) has innovated the development of dialog agents. Specially, a well-trained LLM, as a central process unit, is capable of providing fluent and reasonable response for user's request. Besides, auxiliary tools such as external knowledge retrieval, personalized character for vivid response, short/long-term memory for ultra long context management are developed, completing the usage experience for LLM-based dialog agents. However, the above-mentioned techniques does not solve the issue of \textbf{personalization from user perspective}: agents response in a same fashion to different users, without consideration of their features, such as habits, interests and past experience. In another words, current implementation of dialog agents fail in ``knowing the user''. The capacity of well-description and representation of user is under development. In this work, we proposed a framework for dialog agent to incorporate user profiling (initialization, update): user's query and response is analyzed and organized into a structural user profile, which is latter served to provide personal and more precise response. Besides, we proposed a series of evaluation protocols for personalization: to what extend the response is personal to the different users. The framework is named as \method{}, inspired by inscription of ``Know Yourself'' in the temple of Apollo (also known as \method{}) in Ancient Greek. Few works have been conducted on incorporating personalization into LLM, \method{} is a pioneer work on guiding LLM's response to meet individuation via the application of dialog agents, with a set of evaluation methods for measurement in personalization.
Adversarial Defense by Latent Style Transformations
Jun 17, 2020


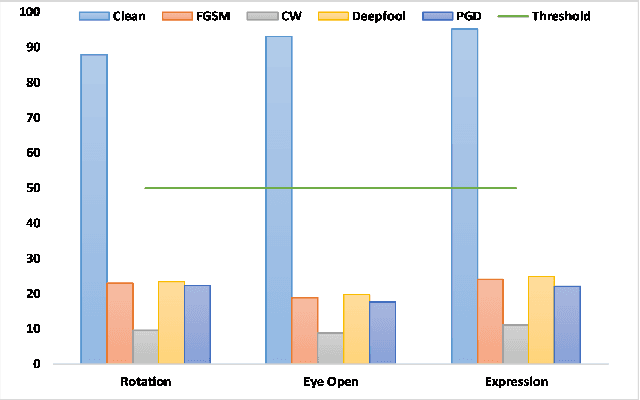
Machine learning models have demonstrated vulnerability to adversarial attacks, more specifically misclassification of adversarial examples. In this paper, we investigate an attack-agnostic defense against adversarial attacks on high-resolution images by detecting suspicious inputs. The intuition behind our approach is that the essential characteristics of a normal image are generally consistent with non-essential style transformations, e.g., slightly changing the facial expression of human portraits. In contrast, adversarial examples are generally sensitive to such transformations. In our approach to detect adversarial instances, we propose an in\underline{V}ertible \underline{A}utoencoder based on the \underline{S}tyleGAN2 generator via \underline{A}dversarial training (VASA) to inverse images to disentangled latent codes that reveal hierarchical styles. We then build a set of edited copies with non-essential style transformations by performing latent shifting and reconstruction, based on the correspondences between latent codes and style transformations. The classification-based consistency of these edited copies is used to distinguish adversarial instances.
Defending Adversarial Attacks via Semantic Feature Manipulation
Feb 03, 2020



Machine learning models have demonstrated vulnerability to adversarial attacks, more specifically misclassification of adversarial examples. In this paper, we propose a one-off and attack-agnostic Feature Manipulation (FM)-Defense to detect and purify adversarial examples in an interpretable and efficient manner. The intuition is that the classification result of a normal image is generally resistant to non-significant intrinsic feature changes, e.g., varying thickness of handwritten digits. In contrast, adversarial examples are sensitive to such changes since the perturbation lacks transferability. To enable manipulation of features, a combo-variational autoencoder is applied to learn disentangled latent codes that reveal semantic features. The resistance to classification change over the morphs, derived by varying and reconstructing latent codes, is used to detect suspicious inputs. Further, combo-VAE is enhanced to purify the adversarial examples with good quality by considering both class-shared and class-unique features. We empirically demonstrate the effectiveness of detection and the quality of purified instance. Our experiments on three datasets show that FM-Defense can detect nearly $100\%$ of adversarial examples produced by different state-of-the-art adversarial attacks. It achieves more than $99\%$ overall purification accuracy on the suspicious instances that close the manifold of normal examples.
OIAD: One-for-all Image Anomaly Detection with Disentanglement Learning
Jan 18, 2020



Anomaly detection aims to recognize samples with anomalous and unusual patterns with respect to a set of normal data, which is significant for numerous domain applications, e.g. in industrial inspection, medical imaging, and security enforcement. There are two key research challenges associated with existing anomaly detention approaches: (1) many of them perform well on low-dimensional problems however the performance on high-dimensional instances is limited, such as images; (2) many of them depend on often still rely on traditional supervised approaches and manual engineering of features, while the topic has not been fully explored yet using modern deep learning approaches, even when the well-label samples are limited. In this paper, we propose a One-for-all Image Anomaly Detection system (OIAD) based on disentangled learning using only clean samples. Our key insight is that the impact of small perturbation on the latent representation can be bounded for normal samples while anomaly images are usually outside such bounded intervals, called structure consistency. We implement this idea and evaluate its performance for anomaly detention. Our experiments with three datasets show that OIAD can detect over $90\%$ of anomalies while maintaining a high low false alarm rate. It can also detect suspicious samples from samples labeled as clean, coincided with what humans would deem unusual.
Backdoor Attacks against Transfer Learning with Pre-trained Deep Learning Models
Jan 10, 2020
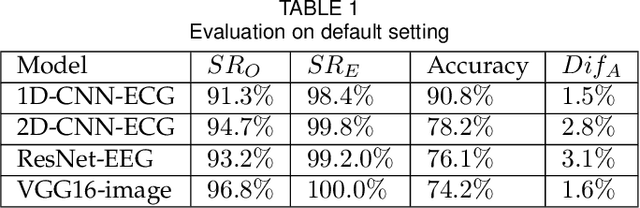


Transfer learning, that transfer the learned knowledge of pre-trained Teacher models over large datasets via fine-tuning, provides an effective solution for feasibly and fast customize accurate Student models. Many pre-trained Teacher models are publicly available and maintained by public platforms, increasing their vulnerability to backdoor attacks. In this paper, we demonstrate a backdoor threat to transfer learning tasks on both image and time-series data leveraging the knowledge of publicly accessible Teacher models, aimed at defeating three commonly-adopted defenses: pruning-based, retraining-based and input pre-processing-based defenses. Specifically, (A) ranking-based selection mechanism to speed up the backdoor trigger generation and perturbation process while defeating pruning-based and/or retraining-based defenses. (B) autoencoder-powered trigger generation is proposed to produce a robust trigger that can defeat the input pre-processing-based defense, while guaranteeing that selected neuron(s) can be significantly activated. (C) defense-aware retraining to generate the manipulated model using reverse-engineered model inputs. We use the real-world image and bioelectric signal analytics applications to demonstrate the power of our attack and conduct a comprehensive empirical analysis of the possible factors that affect the attack. The efficiency/effectiveness and feasibility/easiness of such attacks are validated by empirically evaluating the state-of-the-art image, Electroencephalography (EEG) and Electrocardiography (ECG) learning systems.
Generating Semantic Adversarial Examples via Feature Manipulation
Jan 06, 2020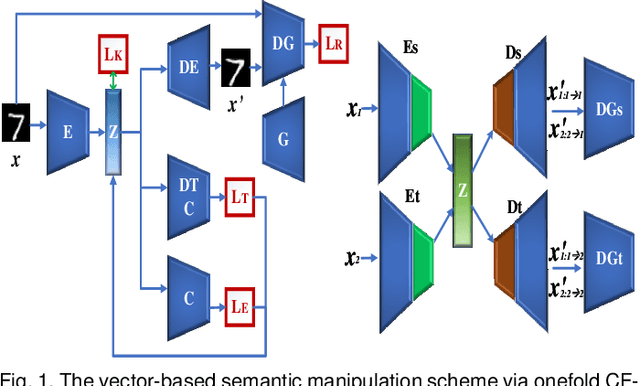



The vulnerability of deep neural networks to adversarial attacks has been widely demonstrated (e.g., adversarial example attacks). Traditional attacks perform unstructured pixel-wise perturbation to fool the classifier. An alternative approach is to have perturbations in the latent space. However, such perturbations are hard to control due to the lack of interpretability and disentanglement. In this paper, we propose a more practical adversarial attack by designing structured perturbation with semantic meanings. Our proposed technique manipulates the semantic attributes of images via the disentangled latent codes. The intuition behind our technique is that images in similar domains have some commonly shared but theme-independent semantic attributes, e.g. thickness of lines in handwritten digits, that can be bidirectionally mapped to disentangled latent codes. We generate adversarial perturbation by manipulating a single or a combination of these latent codes and propose two unsupervised semantic manipulation approaches: vector-based disentangled representation and feature map-based disentangled representation, in terms of the complexity of the latent codes and smoothness of the reconstructed images. We conduct extensive experimental evaluations on real-world image data to demonstrate the power of our attacks for black-box classifiers. We further demonstrate the existence of a universal, image-agnostic semantic adversarial example.
Learning to Prune Deep Neural Networks via Layer-wise Optimal Brain Surgeon
Nov 09, 2017



How to develop slim and accurate deep neural networks has become crucial for real- world applications, especially for those employed in embedded systems. Though previous work along this research line has shown some promising results, most existing methods either fail to significantly compress a well-trained deep network or require a heavy retraining process for the pruned deep network to re-boost its prediction performance. In this paper, we propose a new layer-wise pruning method for deep neural networks. In our proposed method, parameters of each individual layer are pruned independently based on second order derivatives of a layer-wise error function with respect to the corresponding parameters. We prove that the final prediction performance drop after pruning is bounded by a linear combination of the reconstructed errors caused at each layer. Therefore, there is a guarantee that one only needs to perform a light retraining process on the pruned network to resume its original prediction performance. We conduct extensive experiments on benchmark datasets to demonstrate the effectiveness of our pruning method compared with several state-of-the-art baseline methods.