 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeep the Lights On, Keep the Lengths in Check: Plug-In Adversarial Detection for Time-Series LLMs in Energy Forecasting
Dec 13, 2025Accurate time-series forecasting is increasingly critical for planning and operations in low-carbon power systems. Emerging time-series large language models (TS-LLMs) now deliver this capability at scale, requiring no task-specific retraining, and are quickly becoming essential components within the Internet-of-Energy (IoE) ecosystem. However, their real-world deployment is complicated by a critical vulnerability: adversarial examples (AEs). Detecting these AEs is challenging because (i) adversarial perturbations are optimized across the entire input sequence and exploit global temporal dependencies, which renders local detection methods ineffective, and (ii) unlike traditional forecasting models with fixed input dimensions, TS-LLMs accept sequences of variable length, increasing variability that complicates detection. To address these challenges, we propose a plug-in detection framework that capitalizes on the TS-LLM's own variable-length input capability. Our method uses sampling-induced divergence as a detection signal. Given an input sequence, we generate multiple shortened variants and detect AEs by measuring the consistency of their forecasts: Benign sequences tend to produce stable predictions under sampling, whereas adversarial sequences show low forecast similarity, because perturbations optimized for a full-length sequence do not transfer reliably to shorter, differently-structured subsamples. We evaluate our approach on three representative TS-LLMs (TimeGPT, TimesFM, and TimeLLM) across three energy datasets: ETTh2 (Electricity Transformer Temperature), NI (Hourly Energy Consumption), and Consumption (Hourly Electricity Consumption and Production). Empirical results confirm strong and robust detection performance across both black-box and white-box attack scenarios, highlighting its practicality as a reliable safeguard for TS-LLM forecasting in real-world energy systems.
MulVuln: Enhancing Pre-trained LMs with Shared and Language-Specific Knowledge for Multilingual Vulnerability Detection
Oct 05, 2025Software vulnerabilities (SVs) pose a critical threat to safety-critical systems, driving the adoption of AI-based approaches such as machine learning and deep learning for software vulnerability detection. Despite promising results, most existing methods are limited to a single programming language. This is problematic given the multilingual nature of modern software, which is often complex and written in multiple languages. Current approaches often face challenges in capturing both shared and language-specific knowledge of source code, which can limit their performance on diverse programming languages and real-world codebases. To address this gap, we propose MULVULN, a novel multilingual vulnerability detection approach that learns from source code across multiple languages. MULVULN captures both the shared knowledge that generalizes across languages and the language-specific knowledge that reflects unique coding conventions. By integrating these aspects, it achieves more robust and effective detection of vulnerabilities in real-world multilingual software systems. The rigorous and extensive experiments on the real-world and diverse REEF dataset, consisting of 4,466 CVEs with 30,987 patches across seven programming languages, demonstrate the superiority of MULVULN over thirteen effective and state-of-the-art baselines. Notably, MULVULN achieves substantially higher F1-score, with improvements ranging from 1.45% to 23.59% compared to the baseline methods.
Robust Anomaly Detection in O-RAN: Leveraging LLMs against Data Manipulation Attacks
Aug 11, 2025The introduction of 5G and the Open Radio Access Network (O-RAN) architecture has enabled more flexible and intelligent network deployments. However, the increased complexity and openness of these architectures also introduce novel security challenges, such as data manipulation attacks on the semi-standardised Shared Data Layer (SDL) within the O-RAN platform through malicious xApps. In particular, malicious xApps can exploit this vulnerability by introducing subtle Unicode-wise alterations (hypoglyphs) into the data that are being used by traditional machine learning (ML)-based anomaly detection methods. These Unicode-wise manipulations can potentially bypass detection and cause failures in anomaly detection systems based on traditional ML, such as AutoEncoders, which are unable to process hypoglyphed data without crashing. We investigate the use of Large Language Models (LLMs) for anomaly detection within the O-RAN architecture to address this challenge. We demonstrate that LLM-based xApps maintain robust operational performance and are capable of processing manipulated messages without crashing. While initial detection accuracy requires further improvements, our results highlight the robustness of LLMs to adversarial attacks such as hypoglyphs in input data. There is potential to use their adaptability through prompt engineering to further improve the accuracy, although this requires further research. Additionally, we show that LLMs achieve low detection latency (under 0.07 seconds), making them suitable for Near-Real-Time (Near-RT) RIC deployments.
Self-Adaptive and Robust Federated Spectrum Sensing without Benign Majority for Cellular Networks
Jul 16, 2025Advancements in wireless and mobile technologies, including 5G advanced and the envisioned 6G, are driving exponential growth in wireless devices. However, this rapid expansion exacerbates spectrum scarcity, posing a critical challenge. Dynamic spectrum allocation (DSA)--which relies on sensing and dynamically sharing spectrum--has emerged as an essential solution to address this issue. While machine learning (ML) models hold significant potential for improving spectrum sensing, their adoption in centralized ML-based DSA systems is limited by privacy concerns, bandwidth constraints, and regulatory challenges. To overcome these limitations, distributed ML-based approaches such as Federated Learning (FL) offer promising alternatives. This work addresses two key challenges in FL-based spectrum sensing (FLSS). First, the scarcity of labeled data for training FL models in practical spectrum sensing scenarios is tackled with a semi-supervised FL approach, combined with energy detection, enabling model training on unlabeled datasets. Second, we examine the security vulnerabilities of FLSS, focusing on the impact of data poisoning attacks. Our analysis highlights the shortcomings of existing majority-based defenses in countering such attacks. To address these vulnerabilities, we propose a novel defense mechanism inspired by vaccination, which effectively mitigates data poisoning attacks without relying on majority-based assumptions. Extensive experiments on both synthetic and real-world datasets validate our solutions, demonstrating that FLSS can achieve near-perfect accuracy on unlabeled datasets and maintain Byzantine robustness against both targeted and untargeted data poisoning attacks, even when a significant proportion of participants are malicious.
Security and Privacy of 6G Federated Learning-enabled Dynamic Spectrum Sharing
Jun 18, 2024



Spectrum sharing is increasingly vital in 6G wireless communication, facilitating dynamic access to unused spectrum holes. Recently, there has been a significant shift towards employing machine learning (ML) techniques for sensing spectrum holes. In this context, federated learning (FL)-enabled spectrum sensing technology has garnered wide attention, allowing for the construction of an aggregated ML model without disclosing the private spectrum sensing information of wireless user devices. However, the integrity of collaborative training and the privacy of spectrum information from local users have remained largely unexplored. This article first examines the latest developments in FL-enabled spectrum sharing for prospective 6G scenarios. It then identifies practical attack vectors in 6G to illustrate potential AI-powered security and privacy threats in these contexts. Finally, the study outlines future directions, including practical defense challenges and guidelines.
RAI4IoE: Responsible AI for Enabling the Internet of Energy
Sep 20, 2023



This paper plans to develop an Equitable and Responsible AI framework with enabling techniques and algorithms for the Internet of Energy (IoE), in short, RAI4IoE. The energy sector is going through substantial changes fueled by two key drivers: building a zero-carbon energy sector and the digital transformation of the energy infrastructure. We expect to see the convergence of these two drivers resulting in the IoE, where renewable distributed energy resources (DERs), such as electric cars, storage batteries, wind turbines and photovoltaics (PV), can be connected and integrated for reliable energy distribution by leveraging advanced 5G-6G networks and AI technology. This allows DER owners as prosumers to participate in the energy market and derive economic incentives. DERs are inherently asset-driven and face equitable challenges (i.e., fair, diverse and inclusive). Without equitable access, privileged individuals, groups and organizations can participate and benefit at the cost of disadvantaged groups. The real-time management of DER resources not only brings out the equity problem to the IoE, it also collects highly sensitive location, time, activity dependent data, which requires to be handled responsibly (e.g., privacy, security and safety), for AI-enhanced predictions, optimization and prioritization services, and automated management of flexible resources. The vision of our project is to ensure equitable participation of the community members and responsible use of their data in IoE so that it could reap the benefits of advances in AI to provide safe, reliable and sustainable energy services.
Email Summarization to Assist Users in Phishing Identification
Mar 24, 2022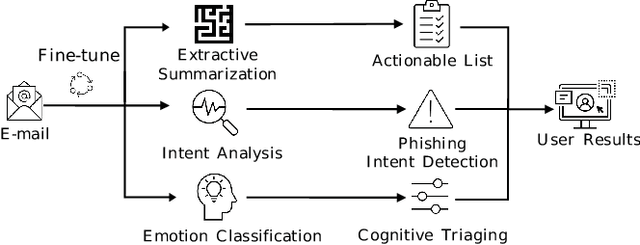

Cyber-phishing attacks recently became more precise, targeted, and tailored by training data to activate only in the presence of specific information or cues. They are adaptable to a much greater extent than traditional phishing detection. Hence, automated detection systems cannot always be 100% accurate, increasing the uncertainty around expected behavior when faced with a potential phishing email. On the other hand, human-centric defence approaches focus extensively on user training but face the difficulty of keeping users up to date with continuously emerging patterns. Therefore, advances in analyzing the content of an email in novel ways along with summarizing the most pertinent content to the recipients of emails is a prospective gateway to furthering how to combat these threats. Addressing this gap, this work leverages transformer-based machine learning to (i) analyze prospective psychological triggers, to (ii) detect possible malicious intent, and (iii) create representative summaries of emails. We then amalgamate this information and present it to the user to allow them to (i) easily decide whether the email is "phishy" and (ii) self-learn advanced malicious patterns.
Robust Training Using Natural Transformation
May 10, 2021
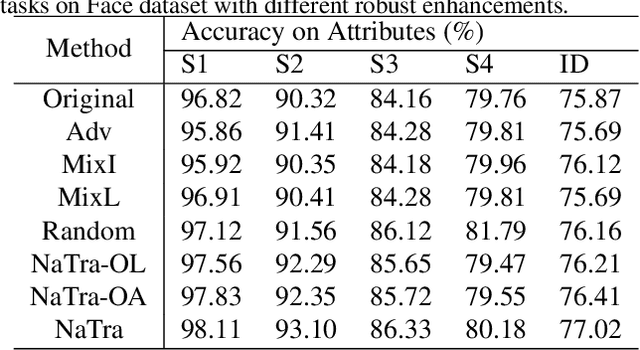

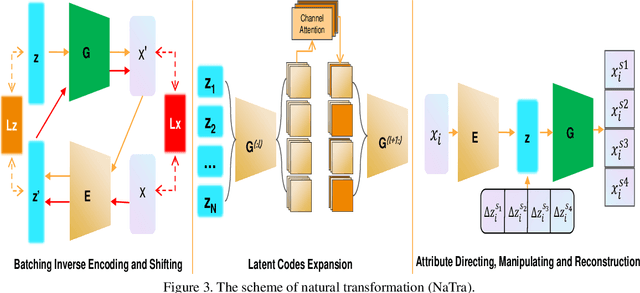
Previous robustness approaches for deep learning models such as data augmentation techniques via data transformation or adversarial training cannot capture real-world variations that preserve the semantics of the input, such as a change in lighting conditions. To bridge this gap, we present NaTra, an adversarial training scheme that is designed to improve the robustness of image classification algorithms. We target attributes of the input images that are independent of the class identification, and manipulate those attributes to mimic real-world natural transformations (NaTra) of the inputs, which are then used to augment the training dataset of the image classifier. Specifically, we apply \textit{Batch Inverse Encoding and Shifting} to map a batch of given images to corresponding disentangled latent codes of well-trained generative models. \textit{Latent Codes Expansion} is used to boost image reconstruction quality through the incorporation of extended feature maps. \textit{Unsupervised Attribute Directing and Manipulation} enables identification of the latent directions that correspond to specific attribute changes, and then produce interpretable manipulations of those attributes, thereby generating natural transformations to the input data. We demonstrate the efficacy of our scheme by utilizing the disentangled latent representations derived from well-trained GANs to mimic transformations of an image that are similar to real-world natural variations (such as lighting conditions or hairstyle), and train models to be invariant to these natural transformations. Extensive experiments show that our method improves generalization of classification models and increases its robustness to various real-world distortions
OCTOPUS: Overcoming Performance andPrivatization Bottlenecks in Distributed Learning
May 03, 2021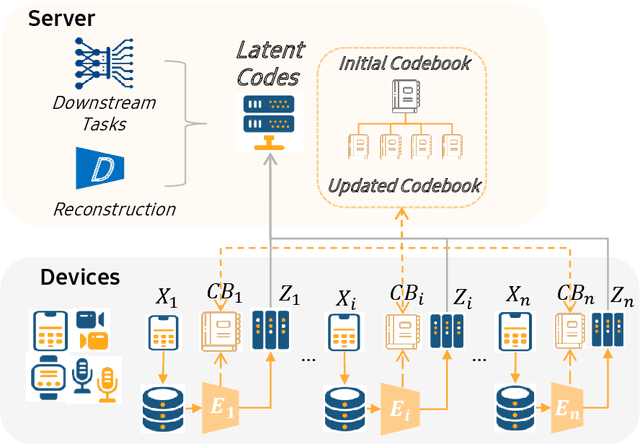

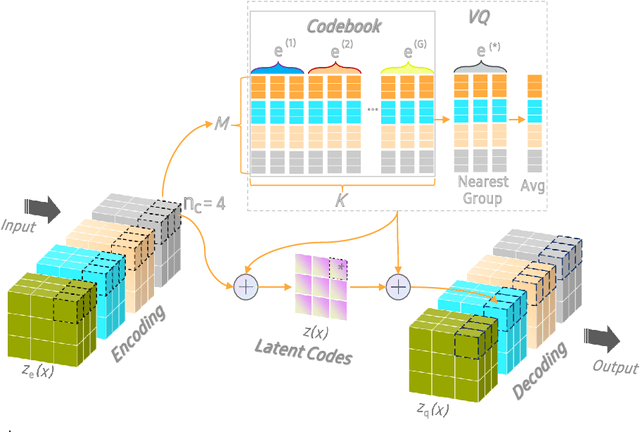
The diversity and quantity of the data warehousing, gathering data from distributed devices such as mobile phones, can enhance machine learning algorithms' success and robustness. Federated learning enables distributed participants to collaboratively learn a commonly-shared model while holding data locally. However, it is also faced with expensive communication and limitations due to the heterogeneity of distributed data sources and lack of access to global data. In this paper, we investigate a practical distributed learning scenario where multiple downstream tasks (e.g., classifiers) could be learned from dynamically-updated and non-iid distributed data sources, efficiently and providing local privatization. We introduce a new distributed learning scheme to address communication overhead via latent compression, leveraging global data while providing local privatization of local data without additional cost due to encryption or perturbation. This scheme divides the learning into (1) informative feature encoding, extracting and transmitting the latent space compressed representation features of local data at each node to address communication overhead; (2) downstream tasks centralized at the server using the encoded codes gathered from each node to address computing and storage overhead. Besides, a disentanglement strategy is applied to address the privatization of sensitive components of local data. Extensive experiments are conducted on image and speech datasets. The results demonstrate that downstream tasks on the compact latent representations can achieve comparable accuracy to centralized learning with the privatization of local data.
Adversarial Defense by Latent Style Transformations
Jun 17, 2020


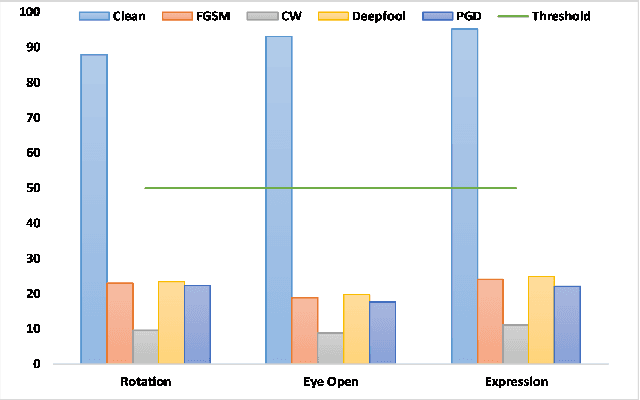
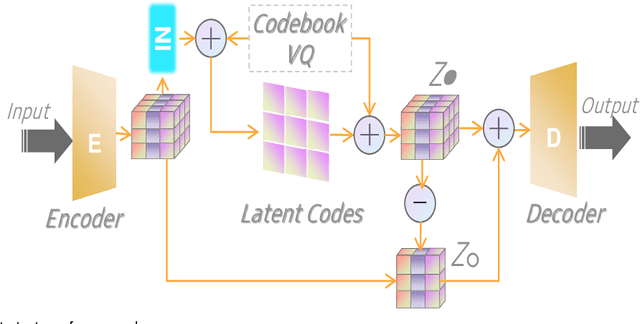
Machine learning models have demonstrated vulnerability to adversarial attacks, more specifically misclassification of adversarial examples. In this paper, we investigate an attack-agnostic defense against adversarial attacks on high-resolution images by detecting suspicious inputs. The intuition behind our approach is that the essential characteristics of a normal image are generally consistent with non-essential style transformations, e.g., slightly changing the facial expression of human portraits. In contrast, adversarial examples are generally sensitive to such transformations. In our approach to detect adversarial instances, we propose an in\underline{V}ertible \underline{A}utoencoder based on the \underline{S}tyleGAN2 generator via \underline{A}dversarial training (VASA) to inverse images to disentangled latent codes that reveal hierarchical styles. We then build a set of edited copies with non-essential style transformations by performing latent shifting and reconstruction, based on the correspondences between latent codes and style transformations. The classification-based consistency of these edited copies is used to distinguish adversarial instances.