 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Semantic Adversarial Examples via Feature Manipulation
Paper and Code
Jan 06, 2020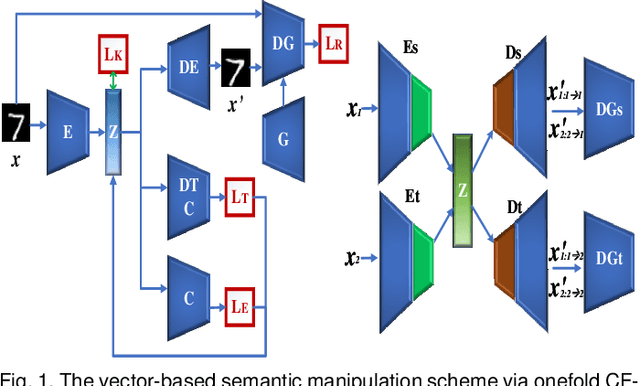



The vulnerability of deep neural networks to adversarial attacks has been widely demonstrated (e.g., adversarial example attacks). Traditional attacks perform unstructured pixel-wise perturbation to fool the classifier. An alternative approach is to have perturbations in the latent space. However, such perturbations are hard to control due to the lack of interpretability and disentanglement. In this paper, we propose a more practical adversarial attack by designing structured perturbation with semantic meanings. Our proposed technique manipulates the semantic attributes of images via the disentangled latent codes. The intuition behind our technique is that images in similar domains have some commonly shared but theme-independent semantic attributes, e.g. thickness of lines in handwritten digits, that can be bidirectionally mapped to disentangled latent codes. We generate adversarial perturbation by manipulating a single or a combination of these latent codes and propose two unsupervised semantic manipulation approaches: vector-based disentangled representation and feature map-based disentangled representation, in terms of the complexity of the latent codes and smoothness of the reconstructed images. We conduct extensive experimental evaluations on real-world image data to demonstrate the power of our attacks for black-box classifiers. We further demonstrate the existence of a universal, image-agnostic semantic adversarial example.