 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Defense by Latent Style Transformations
Paper and Code
Jun 17, 2020


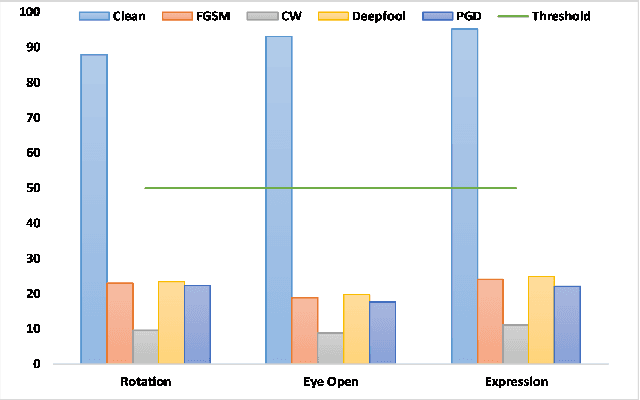
Machine learning models have demonstrated vulnerability to adversarial attacks, more specifically misclassification of adversarial examples. In this paper, we investigate an attack-agnostic defense against adversarial attacks on high-resolution images by detecting suspicious inputs. The intuition behind our approach is that the essential characteristics of a normal image are generally consistent with non-essential style transformations, e.g., slightly changing the facial expression of human portraits. In contrast, adversarial examples are generally sensitive to such transformations. In our approach to detect adversarial instances, we propose an in\underline{V}ertible \underline{A}utoencoder based on the \underline{S}tyleGAN2 generator via \underline{A}dversarial training (VASA) to inverse images to disentangled latent codes that reveal hierarchical styles. We then build a set of edited copies with non-essential style transformations by performing latent shifting and reconstruction, based on the correspondences between latent codes and style transformations. The classification-based consistency of these edited copies is used to distinguish adversarial instances.