 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Attention Patterns Exist: A Unifying Temporal Perspective Analysis
Jan 29, 2026Attention patterns play a crucial role in both training and inference of large language models (LLMs). Prior works have identified individual patterns such as retrieval heads, sink heads, and diagonal traces, yet these observations remain fragmented and lack a unifying explanation. To bridge this gap, we introduce \textbf{Temporal Attention Pattern Predictability Analysis (TAPPA), a unifying framework that explains diverse attention patterns by analyzing their underlying mathematical formulations} from a temporally continuous perspective. TAPPA both deepens the understanding of attention behavior and guides inference acceleration approaches. Specifically, TAPPA characterizes attention patterns as predictable patterns with clear regularities and unpredictable patterns that appear effectively random. Our analysis further reveals that this distinction can be explained by the degree of query self-similarity along the temporal dimension. Focusing on the predictable patterns, we further provide a detailed mathematical analysis of three representative cases through the joint effect of queries, keys, and Rotary Positional Embeddings (RoPE). We validate TAPPA by applying its insights to KV cache compression and LLM pruning tasks. Across these tasks, a simple metric motivated by TAPPA consistently improves performance over baseline methods. The code is available at https://github.com/MIRALab-USTC/LLM-TAPPA.
Top 10 Open Challenges Steering the Future of Diffusion Language Model and Its Variants
Jan 20, 2026The paradigm of Large Language Models (LLMs) is currently defined by auto-regressive (AR) architectures, which generate text through a sequential ``brick-by-brick'' process. Despite their success, AR models are inherently constrained by a causal bottleneck that limits global structural foresight and iterative refinement. Diffusion Language Models (DLMs) offer a transformative alternative, conceptualizing text generation as a holistic, bidirectional denoising process akin to a sculptor refining a masterpiece. However, the potential of DLMs remains largely untapped as they are frequently confined within AR-legacy infrastructures and optimization frameworks. In this Perspective, we identify ten fundamental challenges ranging from architectural inertia and gradient sparsity to the limitations of linear reasoning that prevent DLMs from reaching their ``GPT-4 moment''. We propose a strategic roadmap organized into four pillars: foundational infrastructure, algorithmic optimization, cognitive reasoning, and unified multimodal intelligence. By shifting toward a diffusion-native ecosystem characterized by multi-scale tokenization, active remasking, and latent thinking, we can move beyond the constraints of the causal horizon. We argue that this transition is essential for developing next-generation AI capable of complex structural reasoning, dynamic self-correction, and seamless multimodal integration.
Pangu Light: Weight Re-Initialization for Pruning and Accelerating LLMs
May 26, 2025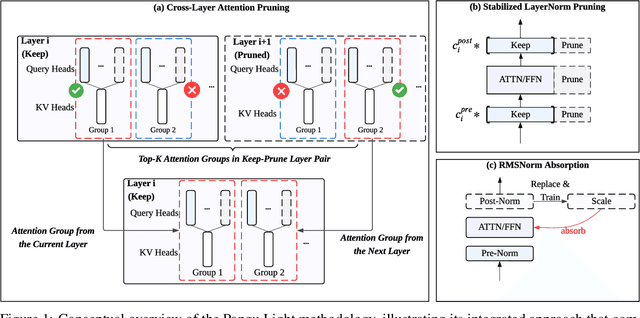

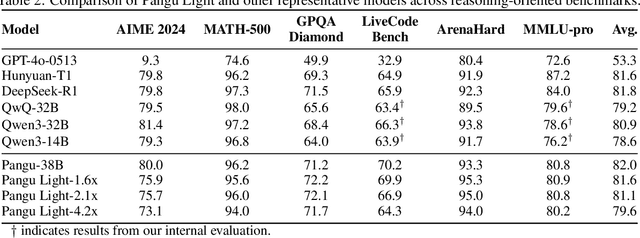
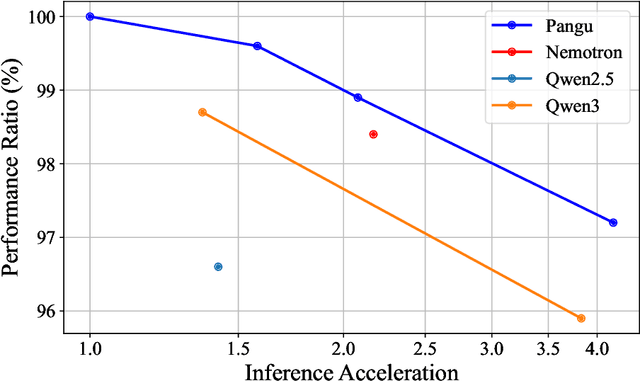
Large Language Models (LLMs) deliver state-of-the-art capabilities across numerous tasks, but their immense size and inference costs pose significant computational challenges for practical deployment. While structured pruning offers a promising avenue for model compression, existing methods often struggle with the detrimental effects of aggressive, simultaneous width and depth reductions, leading to substantial performance degradation. This paper argues that a critical, often overlooked, aspect in making such aggressive joint pruning viable is the strategic re-initialization and adjustment of remaining weights to improve the model post-pruning training accuracies. We introduce Pangu Light, a framework for LLM acceleration centered around structured pruning coupled with novel weight re-initialization techniques designed to address this ``missing piece''. Our framework systematically targets multiple axes, including model width, depth, attention heads, and RMSNorm, with its effectiveness rooted in novel re-initialization methods like Cross-Layer Attention Pruning (CLAP) and Stabilized LayerNorm Pruning (SLNP) that mitigate performance drops by providing the network a better training starting point. Further enhancing efficiency, Pangu Light incorporates specialized optimizations such as absorbing Post-RMSNorm computations and tailors its strategies to Ascend NPU characteristics. The Pangu Light models consistently exhibit a superior accuracy-efficiency trade-off, outperforming prominent baseline pruning methods like Nemotron and established LLMs like Qwen3 series. For instance, on Ascend NPUs, Pangu Light-32B's 81.6 average score and 2585 tokens/s throughput exceed Qwen3-32B's 80.9 average score and 2225 tokens/s.
HyperTree Planning: Enhancing LLM Reasoning via Hierarchical Thinking
May 05, 2025Recent advancements have significantly enhanced the performance of large language models (LLMs) in tackling complex reasoning tasks, achieving notable success in domains like mathematical and logical reasoning. However, these methods encounter challenges with complex planning tasks, primarily due to extended reasoning steps, diverse constraints, and the challenge of handling multiple distinct sub-tasks. To address these challenges, we propose HyperTree Planning (HTP), a novel reasoning paradigm that constructs hypertree-structured planning outlines for effective planning. The hypertree structure enables LLMs to engage in hierarchical thinking by flexibly employing the divide-and-conquer strategy, effectively breaking down intricate reasoning steps, accommodating diverse constraints, and managing multiple distinct sub-tasks in a well-organized manner. We further introduce an autonomous planning framework that completes the planning process by iteratively refining and expanding the hypertree-structured planning outlines. Experiments demonstrate the effectiveness of HTP, achieving state-of-the-art accuracy on the TravelPlanner benchmark with Gemini-1.5-Pro, resulting in a 3.6 times performance improvement over o1-preview.
Accelerating Large Language Model Reasoning via Speculative Search
May 03, 2025Tree-search-based reasoning methods have significantly enhanced the reasoning capability of large language models (LLMs) by facilitating the exploration of multiple intermediate reasoning steps, i.e., thoughts. However, these methods suffer from substantial inference latency, as they have to generate numerous reasoning thoughts, severely limiting LLM applicability. To address this challenge, we propose a novel Speculative Search (SpecSearch) framework that significantly accelerates LLM reasoning by optimizing thought generation. Specifically, SpecSearch utilizes a small model to strategically collaborate with a large model at both thought and token levels, efficiently generating high-quality reasoning thoughts. The major pillar of SpecSearch is a novel quality-preserving rejection mechanism, which effectively filters out thoughts whose quality falls below that of the large model's outputs. Moreover, we show that SpecSearch preserves comparable reasoning quality to the large model. Experiments on both the Qwen and Llama models demonstrate that SpecSearch significantly outperforms state-of-the-art approaches, achieving up to 2.12$\times$ speedup with comparable reasoning quality.
IB-Net: Initial Branch Network for Variable Decision in Boolean Satisfiability
Mar 06, 2024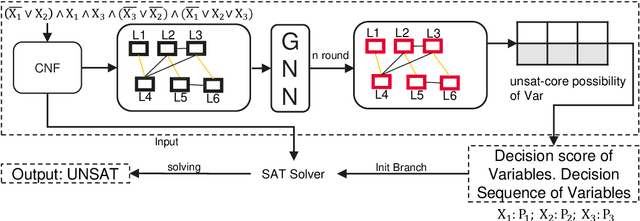
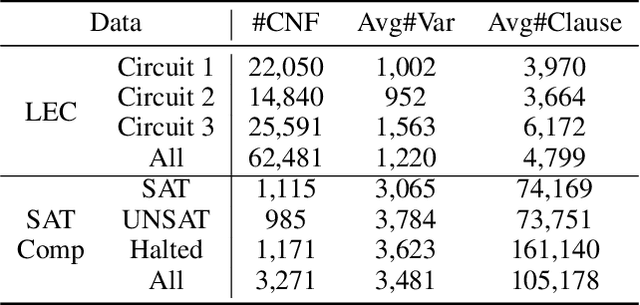
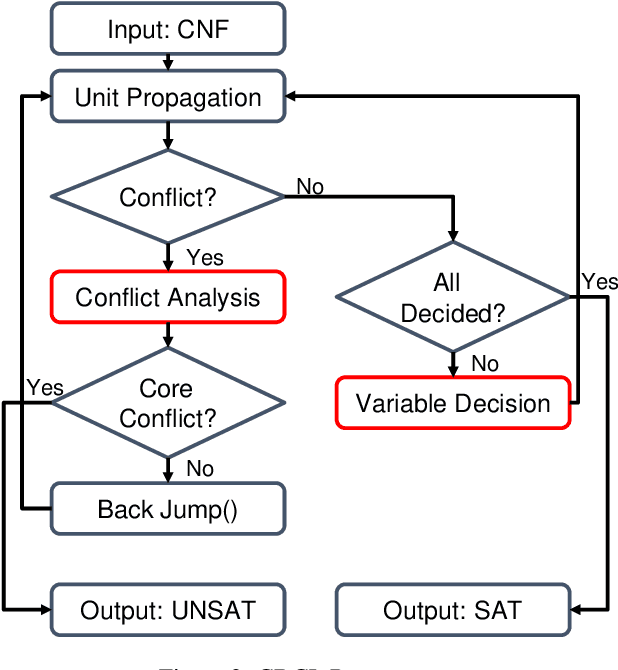
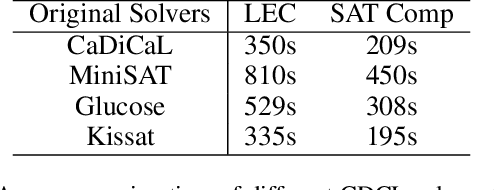
Boolean Satisfiability problems are vital components in Electronic Design Automation, particularly within the Logic Equivalence Checking process. Currently, SAT solvers are employed for these problems and neural network is tried as assistance to solvers. However, as SAT problems in the LEC context are distinctive due to their predominantly unsatisfiability nature and a substantial proportion of UNSAT-core variables, existing neural network assistance has proven unsuccessful in this specialized domain. To tackle this challenge, we propose IB-Net, an innovative framework utilizing graph neural networks and novel graph encoding techniques to model unsatisfiable problems and interact with state-of-the-art solvers. Extensive evaluations across solvers and datasets demonstrate IB-Net's acceleration, achieving an average runtime speedup of 5.0% on industrial data and 8.3% on SAT competition data empirically. This breakthrough advances efficient solving in LEC workflows.
Unsupervised prototype learning in an associative-memory network
Jul 25, 2017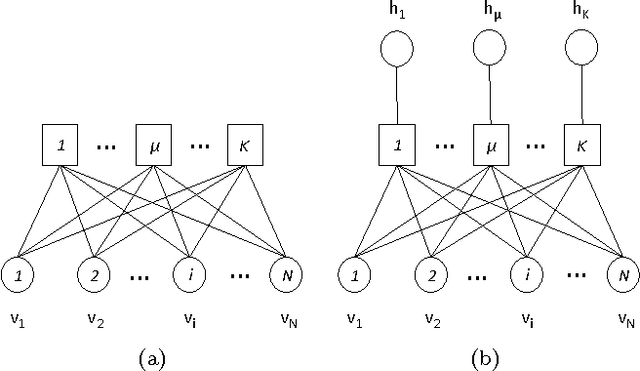
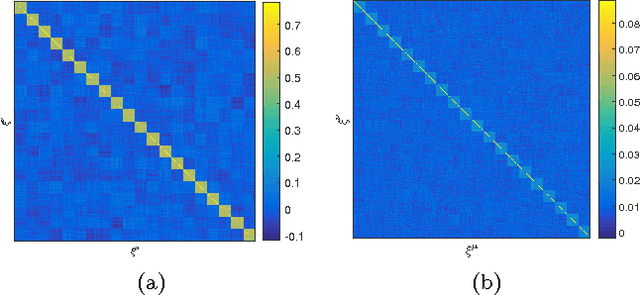
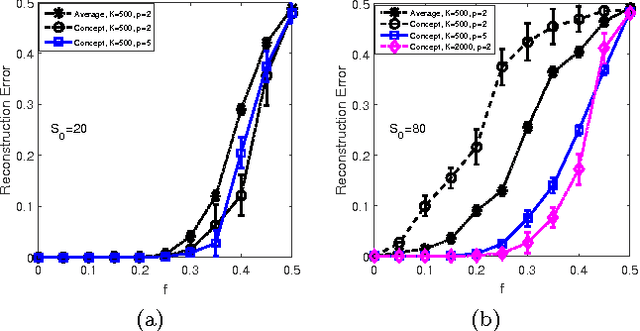
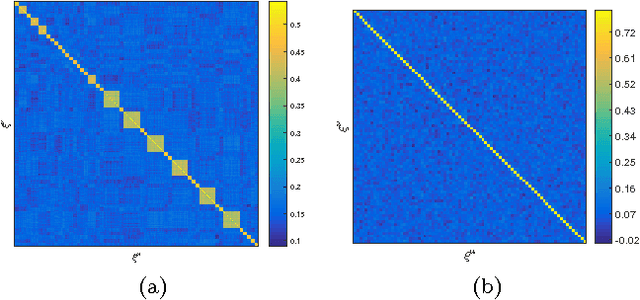
Unsupervised learning in a generalized Hopfield associative-memory network is investigated in this work. First, we prove that the (generalized) Hopfield model is equivalent to a semi-restricted Boltzmann machine with a layer of visible neurons and another layer of hidden binary neurons, so it could serve as the building block for a multilayered deep-learning system. We then demonstrate that the Hopfield network can learn to form a faithful internal representation of the observed samples, with the learned memory patterns being prototypes of the input data. Furthermore, we propose a spectral method to extract a small set of concepts (idealized prototypes) as the most concise summary or abstraction of the empirical data.