 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlimLLM: Accurate Structured Pruning for Large Language Models
May 28, 2025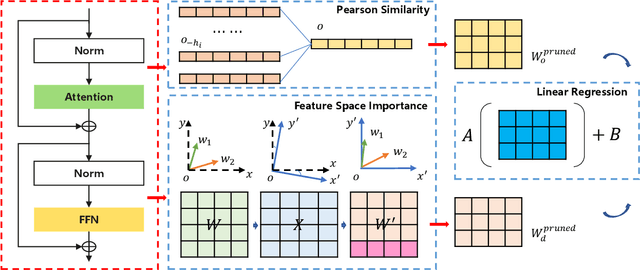
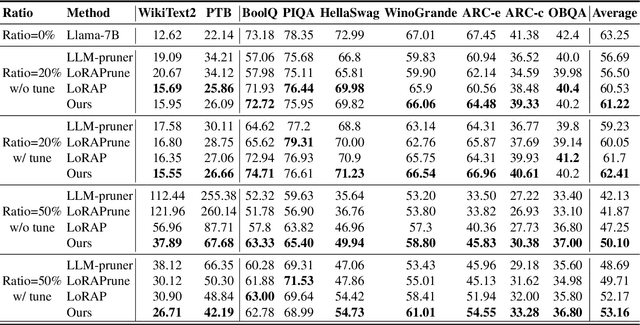

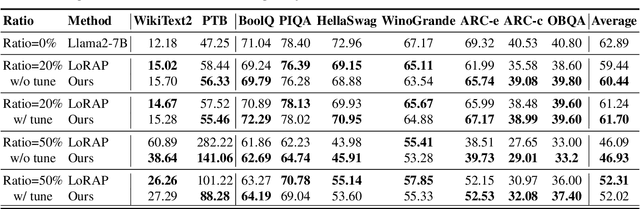
Large language models(LLMs) have garnered significant attention and demonstrated impressive capabilities in a wide range of applications. However, due to their enormous computational costs, the deployment and application of LLMs are often severely limited. To address this issue, structured pruning is an effective solution to compress the parameters of LLMs. Determining the importance of each sub-module in LLMs and minimizing performance loss are critical issues that need to be carefully addressed in structured pruning. In this paper, we propose an effective and fast structured pruning method named SlimLLM for large language models. For channel and attention head pruning, we evaluate the importance based on the entire channel or head, rather than merely aggregating the importance of individual elements within a sub-module. This approach enables a more holistic consideration of the interdependence among elements within the sub-module. In addition, we design a simple linear regression strategy for the output matrix to quickly recover performance. We also propose layer-based importance ratio to determine the pruning ratio for each layer. Based on the LLaMA benchmark results, our SlimLLM outperforms other methods and achieves state-of-the-art performance.
Pangu Light: Weight Re-Initialization for Pruning and Accelerating LLMs
May 26, 2025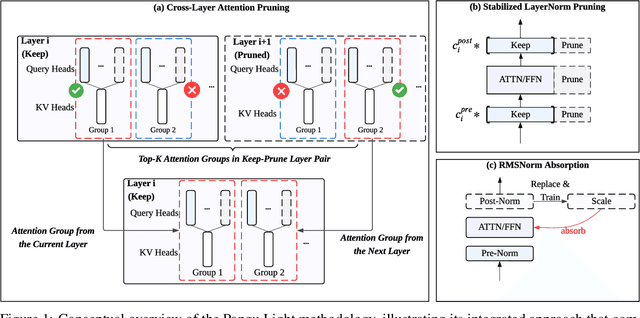

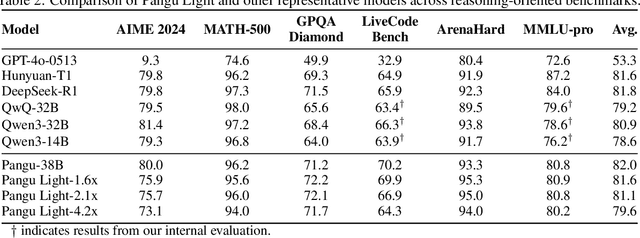
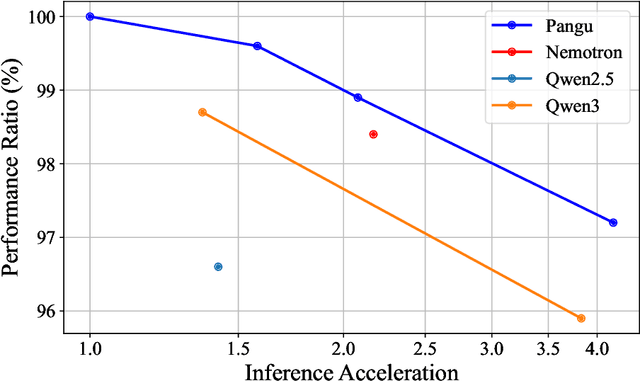
Large Language Models (LLMs) deliver state-of-the-art capabilities across numerous tasks, but their immense size and inference costs pose significant computational challenges for practical deployment. While structured pruning offers a promising avenue for model compression, existing methods often struggle with the detrimental effects of aggressive, simultaneous width and depth reductions, leading to substantial performance degradation. This paper argues that a critical, often overlooked, aspect in making such aggressive joint pruning viable is the strategic re-initialization and adjustment of remaining weights to improve the model post-pruning training accuracies. We introduce Pangu Light, a framework for LLM acceleration centered around structured pruning coupled with novel weight re-initialization techniques designed to address this ``missing piece''. Our framework systematically targets multiple axes, including model width, depth, attention heads, and RMSNorm, with its effectiveness rooted in novel re-initialization methods like Cross-Layer Attention Pruning (CLAP) and Stabilized LayerNorm Pruning (SLNP) that mitigate performance drops by providing the network a better training starting point. Further enhancing efficiency, Pangu Light incorporates specialized optimizations such as absorbing Post-RMSNorm computations and tailors its strategies to Ascend NPU characteristics. The Pangu Light models consistently exhibit a superior accuracy-efficiency trade-off, outperforming prominent baseline pruning methods like Nemotron and established LLMs like Qwen3 series. For instance, on Ascend NPUs, Pangu Light-32B's 81.6 average score and 2585 tokens/s throughput exceed Qwen3-32B's 80.9 average score and 2225 tokens/s.
ImputeINR: Time Series Imputation via Implicit Neural Representations for Disease Diagnosis with Missing Data
May 16, 2025Healthcare data frequently contain a substantial proportion of missing values, necessitating effective time series imputation to support downstream disease diagnosis tasks. However, existing imputation methods focus on discrete data points and are unable to effectively model sparse data, resulting in particularly poor performance for imputing substantial missing values. In this paper, we propose a novel approach, ImputeINR, for time series imputation by employing implicit neural representations (INR) to learn continuous functions for time series. ImputeINR leverages the merits of INR in that the continuous functions are not coupled to sampling frequency and have infinite sampling frequency, allowing ImputeINR to generate fine-grained imputations even on extremely sparse observed values. Extensive experiments conducted on eight datasets with five ratios of masked values show the superior imputation performance of ImputeINR, especially for high missing ratios in time series data. Furthermore, we validate that applying ImputeINR to impute missing values in healthcare data enhances the performance of downstream disease diagnosis tasks. Codes are available.
Transformer-Enhanced Variational Autoencoder for Crystal Structure Prediction
Feb 13, 2025Crystal structure forms the foundation for understanding the physical and chemical properties of materials. Generative models have emerged as a new paradigm in crystal structure prediction(CSP), however, accurately capturing key characteristics of crystal structures, such as periodicity and symmetry, remains a significant challenge. In this paper, we propose a Transformer-Enhanced Variational Autoencoder for Crystal Structure Prediction (TransVAE-CSP), who learns the characteristic distribution space of stable materials, enabling both the reconstruction and generation of crystal structures. TransVAE-CSP integrates adaptive distance expansion with irreducible representation to effectively capture the periodicity and symmetry of crystal structures, and the encoder is a transformer network based on an equivariant dot product attention mechanism. Experimental results on the carbon_24, perov_5, and mp_20 datasets demonstrate that TransVAE-CSP outperforms existing methods in structure reconstruction and generation tasks under various modeling metrics, offering a powerful tool for crystal structure design and optimization.
MetaNeRV: Meta Neural Representations for Videos with Spatial-Temporal Guidance
Jan 05, 2025



Neural Representations for Videos (NeRV) has emerged as a promising implicit neural representation (INR) approach for video analysis, which represents videos as neural networks with frame indexes as inputs. However, NeRV-based methods are time-consuming when adapting to a large number of diverse videos, as each video requires a separate NeRV model to be trained from scratch. In addition, NeRV-based methods spatially require generating a high-dimension signal (i.e., an entire image) from the input of a low-dimension timestamp, and a video typically consists of tens of frames temporally that have a minor change between adjacent frames. To improve the efficiency of video representation, we propose Meta Neural Representations for Videos, named MetaNeRV, a novel framework for fast NeRV representation for unseen videos. MetaNeRV leverages a meta-learning framework to learn an optimal parameter initialization, which serves as a good starting point for adapting to new videos. To address the unique spatial and temporal characteristics of video modality, we further introduce spatial-temporal guidance to improve the representation capabilities of MetaNeRV. Specifically, the spatial guidance with a multi-resolution loss aims to capture the information from different resolution stages, and the temporal guidance with an effective progressive learning strategy could gradually refine the number of fitted frames during the meta-learning process. Extensive experiments conducted on multiple datasets demonstrate the superiority of MetaNeRV for video representations and video compression.
SLAB: Efficient Transformers with Simplified Linear Attention and Progressive Re-parameterized Batch Normalization
May 19, 2024Transformers have become foundational architectures for both natural language and computer vision tasks. However, the high computational cost makes it quite challenging to deploy on resource-constraint devices. This paper investigates the computational bottleneck modules of efficient transformer, i.e., normalization layers and attention modules. LayerNorm is commonly used in transformer architectures but is not computational friendly due to statistic calculation during inference. However, replacing LayerNorm with more efficient BatchNorm in transformer often leads to inferior performance and collapse in training. To address this problem, we propose a novel method named PRepBN to progressively replace LayerNorm with re-parameterized BatchNorm in training. Moreover, we propose a simplified linear attention (SLA) module that is simple yet effective to achieve strong performance. Extensive experiments on image classification as well as object detection demonstrate the effectiveness of our proposed method. For example, our SLAB-Swin obtains $83.6\%$ top-1 accuracy on ImageNet-1K with $16.2$ms latency, which is $2.4$ms less than that of Flatten-Swin with $0.1\%$ higher accuracy. We also evaluated our method for language modeling task and obtain comparable performance and lower latency.Codes are publicly available at https://github.com/xinghaochen/SLAB and https://github.com/mindspore-lab/models/tree/master/research/huawei-noah/SLAB.