 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical world models: representing medical states, modelling clinical dynamics and guiding intervention policies
Jun 15, 2026Medical diagnosis and treatment are dynamic processes in which patient states evolve over time and clinical interventions alter future outcomes. Although current medical AI can detect disease, estimate risk and generate reports, many systems still return static labels or scores, offering limited insight into how illness may progress or how alternative interventions may reshape its trajectory. Medical world models adapt the world-model idea from artificial intelligence to healthcare by learning internal simulators of patient-state dynamics. Their long-term goal is to help clinicians anticipate deterioration, compare treatment-conditioned futures and tailor care to individual patients. Yet relevant work remains scattered across foundation models, longitudinal modelling, disease simulation, treatment-effect estimation, reinforcement learning and digital twins. To bridge this gap, this review outlines a roadmap for advancing medical AI from isolated diagnosis and prediction toward medical world models that simulate disease evolution and support intervention decisions. This roadmap is organized around three coupled capabilities: patient-state construction, clinical dynamics modelling and intervention decision support. Across representative systems, the comparison highlights what each capability contributes and how partial components can be integrated into more mature perception--dynamics--planning systems. Finally, we identify the challenges involved in turning plausible rollouts into clinically useful simulators. Related literature is available at https://github.com/1999kevin/awesome_medical_world_models.
The Empowerment of Science of Science by Large Language Models: New Tools and Methods
Nov 19, 2025Large language models (LLMs) have exhibited exceptional capabilities in natural language understanding and generation, image recognition, and multimodal tasks, charting a course towards AGI and emerging as a central issue in the global technological race. This manuscript conducts a comprehensive review of the core technologies that support LLMs from a user standpoint, including prompt engineering, knowledge-enhanced retrieval augmented generation, fine tuning, pretraining, and tool learning. Additionally, it traces the historical development of Science of Science (SciSci) and presents a forward looking perspective on the potential applications of LLMs within the scientometric domain. Furthermore, it discusses the prospect of an AI agent based model for scientific evaluation, and presents new research fronts detection and knowledge graph building methods with LLMs.
ImputeINR: Time Series Imputation via Implicit Neural Representations for Disease Diagnosis with Missing Data
May 16, 2025Healthcare data frequently contain a substantial proportion of missing values, necessitating effective time series imputation to support downstream disease diagnosis tasks. However, existing imputation methods focus on discrete data points and are unable to effectively model sparse data, resulting in particularly poor performance for imputing substantial missing values. In this paper, we propose a novel approach, ImputeINR, for time series imputation by employing implicit neural representations (INR) to learn continuous functions for time series. ImputeINR leverages the merits of INR in that the continuous functions are not coupled to sampling frequency and have infinite sampling frequency, allowing ImputeINR to generate fine-grained imputations even on extremely sparse observed values. Extensive experiments conducted on eight datasets with five ratios of masked values show the superior imputation performance of ImputeINR, especially for high missing ratios in time series data. Furthermore, we validate that applying ImputeINR to impute missing values in healthcare data enhances the performance of downstream disease diagnosis tasks. Codes are available.
Class Incremental Fault Diagnosis under Limited Fault Data via Supervised Contrastive Knowledge Distillation
Jan 16, 2025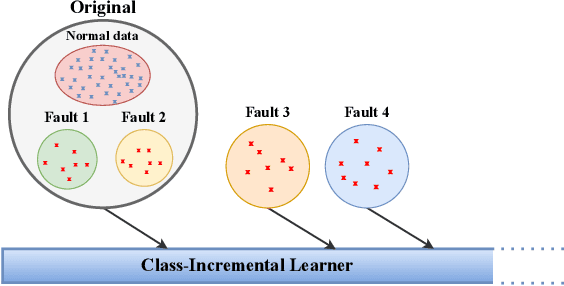
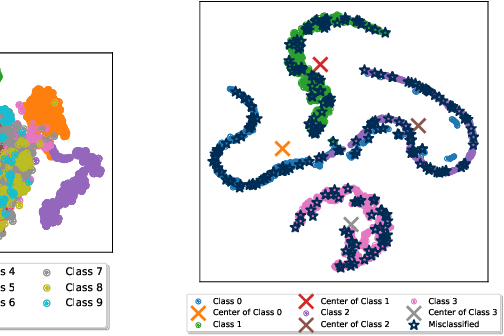
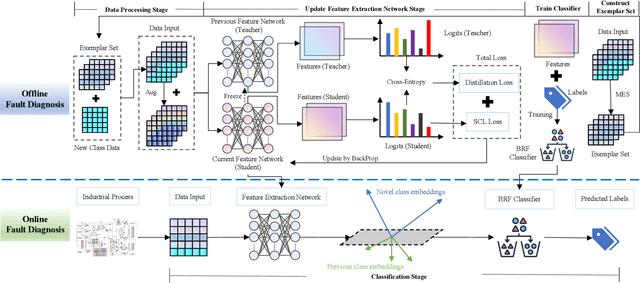
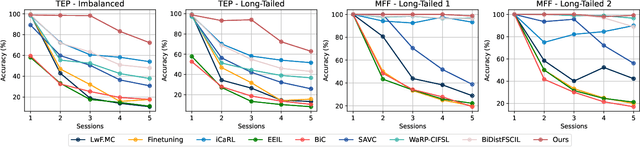
Class-incremental fault diagnosis requires a model to adapt to new fault classes while retaining previous knowledge. However, limited research exists for imbalanced and long-tailed data. Extracting discriminative features from few-shot fault data is challenging, and adding new fault classes often demands costly model retraining. Moreover, incremental training of existing methods risks catastrophic forgetting, and severe class imbalance can bias the model's decisions toward normal classes. To tackle these issues, we introduce a Supervised Contrastive knowledge distiLlation for class Incremental Fault Diagnosis (SCLIFD) framework proposing supervised contrastive knowledge distillation for improved representation learning capability and less forgetting, a novel prioritized exemplar selection method for sample replay to alleviate catastrophic forgetting, and the Random Forest Classifier to address the class imbalance. Extensive experimentation on simulated and real-world industrial datasets across various imbalance ratios demonstrates the superiority of SCLIFD over existing approaches. Our code can be found at https://github.com/Zhang-Henry/SCLIFD_TII.
TSINR: Capturing Temporal Continuity via Implicit Neural Representations for Time Series Anomaly Detection
Nov 20, 2024



Time series anomaly detection aims to identify unusual patterns in data or deviations from systems' expected behavior. The reconstruction-based methods are the mainstream in this task, which learn point-wise representation via unsupervised learning. However, the unlabeled anomaly points in training data may cause these reconstruction-based methods to learn and reconstruct anomalous data, resulting in the challenge of capturing normal patterns. In this paper, we propose a time series anomaly detection method based on implicit neural representation (INR) reconstruction, named TSINR, to address this challenge. Due to the property of spectral bias, TSINR enables prioritizing low-frequency signals and exhibiting poorer performance on high-frequency abnormal data. Specifically, we adopt INR to parameterize time series data as a continuous function and employ a transformer-based architecture to predict the INR of given data. As a result, the proposed TSINR method achieves the advantage of capturing the temporal continuity and thus is more sensitive to discontinuous anomaly data. In addition, we further design a novel form of INR continuous function to learn inter- and intra-channel information, and leverage a pre-trained large language model to amplify the intense fluctuations in anomalies. Extensive experiments demonstrate that TSINR achieves superior overall performance on both univariate and multivariate time series anomaly detection benchmarks compared to other state-of-the-art reconstruction-based methods. Our codes are available.
Hard Sample Mining Enabled Contrastive Feature Learning for Wind Turbine Pitch System Fault Diagnosis
Jun 26, 2023The efficient utilization of wind power by wind turbines relies on the ability of their pitch systems to adjust blade pitch angles in response to varying wind speeds. However, the presence of multiple fault types in the pitch system poses challenges in accurately classifying these faults. This paper proposes a novel method based on hard sample mining-enabled contrastive feature learning (HSMCFL) to address this problem. The proposed method employs cosine similarity to identify hard samples and subsequently leverages contrastive feature learning to enhance representation learning through the construction of hard sample pairs. Furthermore, a multilayer perceptron is trained using the learned discriminative representations to serve as an efficient classifier. To evaluate the effectiveness of the proposed method, two real datasets comprising wind turbine pitch system cog belt fracture data are utilized. The fault diagnosis performance of the proposed method is compared against existing methods, and the results demonstrate its superior performance. The proposed approach exhibits significant improvements in fault diagnosis accuracy, providing promising prospects for enhancing the reliability and efficiency of wind turbine pitch system fault diagnosis.
SCCAM: Supervised Contrastive Convolutional Attention Mechanism for Ante-hoc Interpretable Fault Diagnosis with Limited Fault Samples
Feb 17, 2023



In real industrial processes, fault diagnosis methods are required to learn from limited fault samples since the procedures are mainly under normal conditions and the faults rarely occur. Although attention mechanisms have become popular in the field of fault diagnosis, the existing attention-based methods are still unsatisfying for the above practical applications. First, pure attention-based architectures like transformers need a large number of fault samples to offset the lack of inductive biases thus performing poorly under limited fault samples. Moreover, the poor fault classification dilemma further leads to the failure of the existing attention-based methods to identify the root causes. To address the aforementioned issues, we innovatively propose a supervised contrastive convolutional attention mechanism (SCCAM) with ante-hoc interpretability, which solves the root cause analysis problem under limited fault samples for the first time. The proposed SCCAM method is tested on a continuous stirred tank heater and the Tennessee Eastman industrial process benchmark. Three common fault diagnosis scenarios are covered, including a balanced scenario for additional verification and two scenarios with limited fault samples (i.e., imbalanced scenario and long-tail scenario). The comprehensive results demonstrate that the proposed SCCAM method can achieve better performance compared with the state-of-the-art methods on fault classification and root cause analysis.
An Order-Invariant and Interpretable Hierarchical Dilated Convolution Neural Network for Chemical Fault Detection and Diagnosis
Feb 13, 2023



Fault detection and diagnosis is significant for reducing maintenance costs and improving health and safety in chemical processes. Convolution neural network (CNN) is a popular deep learning algorithm with many successful applications in chemical fault detection and diagnosis tasks. However, convolution layers in CNN are very sensitive to the order of features, which can lead to instability in the processing of tabular data. Optimal order of features result in better performance of CNN models but it is expensive to seek such optimal order. In addition, because of the encapsulation mechanism of feature extraction, most CNN models are opaque and have poor interpretability, thus failing to identify root-cause features without human supervision. These difficulties inevitably limit the performance and credibility of CNN methods. In this paper, we propose an order-invariant and interpretable hierarchical dilated convolution neural network (HDLCNN), which is composed by feature clustering, dilated convolution and the shapley additive explanations (SHAP) method. The novelty of HDLCNN lies in its capability of processing tabular data with features of arbitrary order without seeking the optimal order, due to the ability to agglomerate correlated features of feature clustering and the large receptive field of dilated convolution. Then, the proposed method provides interpretability by including the SHAP values to quantify feature contribution. Therefore, the root-cause features can be identified as the features with the highest contribution. Computational experiments are conducted on the Tennessee Eastman chemical process benchmark dataset. Compared with the other methods, the proposed HDLCNN-SHAP method achieves better performance on processing tabular data with features of arbitrary order, detecting faults, and identifying the root-cause features.
SCLIFD:Supervised Contrastive Knowledge Distillation for Incremental Fault Diagnosis under Limited Fault Data
Feb 12, 2023



Intelligent fault diagnosis has made extraordinary advancements currently. Nonetheless, few works tackle class-incremental learning for fault diagnosis under limited fault data, i.e., imbalanced and long-tailed fault diagnosis, which brings about various notable challenges. Initially, it is difficult to extract discriminative features from limited fault data. Moreover, a well-trained model must be retrained from scratch to classify the samples from new classes, thus causing a high computational burden and time consumption. Furthermore, the model may suffer from catastrophic forgetting when trained incrementally. Finally, the model decision is biased toward the new classes due to the class imbalance. The problems can consequently lead to performance degradation of fault diagnosis models. Accordingly, we introduce a supervised contrastive knowledge distillation for incremental fault diagnosis under limited fault data (SCLIFD) framework to address these issues, which extends the classical incremental classifier and representation learning (iCaRL) framework from three perspectives. Primarily, we adopt supervised contrastive knowledge distillation (KD) to enhance its representation learning capability under limited fault data. Moreover, we propose a novel prioritized exemplar selection method adaptive herding (AdaHerding) to restrict the increase of the computational burden, which is also combined with KD to alleviate catastrophic forgetting. Additionally, we adopt the cosine classifier to mitigate the adverse impact of class imbalance. We conduct extensive experiments on simulated and real-world industrial processes under different imbalance ratios. Experimental results show that our SCLIFD outperforms the existing methods by a large margin.