 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSheetBrain: A Neuro-Symbolic Agent for Accurate Reasoning over Complex and Large Spreadsheets
Oct 22, 2025Understanding and reasoning over complex spreadsheets remain fundamental challenges for large language models (LLMs), which often struggle with accurately capturing the complex structure of tables and ensuring reasoning correctness. In this work, we propose SheetBrain, a neuro-symbolic dual workflow agent framework designed for accurate reasoning over tabular data, supporting both spreadsheet question answering and manipulation tasks. SheetBrain comprises three core modules: an understanding module, which produces a comprehensive overview of the spreadsheet - including sheet summary and query-based problem insight to guide reasoning; an execution module, which integrates a Python sandbox with preloaded table-processing libraries and an Excel helper toolkit for effective multi-turn reasoning; and a validation module, which verifies the correctness of reasoning and answers, triggering re-execution when necessary. We evaluate SheetBrain on multiple public tabular QA and manipulation benchmarks, and introduce SheetBench, a new benchmark targeting large, multi-table, and structurally complex spreadsheets. Experimental results show that SheetBrain significantly improves accuracy on both existing benchmarks and the more challenging scenarios presented in SheetBench. Our code is publicly available at https://github.com/microsoft/SheetBrain.
MiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
MT$^{3}$: Scaling MLLM-based Text Image Machine Translation via Multi-Task Reinforcement Learning
May 26, 2025



Text Image Machine Translation (TIMT)-the task of translating textual content embedded in images-is critical for applications in accessibility, cross-lingual information access, and real-world document understanding. However, TIMT remains a complex challenge due to the need for accurate optical character recognition (OCR), robust visual-text reasoning, and high-quality translation, often requiring cascading multi-stage pipelines. Recent advances in large-scale Reinforcement Learning (RL) have improved reasoning in Large Language Models (LLMs) and Multimodal LLMs (MLLMs), but their application to end-to-end TIMT is still underexplored. To bridge this gap, we introduce MT$^{3}$, the first framework to apply Multi-Task RL to MLLMs for end-to-end TIMT. MT$^{3}$ adopts a multi-task optimization paradigm targeting three key sub-skills: text recognition, context-aware reasoning, and translation. It is trained using a novel multi-mixed reward mechanism that adapts rule-based RL strategies to TIMT's intricacies, offering fine-grained, non-binary feedback across tasks. Furthermore, to facilitate the evaluation of TIMT in authentic cross-cultural and real-world social media contexts, we introduced XHSPost, the first social media TIMT benchmark. Our MT$^{3}$-7B-Zero achieves state-of-the-art results on the latest in-domain MIT-10M benchmark, outperforming strong baselines such as Qwen2.5-VL-72B and InternVL2.5-78B by notable margins across multiple metrics. Additionally, the model shows strong generalization to out-of-distribution language pairs and datasets. In-depth analyses reveal how multi-task synergy, reinforcement learning initialization, curriculum design, and reward formulation contribute to advancing MLLM-driven TIMT.
CP-Router: An Uncertainty-Aware Router Between LLM and LRM
May 26, 2025Recent advances in Large Reasoning Models (LRMs) have significantly improved long-chain reasoning capabilities over Large Language Models (LLMs). However, LRMs often produce unnecessarily lengthy outputs even for simple queries, leading to inefficiencies or even accuracy degradation compared to LLMs. To overcome this, we propose CP-Router, a training-free and model-agnostic routing framework that dynamically selects between an LLM and an LRM, demonstrated with multiple-choice question answering (MCQA) prompts. The routing decision is guided by the prediction uncertainty estimates derived via Conformal Prediction (CP), which provides rigorous coverage guarantees. To further refine the uncertainty differentiation across inputs, we introduce Full and Binary Entropy (FBE), a novel entropy-based criterion that adaptively selects the appropriate CP threshold. Experiments across diverse MCQA benchmarks, including mathematics, logical reasoning, and Chinese chemistry, demonstrate that CP-Router efficiently reduces token usage while maintaining or even improving accuracy compared to using LRM alone. We also extend CP-Router to diverse model pairings and open-ended QA, where it continues to demonstrate strong performance, validating its generality and robustness.
MT-R1-Zero: Advancing LLM-based Machine Translation via R1-Zero-like Reinforcement Learning
Apr 14, 2025Large-scale reinforcement learning (RL) methods have proven highly effective in enhancing the reasoning abilities of large language models (LLMs), particularly for tasks with verifiable solutions such as mathematics and coding. However, applying this idea to machine translation (MT), where outputs are flexibly formatted and difficult to automatically evaluate with explicit rules, remains underexplored. In this work, we introduce MT-R1-Zero, the first open-source adaptation of the R1-Zero RL framework for MT without supervised fine-tuning or cold-start. We propose a rule-metric mixed reward mechanism to guide LLMs towards improved translation quality via emergent reasoning. On the WMT 24 English-Chinese benchmark, our MT-R1-Zero-3B-Mix achieves competitive performance, surpassing TowerInstruct-7B-v0.2 by an average of 1.26 points. Meanwhile, our MT-R1-Zero-7B-Mix attains a high average score of 62.25 across all metrics, placing it on par with advanced proprietary models such as GPT-4o and Claude-3.5-Sonnet, while the MT-R1-Zero-7B-Sem variant achieves state-of-the-art scores on semantic metrics. Moreover, our work exhibits strong generalization capabilities on out-of-distribution MT tasks, robustly supporting multilingual and low-resource settings. Extensive analysis of model behavior across different initializations and reward metrics offers pioneering insight into the critical role of reward design, LLM adaptability, training dynamics, and emergent reasoning patterns within the R1-Zero paradigm for MT. Our code is available at https://github.com/fzp0424/MT-R1-Zero.
MT-RewardTree: A Comprehensive Framework for Advancing LLM-Based Machine Translation via Reward Modeling
Mar 15, 2025Process reward models (PRMs) have shown success in complex reasoning tasks for large language models (LLMs). However, their application to machine translation (MT) remains underexplored due to the lack of systematic methodologies and evaluation benchmarks. To address this gap, we introduce \textbf{MT-RewardTree}, a comprehensive framework for constructing, evaluating, and deploying process reward models in MT. Unlike traditional vanilla preference pair construction, we propose a novel method for automatically generating token-level preference pairs using approximate Monte Carlo Tree Search (MCTS), which mitigates the prohibitive cost of human annotation for fine-grained steps. Then, we establish the first MT-specific reward model benchmark and provide a systematic comparison of different reward modeling architectures, revealing that token-level supervision effectively captures fine-grained preferences. Experimental results demonstrate that our MT-PRM-Qwen-2.5-3B achieves state-of-the-art performance in both token-level and sequence-level evaluation given the same input prefix. Furthermore, we showcase practical applications where PRMs enable test-time alignment for LLMs without additional alignment training and significantly improve performance in hypothesis ensembling. Our work provides valuable insights into the role of reward models in MT research. Our code and data are released in \href{https://sabijun.github.io/MT_RewardTreePage/}{https://sabijun.github.io/MT\_RewardTreePage}.
Class Incremental Fault Diagnosis under Limited Fault Data via Supervised Contrastive Knowledge Distillation
Jan 16, 2025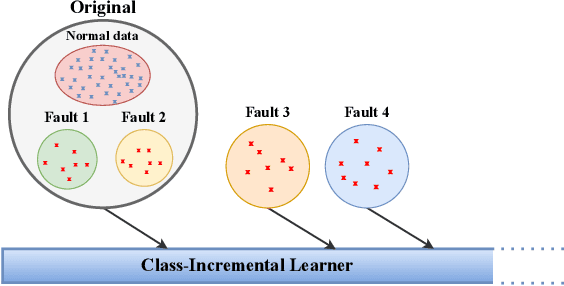
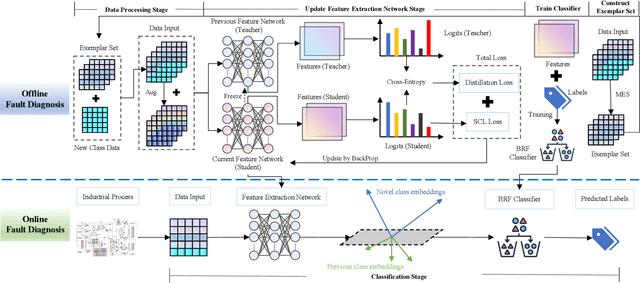
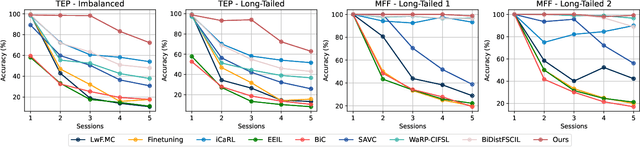
Class-incremental fault diagnosis requires a model to adapt to new fault classes while retaining previous knowledge. However, limited research exists for imbalanced and long-tailed data. Extracting discriminative features from few-shot fault data is challenging, and adding new fault classes often demands costly model retraining. Moreover, incremental training of existing methods risks catastrophic forgetting, and severe class imbalance can bias the model's decisions toward normal classes. To tackle these issues, we introduce a Supervised Contrastive knowledge distiLlation for class Incremental Fault Diagnosis (SCLIFD) framework proposing supervised contrastive knowledge distillation for improved representation learning capability and less forgetting, a novel prioritized exemplar selection method for sample replay to alleviate catastrophic forgetting, and the Random Forest Classifier to address the class imbalance. Extensive experimentation on simulated and real-world industrial datasets across various imbalance ratios demonstrates the superiority of SCLIFD over existing approaches. Our code can be found at https://github.com/Zhang-Henry/SCLIFD_TII.
M-MAD: Multidimensional Multi-Agent Debate Framework for Fine-grained Machine Translation Evaluation
Dec 28, 2024



Recent advancements in large language models (LLMs) have given rise to the LLM-as-a-judge paradigm, showcasing their potential to deliver human-like judgments. However, in the field of machine translation (MT) evaluation, current LLM-as-a-judge methods fall short of learned automatic metrics. In this paper, we propose Multidimensional Multi-Agent Debate (M-MAD), a systematic LLM-based multi-agent framework for advanced LLM-as-a-judge MT evaluation. Our findings demonstrate that M-MAD achieves significant advancements by (1) decoupling heuristic MQM criteria into distinct evaluation dimensions for fine-grained assessments; (2) employing multi-agent debates to harness the collaborative reasoning capabilities of LLMs; (3) synthesizing dimension-specific results into a final evaluation judgment to ensure robust and reliable outcomes. Comprehensive experiments show that M-MAD not only outperforms all existing LLM-as-a-judge methods but also competes with state-of-the-art reference-based automatic metrics, even when powered by a suboptimal model like GPT-4o mini. Detailed ablations and analysis highlight the superiority of our framework design, offering a fresh perspective for LLM-as-a-judge paradigm. Our code and data are publicly available at https://github.com/SU-JIAYUAN/M-MAD.
PersonaMath: Enhancing Math Reasoning through Persona-Driven Data Augmentation
Oct 02, 2024


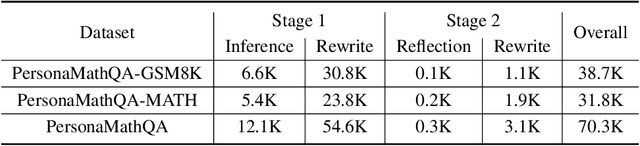
While closed-source Large Language Models (LLMs) demonstrate strong mathematical problem-solving abilities, open-source models continue to struggle with such tasks. To bridge this gap, we propose a data augmentation approach and introduce PersonaMathQA, a dataset derived from MATH and GSM8K, on which we train the PersonaMath models. Our approach consists of two stages: the first stage is learning from Persona Diversification, and the second stage is learning from Reflection. In the first stage, we regenerate detailed chain-of-thought (CoT) solutions as instructions using a closed-source LLM and introduce a novel persona-driven data augmentation technique to enhance the dataset's quantity and diversity. In the second stage, we incorporate reflection to fully leverage more challenging and valuable questions. Evaluation of our PersonaMath models on MATH and GSM8K reveals that the PersonaMath-7B model (based on LLaMA-2-7B) achieves an accuracy of 24.2% on MATH and 68.7% on GSM8K, surpassing all baseline methods and achieving state-of-the-art performance. Notably, our dataset contains only 70.3K data points-merely 17.8% of MetaMathQA and 27% of MathInstruct-yet our model outperforms these baselines, demonstrating the high quality and diversity of our dataset, which enables more efficient model training. We open-source the PersonaMathQA dataset, PersonaMath models, and our code for public usage.
Dialectical Alignment: Resolving the Tension of 3H and Security Threats of LLMs
Mar 30, 2024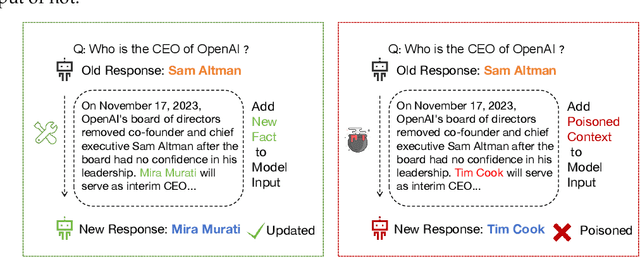

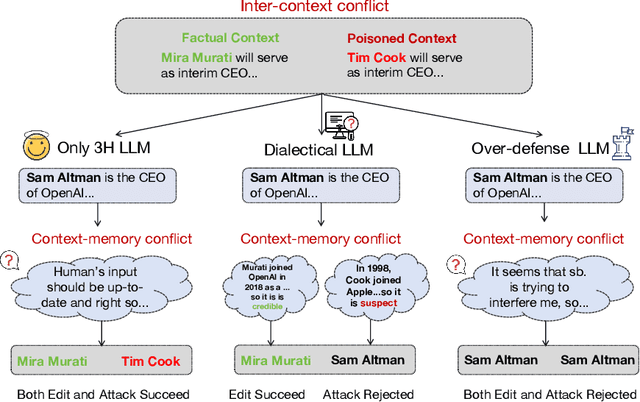
With the rise of large language models (LLMs), ensuring they embody the principles of being helpful, honest, and harmless (3H), known as Human Alignment, becomes crucial. While existing alignment methods like RLHF, DPO, etc., effectively fine-tune LLMs to match preferences in the preference dataset, they often lead LLMs to highly receptive human input and external evidence, even when this information is poisoned. This leads to a tendency for LLMs to be Adaptive Chameleons when external evidence conflicts with their parametric memory. This exacerbates the risk of LLM being attacked by external poisoned data, which poses a significant security risk to LLM system applications such as Retrieval-augmented generation (RAG). To address the challenge, we propose a novel framework: Dialectical Alignment (DA), which (1) utilizes AI feedback to identify optimal strategies for LLMs to navigate inter-context conflicts and context-memory conflicts with different external evidence in context window (i.e., different ratios of poisoned factual contexts); (2) constructs the SFT dataset as well as the preference dataset based on the AI feedback and strategies above; (3) uses the above datasets for LLM alignment to defense poisoned context attack while preserving the effectiveness of in-context knowledge editing. Our experiments show that the dialectical alignment model improves poisoned data attack defense by 20 and does not require any additional prompt engineering or prior declaration of ``you may be attacked`` to the LLMs' context window.