 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialectical Alignment: Resolving the Tension of 3H and Security Threats of LLMs
Paper and Code
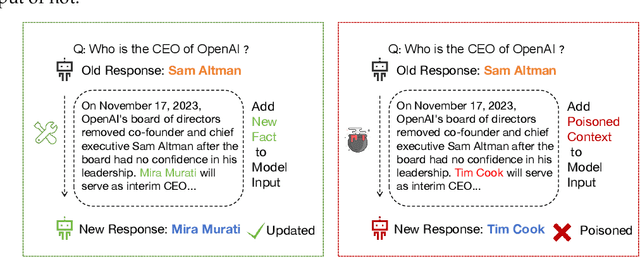

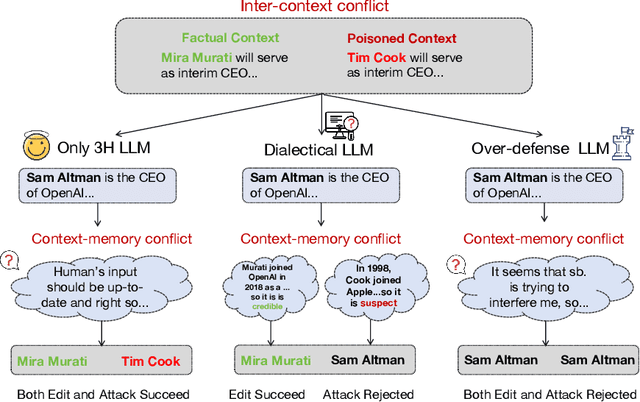
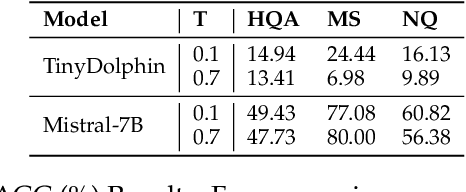
With the rise of large language models (LLMs), ensuring they embody the principles of being helpful, honest, and harmless (3H), known as Human Alignment, becomes crucial. While existing alignment methods like RLHF, DPO, etc., effectively fine-tune LLMs to match preferences in the preference dataset, they often lead LLMs to highly receptive human input and external evidence, even when this information is poisoned. This leads to a tendency for LLMs to be Adaptive Chameleons when external evidence conflicts with their parametric memory. This exacerbates the risk of LLM being attacked by external poisoned data, which poses a significant security risk to LLM system applications such as Retrieval-augmented generation (RAG). To address the challenge, we propose a novel framework: Dialectical Alignment (DA), which (1) utilizes AI feedback to identify optimal strategies for LLMs to navigate inter-context conflicts and context-memory conflicts with different external evidence in context window (i.e., different ratios of poisoned factual contexts); (2) constructs the SFT dataset as well as the preference dataset based on the AI feedback and strategies above; (3) uses the above datasets for LLM alignment to defense poisoned context attack while preserving the effectiveness of in-context knowledge editing. Our experiments show that the dialectical alignment model improves poisoned data attack defense by 20 and does not require any additional prompt engineering or prior declaration of ``you may be attacked`` to the LLMs' context window.