 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoSkills: Self-Evolving Agent Skills via Co-Evolutionary Verification
Apr 02, 2026Anthropic proposes the concept of skills for LLM agents to tackle multi-step professional tasks that simple tool invocations cannot address. A tool is a single, self-contained function, whereas a skill is a structured bundle of interdependent multi-file artifacts. Currently, skill generation is not only label-intensive due to manual authoring, but also may suffer from human--machine cognitive misalignment, which can lead to degraded agent performance, as evidenced by evaluations on SkillsBench. Therefore, we aim to enable agents to autonomously generate skills. However, existing self-evolving methods designed for tools cannot be directly applied to skills due to their increased complexity. To address these issues, we propose EvoSkills, a self-evolving skills framework that enables agents to autonomously construct complex, multi-file skill packages. Specifically, EvoSkills couples a Skill Generator that iteratively refines skills with a Surrogate Verifier that co-evolves to provide informative and actionable feedback without access to ground-truth test content. On SkillsBench, EvoSkills achieves the highest pass rate among five baselines on both Claude Code and Codex, and also exhibits strong generalization capabilities to six additional LLMs.
AdaptiveK Sparse Autoencoders: Dynamic Sparsity Allocation for Interpretable LLM Representations
Aug 24, 2025Understanding the internal representations of large language models (LLMs) remains a central challenge for interpretability research. Sparse autoencoders (SAEs) offer a promising solution by decomposing activations into interpretable features, but existing approaches rely on fixed sparsity constraints that fail to account for input complexity. We propose Adaptive Top K Sparse Autoencoders (AdaptiveK), a novel framework that dynamically adjusts sparsity levels based on the semantic complexity of each input. Leveraging linear probes, we demonstrate that context complexity is linearly encoded in LLM representations, and we use this signal to guide feature allocation during training. Experiments across three language models (Pythia-70M, Pythia-160M, and Gemma-2-2B) demonstrate that this complexity-driven adaptation significantly outperforms fixed-sparsity approaches on reconstruction fidelity, explained variance, and cosine similarity metrics while eliminating the computational burden of extensive hyperparameter tuning.
GBC: Generalized Behavior-Cloning Framework for Whole-Body Humanoid Imitation
Aug 13, 2025The creation of human-like humanoid robots is hindered by a fundamental fragmentation: data processing and learning algorithms are rarely universal across different robot morphologies. This paper introduces the Generalized Behavior Cloning (GBC) framework, a comprehensive and unified solution designed to solve this end-to-end challenge. GBC establishes a complete pathway from human motion to robot action through three synergistic innovations. First, an adaptive data pipeline leverages a differentiable IK network to automatically retarget any human MoCap data to any humanoid. Building on this foundation, our novel DAgger-MMPPO algorithm with its MMTransformer architecture learns robust, high-fidelity imitation policies. To complete the ecosystem, the entire framework is delivered as an efficient, open-source platform based on Isaac Lab, empowering the community to deploy the full workflow via simple configuration scripts. We validate the power and generality of GBC by training policies on multiple heterogeneous humanoids, demonstrating excellent performance and transfer to novel motions. This work establishes the first practical and unified pathway for creating truly generalized humanoid controllers.
Class Incremental Fault Diagnosis under Limited Fault Data via Supervised Contrastive Knowledge Distillation
Jan 16, 2025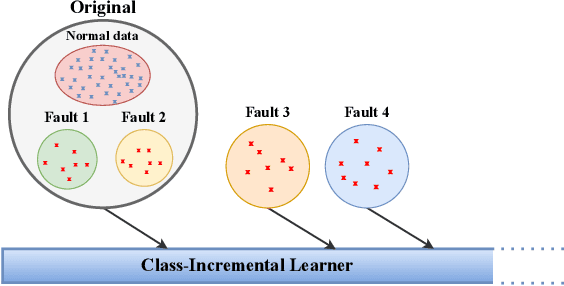
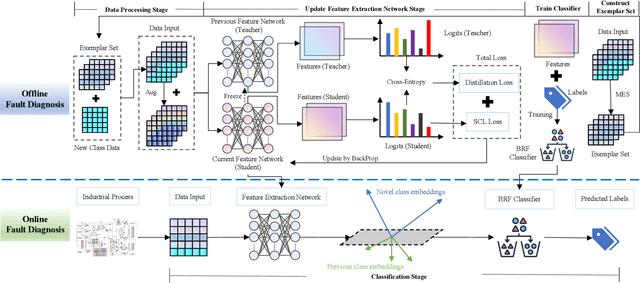
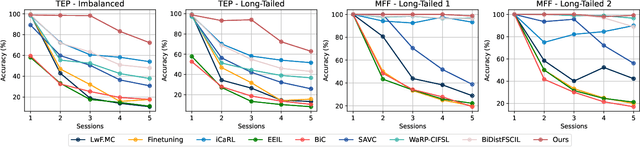
Class-incremental fault diagnosis requires a model to adapt to new fault classes while retaining previous knowledge. However, limited research exists for imbalanced and long-tailed data. Extracting discriminative features from few-shot fault data is challenging, and adding new fault classes often demands costly model retraining. Moreover, incremental training of existing methods risks catastrophic forgetting, and severe class imbalance can bias the model's decisions toward normal classes. To tackle these issues, we introduce a Supervised Contrastive knowledge distiLlation for class Incremental Fault Diagnosis (SCLIFD) framework proposing supervised contrastive knowledge distillation for improved representation learning capability and less forgetting, a novel prioritized exemplar selection method for sample replay to alleviate catastrophic forgetting, and the Random Forest Classifier to address the class imbalance. Extensive experimentation on simulated and real-world industrial datasets across various imbalance ratios demonstrates the superiority of SCLIFD over existing approaches. Our code can be found at https://github.com/Zhang-Henry/SCLIFD_TII.
Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents
Oct 03, 2024



Although LLM-based agents, powered by Large Language Models (LLMs), can use external tools and memory mechanisms to solve complex real-world tasks, they may also introduce critical security vulnerabilities. However, the existing literature does not comprehensively evaluate attacks and defenses against LLM-based agents. To address this, we introduce Agent Security Bench (ASB), a comprehensive framework designed to formalize, benchmark, and evaluate the attacks and defenses of LLM-based agents, including 10 scenarios (e.g., e-commerce, autonomous driving, finance), 10 agents targeting the scenarios, over 400 tools, 23 different types of attack/defense methods, and 8 evaluation metrics. Based on ASB, we benchmark 10 prompt injection attacks, a memory poisoning attack, a novel Plan-of-Thought backdoor attack, a mixed attack, and 10 corresponding defenses across 13 LLM backbones with nearly 90,000 testing cases in total. Our benchmark results reveal critical vulnerabilities in different stages of agent operation, including system prompt, user prompt handling, tool usage, and memory retrieval, with the highest average attack success rate of 84.30\%, but limited effectiveness shown in current defenses, unveiling important works to be done in terms of agent security for the community. Our code can be found at https://github.com/agiresearch/ASB.
AnyBipe: An End-to-End Framework for Training and Deploying Bipedal Robots Guided by Large Language Models
Sep 13, 2024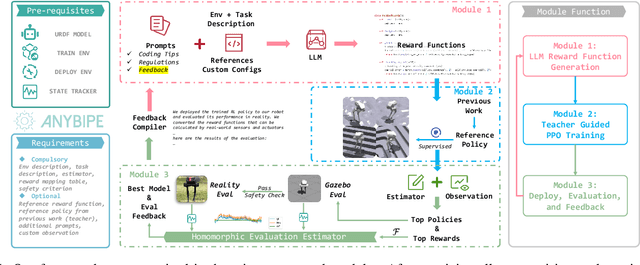


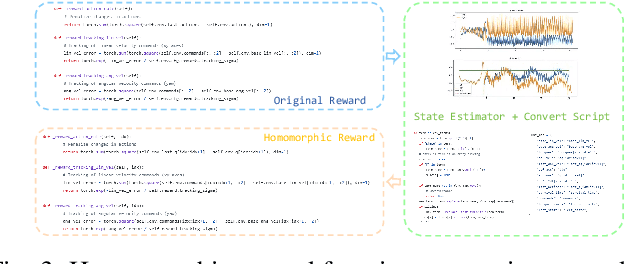
Training and deploying reinforcement learning (RL) policies for robots, especially in accomplishing specific tasks, presents substantial challenges. Recent advancements have explored diverse reward function designs, training techniques, simulation-to-reality (sim-to-real) transfers, and performance analysis methodologies, yet these still require significant human intervention. This paper introduces an end-to-end framework for training and deploying RL policies, guided by Large Language Models (LLMs), and evaluates its effectiveness on bipedal robots. The framework consists of three interconnected modules: an LLM-guided reward function design module, an RL training module leveraging prior work, and a sim-to-real homomorphic evaluation module. This design significantly reduces the need for human input by utilizing only essential simulation and deployment platforms, with the option to incorporate human-engineered strategies and historical data. We detail the construction of these modules, their advantages over traditional approaches, and demonstrate the framework's capability to autonomously develop and refine controlling strategies for bipedal robot locomotion, showcasing its potential to operate independently of human intervention.
From Uncertainty to Clarity: Uncertainty-Guided Class-Incremental Learning for Limited Biomedical Samples via Semantic Expansion
Sep 12, 2024



In real-world clinical settings, data distributions evolve over time, with a continuous influx of new, limited disease cases. Therefore, class incremental learning is of great significance, i.e., deep learning models are required to learn new class knowledge while maintaining accurate recognition of previous diseases. However, traditional deep neural networks often suffer from severe forgetting of prior knowledge when adapting to new data unless trained from scratch, which undesirably costs much time and computational burden. Additionally, the sample sizes for different diseases can be highly imbalanced, with newly emerging diseases typically having much fewer instances, consequently causing the classification bias. To tackle these challenges, we are the first to propose a class-incremental learning method under limited samples in the biomedical field. First, we propose a novel cumulative entropy prediction module to measure the uncertainty of the samples, of which the most uncertain samples are stored in a memory bank as exemplars for the model's later review. Furthermore, we theoretically demonstrate its effectiveness in measuring uncertainty. Second, we developed a fine-grained semantic expansion module through various augmentations, leading to more compact distributions within the feature space and creating sufficient room for generalization to new classes. Besides, a cosine classifier is utilized to mitigate classification bias caused by imbalanced datasets. Across four imbalanced data distributions over two datasets, our method achieves optimal performance, surpassing state-of-the-art methods by as much as 53.54% in accuracy.