 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGBC: Generalized Behavior-Cloning Framework for Whole-Body Humanoid Imitation
Aug 13, 2025The creation of human-like humanoid robots is hindered by a fundamental fragmentation: data processing and learning algorithms are rarely universal across different robot morphologies. This paper introduces the Generalized Behavior Cloning (GBC) framework, a comprehensive and unified solution designed to solve this end-to-end challenge. GBC establishes a complete pathway from human motion to robot action through three synergistic innovations. First, an adaptive data pipeline leverages a differentiable IK network to automatically retarget any human MoCap data to any humanoid. Building on this foundation, our novel DAgger-MMPPO algorithm with its MMTransformer architecture learns robust, high-fidelity imitation policies. To complete the ecosystem, the entire framework is delivered as an efficient, open-source platform based on Isaac Lab, empowering the community to deploy the full workflow via simple configuration scripts. We validate the power and generality of GBC by training policies on multiple heterogeneous humanoids, demonstrating excellent performance and transfer to novel motions. This work establishes the first practical and unified pathway for creating truly generalized humanoid controllers.
AnyBipe: An End-to-End Framework for Training and Deploying Bipedal Robots Guided by Large Language Models
Sep 13, 2024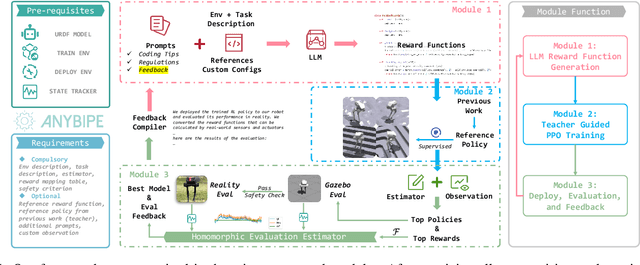


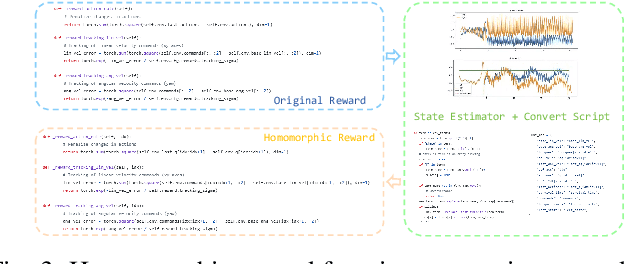
Training and deploying reinforcement learning (RL) policies for robots, especially in accomplishing specific tasks, presents substantial challenges. Recent advancements have explored diverse reward function designs, training techniques, simulation-to-reality (sim-to-real) transfers, and performance analysis methodologies, yet these still require significant human intervention. This paper introduces an end-to-end framework for training and deploying RL policies, guided by Large Language Models (LLMs), and evaluates its effectiveness on bipedal robots. The framework consists of three interconnected modules: an LLM-guided reward function design module, an RL training module leveraging prior work, and a sim-to-real homomorphic evaluation module. This design significantly reduces the need for human input by utilizing only essential simulation and deployment platforms, with the option to incorporate human-engineered strategies and historical data. We detail the construction of these modules, their advantages over traditional approaches, and demonstrate the framework's capability to autonomously develop and refine controlling strategies for bipedal robot locomotion, showcasing its potential to operate independently of human intervention.
Scale Optimization Using Evolutionary Reinforcement Learning for Object Detection on Drone Imagery
Dec 23, 2023Object detection in aerial imagery presents a significant challenge due to large scale variations among objects. This paper proposes an evolutionary reinforcement learning agent, integrated within a coarse-to-fine object detection framework, to optimize the scale for more effective detection of objects in such images. Specifically, a set of patches potentially containing objects are first generated. A set of rewards measuring the localization accuracy, the accuracy of predicted labels, and the scale consistency among nearby patches are designed in the agent to guide the scale optimization. The proposed scale-consistency reward ensures similar scales for neighboring objects of the same category. Furthermore, a spatial-semantic attention mechanism is designed to exploit the spatial semantic relations between patches. The agent employs the proximal policy optimization strategy in conjunction with the evolutionary strategy, effectively utilizing both the current patch status and historical experience embedded in the agent. The proposed model is compared with state-of-the-art methods on two benchmark datasets for object detection on drone imagery. It significantly outperforms all the compared methods.
Multi-View Spectrogram Transformer for Respiratory Sound Classification
Dec 05, 2023Deep neural networks have been applied to audio spectrograms for respiratory sound classification. Existing models often treat the spectrogram as a synthetic image while overlooking its physical characteristics. In this paper, a Multi-View Spectrogram Transformer (MVST) is proposed to embed different views of time-frequency characteristics into the vision transformer. Specifically, the proposed MVST splits the mel-spectrogram into different sized patches, representing the multi-view acoustic elements of a respiratory sound. These patches and positional embeddings are then fed into transformer encoders to extract the attentional information among patches through a self-attention mechanism. Finally, a gated fusion scheme is designed to automatically weigh the multi-view features to highlight the best one in a specific scenario. Experimental results on the ICBHI dataset demonstrate that the proposed MVST significantly outperforms state-of-the-art methods for classifying respiratory sounds.
One-shot Visual Reasoning on RPMs with an Application to Video Frame Prediction
Nov 24, 2021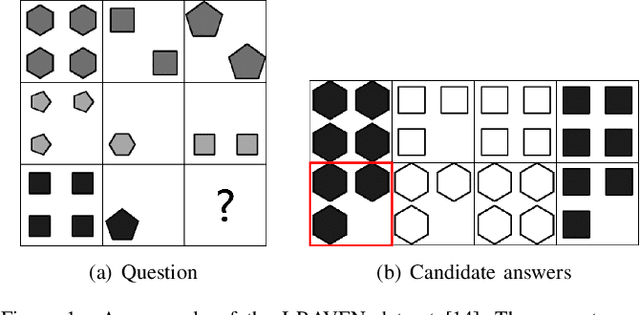
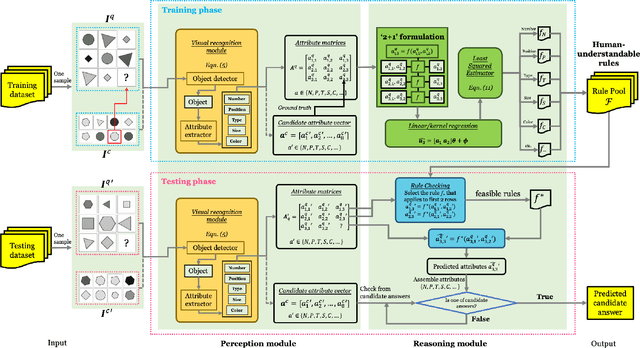

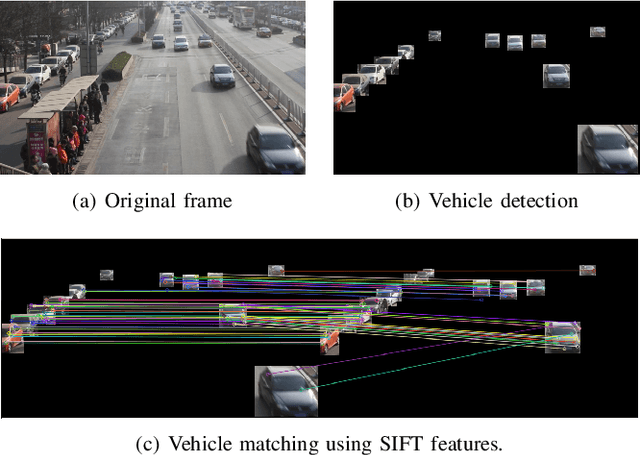
Raven's Progressive Matrices (RPMs) are frequently used in evaluating human's visual reasoning ability. Researchers have made considerable effort in developing a system which could automatically solve the RPM problem, often through a black-box end-to-end Convolutional Neural Network (CNN) for both visual recognition and logical reasoning tasks. Towards the objective of developing a highly explainable solution, we propose a One-shot Human-Understandable ReaSoner (Os-HURS), which is a two-step framework including a perception module and a reasoning module, to tackle the challenges of real-world visual recognition and subsequent logical reasoning tasks, respectively. For the reasoning module, we propose a "2+1" formulation that can be better understood by humans and significantly reduces the model complexity. As a result, a precise reasoning rule can be deduced from one RPM sample only, which is not feasible for existing solution methods. The proposed reasoning module is also capable of yielding a set of reasoning rules, precisely modeling the human knowledge in solving the RPM problem. To validate the proposed method on real-world applications, an RPM-like One-shot Frame-prediction (ROF) dataset is constructed, where visual reasoning is conducted on RPMs constructed using real-world video frames instead of synthetic images. Experimental results on various RPM-like datasets demonstrate that the proposed Os-HURS achieves a significant and consistent performance gain compared with the state-of-the-art models.
Attention-based Dual-stream Vision Transformer for Radar Gait Recognition
Nov 24, 2021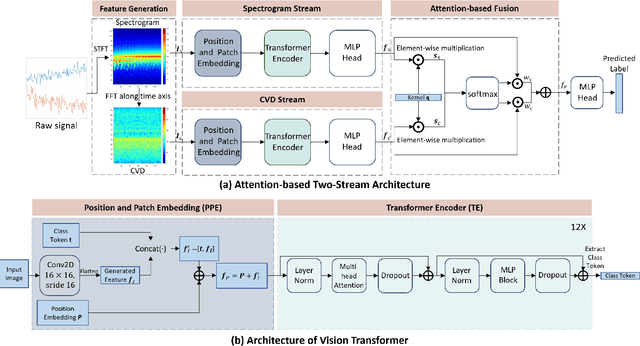

Radar gait recognition is robust to light variations and less infringement on privacy. Previous studies often utilize either spectrograms or cadence velocity diagrams. While the former shows the time-frequency patterns, the latter encodes the repetitive frequency patterns. In this work, a dual-stream neural network with attention-based fusion is proposed to fully aggregate the discriminant information from these two representations. The both streams are designed based on the Vision Transformer, which well captures the gait characteristics embedded in these representations. The proposed method is validated on a large benchmark dataset for radar gait recognition, which shows that it significantly outperforms state-of-the-art solutions.
A Data Augmentation Method by Mixing Up Negative Candidate Answers for Solving Raven's Progressive Matrices
Mar 09, 2021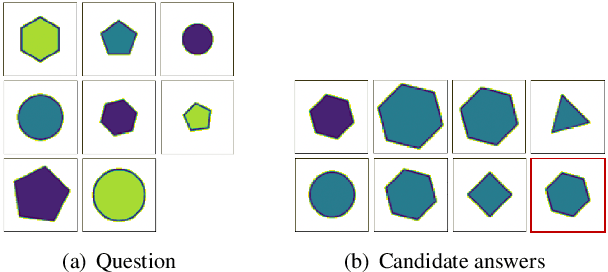

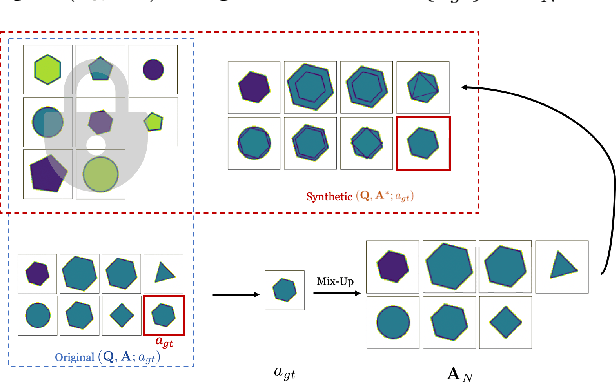
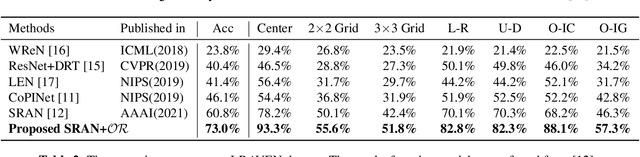
Raven's Progressive Matrices (RPMs) are frequently-used in testing human's visual reasoning ability. Recently developed RPM-like datasets and solution models transfer this kind of problems from cognitive science to computer science. In view of the poor generalization performance due to insufficient samples in RPM datasets, we propose a data augmentation strategy by image mix-up, which is generalizable to a variety of multiple-choice problems, especially for image-based RPM-like problems. By focusing on potential functionalities of negative candidate answers, the visual reasoning capability of the model is enhanced. By applying the proposed data augmentation method, we achieve significant and consistent improvement on various RPM-like datasets compared with the state-of-the-art models.
Analytics and Machine Learning in Vehicle Routing Research
Feb 19, 2021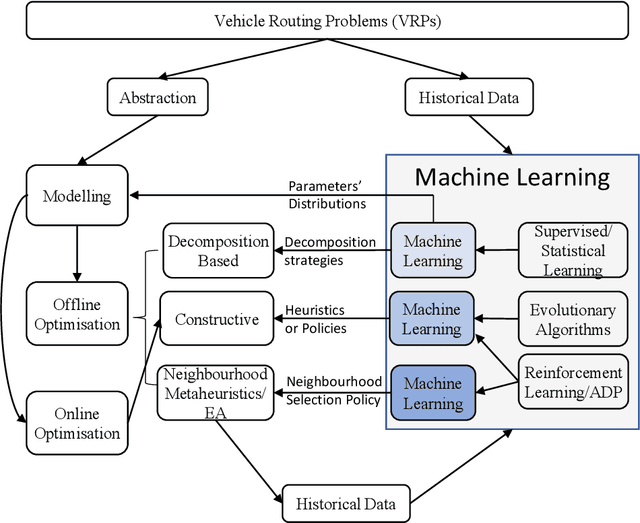
The Vehicle Routing Problem (VRP) is one of the most intensively studied combinatorial optimisation problems for which numerous models and algorithms have been proposed. To tackle the complexities, uncertainties and dynamics involved in real-world VRP applications, Machine Learning (ML) methods have been used in combination with analytical approaches to enhance problem formulations and algorithmic performance across different problem solving scenarios. However, the relevant papers are scattered in several traditional research fields with very different, sometimes confusing, terminologies. This paper presents a first, comprehensive review of hybrid methods that combine analytical techniques with ML tools in addressing VRP problems. Specifically, we review the emerging research streams on ML-assisted VRP modelling and ML-assisted VRP optimisation. We conclude that ML can be beneficial in enhancing VRP modelling, and improving the performance of algorithms for both online and offline VRP optimisations. Finally, challenges and future opportunities of VRP research are discussed.