 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERL-MPP: Evolutionary Reinforcement Learning with Multi-head Puzzle Perception for Solving Large-scale Jigsaw Puzzles of Eroded Gaps
Apr 13, 2025Solving jigsaw puzzles has been extensively studied. While most existing models focus on solving either small-scale puzzles or puzzles with no gap between fragments, solving large-scale puzzles with gaps presents distinctive challenges in both image understanding and combinatorial optimization. To tackle these challenges, we propose a framework of Evolutionary Reinforcement Learning with Multi-head Puzzle Perception (ERL-MPP) to derive a better set of swapping actions for solving the puzzles. Specifically, to tackle the challenges of perceiving the puzzle with gaps, a Multi-head Puzzle Perception Network (MPPN) with a shared encoder is designed, where multiple puzzlet heads comprehensively perceive the local assembly status, and a discriminator head provides a global assessment of the puzzle. To explore the large swapping action space efficiently, an Evolutionary Reinforcement Learning (EvoRL) agent is designed, where an actor recommends a set of suitable swapping actions from a large action space based on the perceived puzzle status, a critic updates the actor using the estimated rewards and the puzzle status, and an evaluator coupled with evolutionary strategies evolves the actions aligning with the historical assembly experience. The proposed ERL-MPP is comprehensively evaluated on the JPLEG-5 dataset with large gaps and the MIT dataset with large-scale puzzles. It significantly outperforms all state-of-the-art models on both datasets.
Mask Attack Detection Using Vascular-weighted Motion-robust rPPG Signals
May 25, 2023Detecting 3D mask attacks to a face recognition system is challenging. Although genuine faces and 3D face masks show significantly different remote photoplethysmography (rPPG) signals, rPPG-based face anti-spoofing methods often suffer from performance degradation due to unstable face alignment in the video sequence and weak rPPG signals. To enhance the rPPG signal in a motion-robust way, a landmark-anchored face stitching method is proposed to align the faces robustly and precisely at the pixel-wise level by using both SIFT keypoints and facial landmarks. To better encode the rPPG signal, a weighted spatial-temporal representation is proposed, which emphasizes the face regions with rich blood vessels. In addition, characteristics of rPPG signals in different color spaces are jointly utilized. To improve the generalization capability, a lightweight EfficientNet with a Gated Recurrent Unit (GRU) is designed to extract both spatial and temporal features from the rPPG spatial-temporal representation for classification. The proposed method is compared with the state-of-the-art methods on five benchmark datasets under both intra-dataset and cross-dataset evaluations. The proposed method shows a significant and consistent improvement in performance over other state-of-the-art rPPG-based methods for face spoofing detection.
Video Question Answering Using CLIP-Guided Visual-Text Attention
Mar 08, 2023
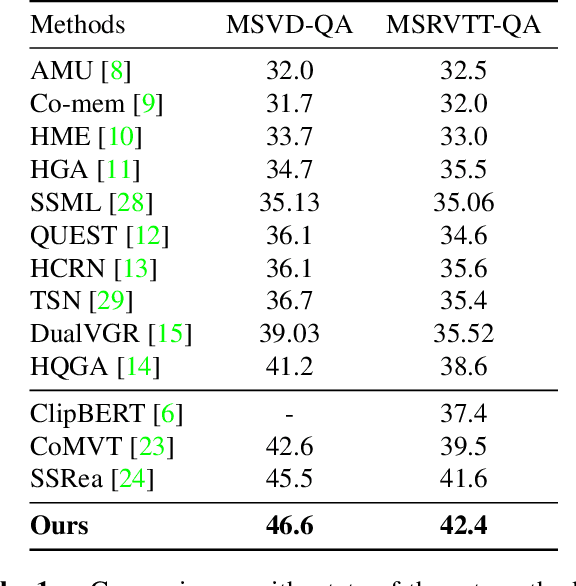
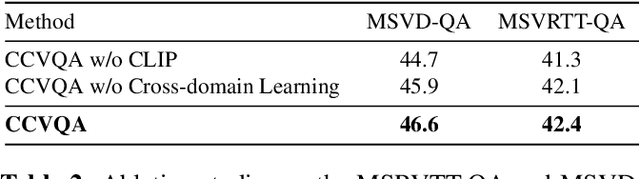
Cross-modal learning of video and text plays a key role in Video Question Answering (VideoQA). In this paper, we propose a visual-text attention mechanism to utilize the Contrastive Language-Image Pre-training (CLIP) trained on lots of general domain language-image pairs to guide the cross-modal learning for VideoQA. Specifically, we first extract video features using a TimeSformer and text features using a BERT from the target application domain, and utilize CLIP to extract a pair of visual-text features from the general-knowledge domain through the domain-specific learning. We then propose a Cross-domain Learning to extract the attention information between visual and linguistic features across the target domain and general domain. The set of CLIP-guided visual-text features are integrated to predict the answer. The proposed method is evaluated on MSVD-QA and MSRVTT-QA datasets, and outperforms state-of-the-art methods.
Human Activity Recognition Using 3D Orthogonally-projected EfficientNet on Radar Time-Range-Doppler Signature
Nov 24, 2021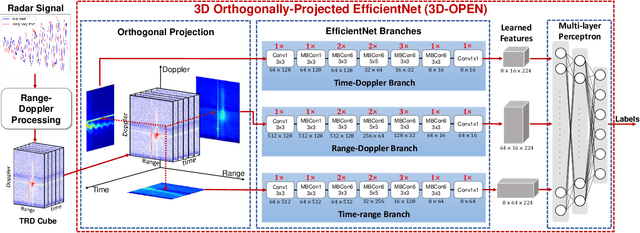
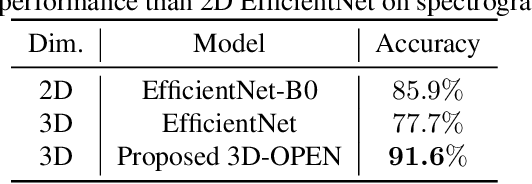
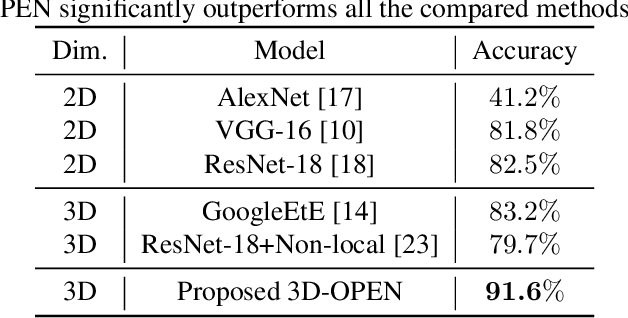

In radar activity recognition, 2D signal representations such as spectrogram, cepstrum and cadence velocity diagram are often utilized, while range information is often neglected. In this work, we propose to utilize the 3D time-range-Doppler (TRD) representation, and design a 3D Orthogonally-Projected EfficientNet (3D-OPEN) to effectively capture the discriminant information embedded in the 3D TRD cubes for accurate classification. The proposed model aggregates the discriminant information from three orthogonal planes projected from the 3D feature space. It alleviates the difficulty of 3D CNNs in exploiting sparse semantic abstractions directly from the high-dimensional 3D representation. The proposed method is evaluated on the Millimeter-Wave Radar Walking Dataset. It significantly and consistently outperforms the state-of-the-art methods for radar activity recognition.
A Data Augmentation Method by Mixing Up Negative Candidate Answers for Solving Raven's Progressive Matrices
Mar 09, 2021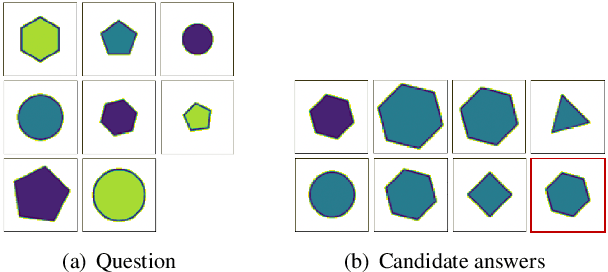

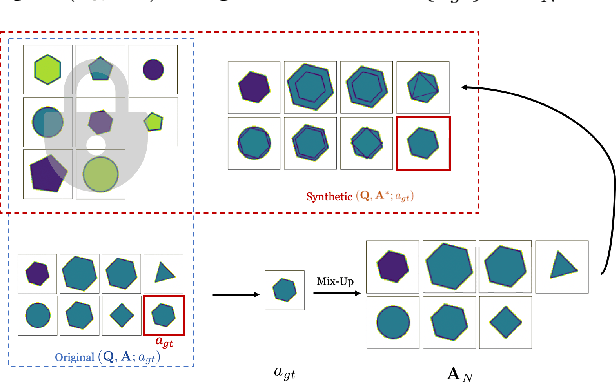
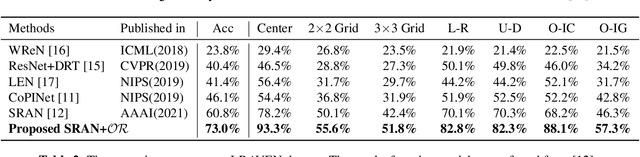
Raven's Progressive Matrices (RPMs) are frequently-used in testing human's visual reasoning ability. Recently developed RPM-like datasets and solution models transfer this kind of problems from cognitive science to computer science. In view of the poor generalization performance due to insufficient samples in RPM datasets, we propose a data augmentation strategy by image mix-up, which is generalizable to a variety of multiple-choice problems, especially for image-based RPM-like problems. By focusing on potential functionalities of negative candidate answers, the visual reasoning capability of the model is enhanced. By applying the proposed data augmentation method, we achieve significant and consistent improvement on various RPM-like datasets compared with the state-of-the-art models.