 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNuGrounding: A Multi-View 3D Visual Grounding Framework in Autonomous Driving
Mar 28, 2025Multi-view 3D visual grounding is critical for autonomous driving vehicles to interpret natural languages and localize target objects in complex environments. However, existing datasets and methods suffer from coarse-grained language instructions, and inadequate integration of 3D geometric reasoning with linguistic comprehension. To this end, we introduce NuGrounding, the first large-scale benchmark for multi-view 3D visual grounding in autonomous driving. We present a Hierarchy of Grounding (HoG) method to construct NuGrounding to generate hierarchical multi-level instructions, ensuring comprehensive coverage of human instruction patterns. To tackle this challenging dataset, we propose a novel paradigm that seamlessly combines instruction comprehension abilities of multi-modal LLMs (MLLMs) with precise localization abilities of specialist detection models. Our approach introduces two decoupled task tokens and a context query to aggregate 3D geometric information and semantic instructions, followed by a fusion decoder to refine spatial-semantic feature fusion for precise localization. Extensive experiments demonstrate that our method significantly outperforms the baselines adapted from representative 3D scene understanding methods by a significant margin and achieves 0.59 in precision and 0.64 in recall, with improvements of 50.8% and 54.7%.
Forging Vision Foundation Models for Autonomous Driving: Challenges, Methodologies, and Opportunities
Jan 16, 2024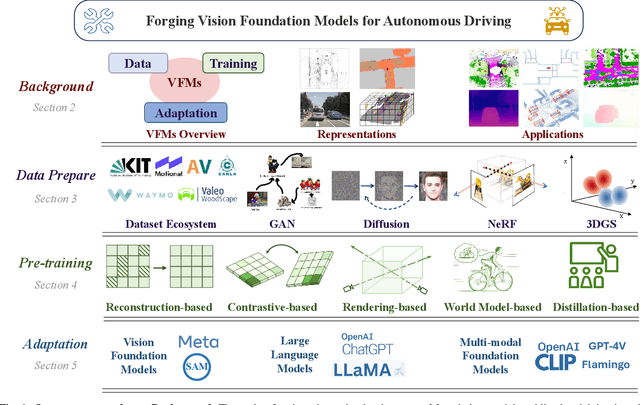
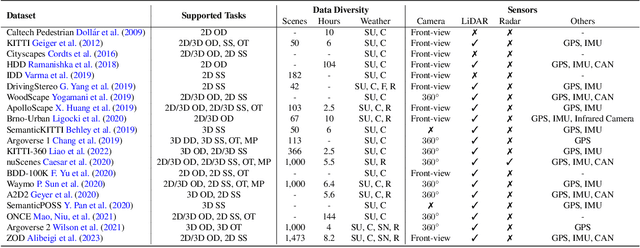
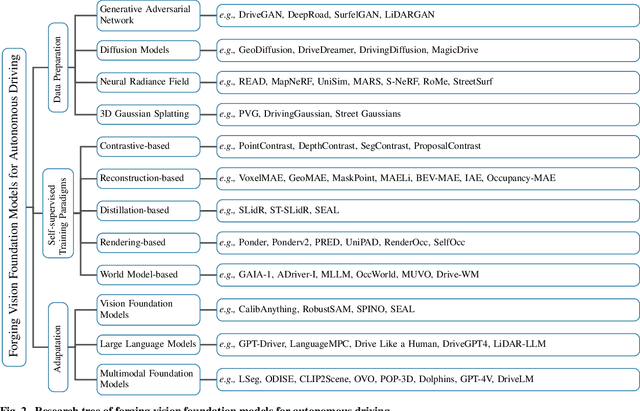

The rise of large foundation models, trained on extensive datasets, is revolutionizing the field of AI. Models such as SAM, DALL-E2, and GPT-4 showcase their adaptability by extracting intricate patterns and performing effectively across diverse tasks, thereby serving as potent building blocks for a wide range of AI applications. Autonomous driving, a vibrant front in AI applications, remains challenged by the lack of dedicated vision foundation models (VFMs). The scarcity of comprehensive training data, the need for multi-sensor integration, and the diverse task-specific architectures pose significant obstacles to the development of VFMs in this field. This paper delves into the critical challenge of forging VFMs tailored specifically for autonomous driving, while also outlining future directions. Through a systematic analysis of over 250 papers, we dissect essential techniques for VFM development, including data preparation, pre-training strategies, and downstream task adaptation. Moreover, we explore key advancements such as NeRF, diffusion models, 3D Gaussian Splatting, and world models, presenting a comprehensive roadmap for future research. To empower researchers, we have built and maintained https://github.com/zhanghm1995/Forge_VFM4AD, an open-access repository constantly updated with the latest advancements in forging VFMs for autonomous driving.
UCC: Uncertainty guided Cross-head Co-training for Semi-Supervised Semantic Segmentation
May 20, 2022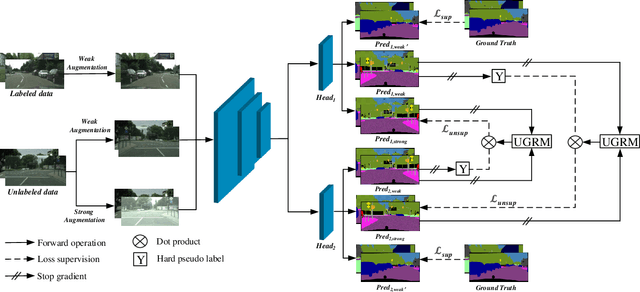
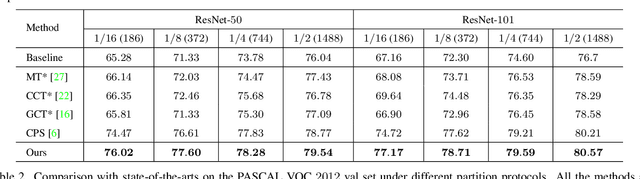

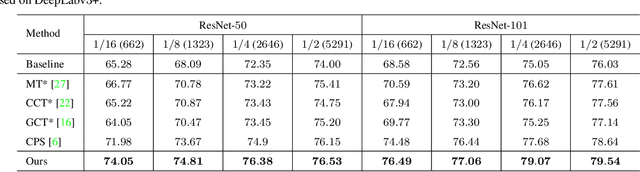
Deep neural networks (DNNs) have witnessed great successes in semantic segmentation, which requires a large number of labeled data for training. We present a novel learning framework called Uncertainty guided Cross-head Co-training (UCC) for semi-supervised semantic segmentation. Our framework introduces weak and strong augmentations within a shared encoder to achieve co-training, which naturally combines the benefits of consistency and self-training. Every segmentation head interacts with its peers and, the weak augmentation result is used for supervising the strong. The consistency training samples' diversity can be boosted by Dynamic Cross-Set Copy-Paste (DCSCP), which also alleviates the distribution mismatch and class imbalance problems. Moreover, our proposed Uncertainty Guided Re-weight Module (UGRM) enhances the self-training pseudo labels by suppressing the effect of the low-quality pseudo labels from its peer via modeling uncertainty. Extensive experiments on Cityscapes and PASCAL VOC 2012 demonstrate the effectiveness of our UCC. Our approach significantly outperforms other state-of-the-art semi-supervised semantic segmentation methods. It achieves 77.17$\%$, 76.49$\%$ mIoU on Cityscapes and PASCAL VOC 2012 datasets respectively under 1/16 protocols, which are +10.1$\%$, +7.91$\%$ better than the supervised baseline.
Focus on Local: Detecting Lane Marker from Bottom Up via Key Point
May 28, 2021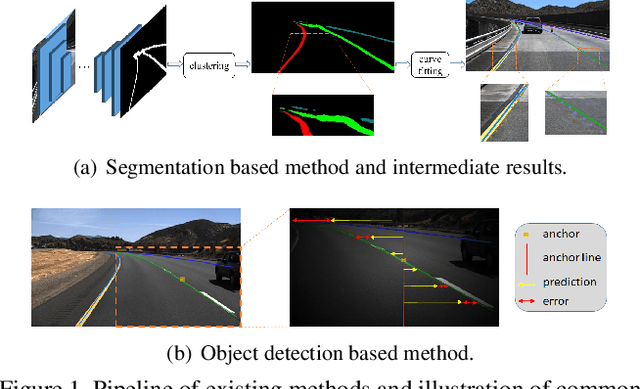
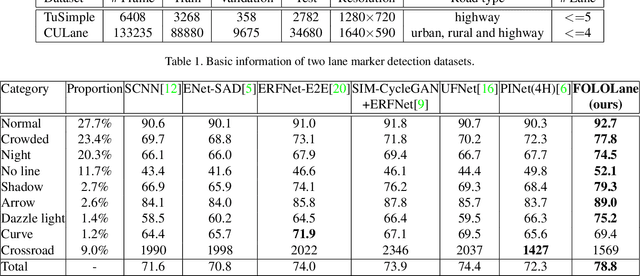
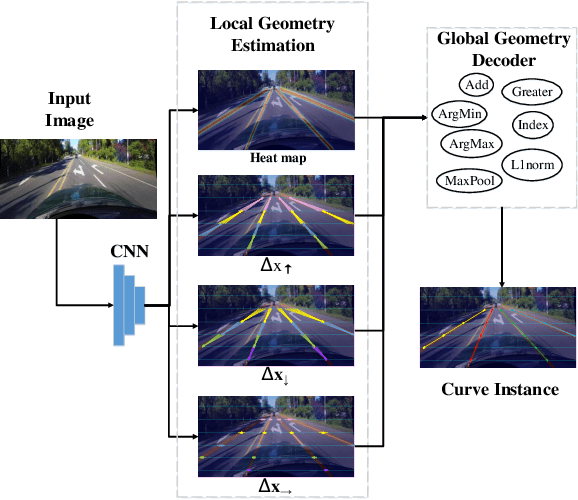

Mainstream lane marker detection methods are implemented by predicting the overall structure and deriving parametric curves through post-processing. Complex lane line shapes require high-dimensional output of CNNs to model global structures, which further increases the demand for model capacity and training data. In contrast, the locality of a lane marker has finite geometric variations and spatial coverage. We propose a novel lane marker detection solution, FOLOLane, that focuses on modeling local patterns and achieving prediction of global structures in a bottom-up manner. Specifically, the CNN models lowcomplexity local patterns with two separate heads, the first one predicts the existence of key points, and the second refines the location of key points in the local range and correlates key points of the same lane line. The locality of the task is consistent with the limited FOV of the feature in CNN, which in turn leads to more stable training and better generalization. In addition, an efficiency-oriented decoding algorithm was proposed as well as a greedy one, which achieving 36% runtime gains at the cost of negligible performance degradation. Both of the two decoders integrated local information into the global geometry of lane markers. In the absence of a complex network architecture design, the proposed method greatly outperforms all existing methods on public datasets while achieving the best state-of-the-art results and real-time processing simultaneously.
Analytics and Machine Learning in Vehicle Routing Research
Feb 19, 2021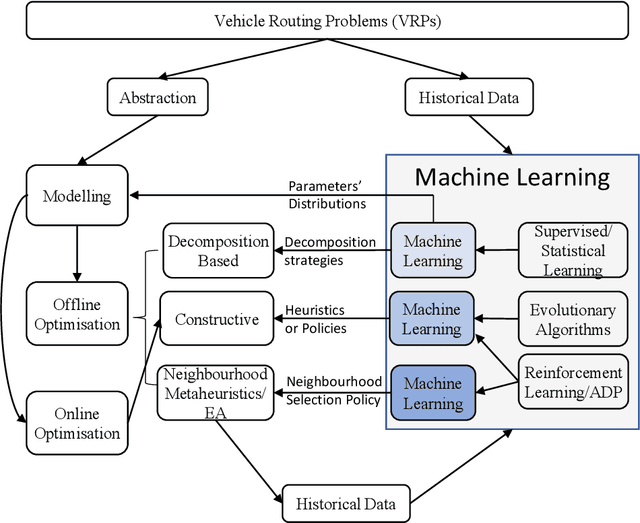
The Vehicle Routing Problem (VRP) is one of the most intensively studied combinatorial optimisation problems for which numerous models and algorithms have been proposed. To tackle the complexities, uncertainties and dynamics involved in real-world VRP applications, Machine Learning (ML) methods have been used in combination with analytical approaches to enhance problem formulations and algorithmic performance across different problem solving scenarios. However, the relevant papers are scattered in several traditional research fields with very different, sometimes confusing, terminologies. This paper presents a first, comprehensive review of hybrid methods that combine analytical techniques with ML tools in addressing VRP problems. Specifically, we review the emerging research streams on ML-assisted VRP modelling and ML-assisted VRP optimisation. We conclude that ML can be beneficial in enhancing VRP modelling, and improving the performance of algorithms for both online and offline VRP optimisations. Finally, challenges and future opportunities of VRP research are discussed.