 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNuGrounding: A Multi-View 3D Visual Grounding Framework in Autonomous Driving
Mar 28, 2025Multi-view 3D visual grounding is critical for autonomous driving vehicles to interpret natural languages and localize target objects in complex environments. However, existing datasets and methods suffer from coarse-grained language instructions, and inadequate integration of 3D geometric reasoning with linguistic comprehension. To this end, we introduce NuGrounding, the first large-scale benchmark for multi-view 3D visual grounding in autonomous driving. We present a Hierarchy of Grounding (HoG) method to construct NuGrounding to generate hierarchical multi-level instructions, ensuring comprehensive coverage of human instruction patterns. To tackle this challenging dataset, we propose a novel paradigm that seamlessly combines instruction comprehension abilities of multi-modal LLMs (MLLMs) with precise localization abilities of specialist detection models. Our approach introduces two decoupled task tokens and a context query to aggregate 3D geometric information and semantic instructions, followed by a fusion decoder to refine spatial-semantic feature fusion for precise localization. Extensive experiments demonstrate that our method significantly outperforms the baselines adapted from representative 3D scene understanding methods by a significant margin and achieves 0.59 in precision and 0.64 in recall, with improvements of 50.8% and 54.7%.
External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
Feb 26, 2025



Ads recommendation is a prominent service of online advertising systems and has been actively studied. Recent studies indicate that scaling-up and advanced design of the recommendation model can bring significant performance improvement. However, with a larger model scale, such prior studies have a significantly increasing gap from industry as they often neglect two fundamental challenges in industrial-scale applications. First, training and inference budgets are restricted for the model to be served, exceeding which may incur latency and impair user experience. Second, large-volume data arrive in a streaming mode with data distributions dynamically shifting, as new users/ads join and existing users/ads leave the system. We propose the External Large Foundation Model (ExFM) framework to address the overlooked challenges. Specifically, we develop external distillation and a data augmentation system (DAS) to control the computational cost of training/inference while maintaining high performance. We design the teacher in a way like a foundation model (FM) that can serve multiple students as vertical models (VMs) to amortize its building cost. We propose Auxiliary Head and Student Adapter to mitigate the data distribution gap between FM and VMs caused by the streaming data issue. Comprehensive experiments on internal industrial-scale applications and public datasets demonstrate significant performance gain by ExFM.
A space-decoupling framework for optimization on bounded-rank matrices with orthogonally invariant constraints
Jan 23, 2025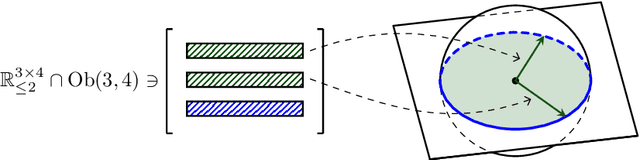
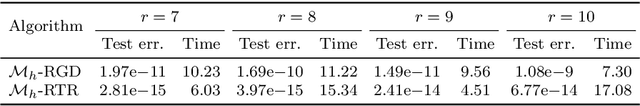

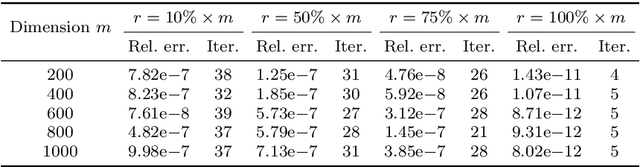
Imposing additional constraints on low-rank optimization has garnered growing interest. However, the geometry of coupled constraints hampers the well-developed low-rank structure and makes the problem intricate. To this end, we propose a space-decoupling framework for optimization on bounded-rank matrices with orthogonally invariant constraints. The ``space-decoupling" is reflected in several ways. We show that the tangent cone of coupled constraints is the intersection of tangent cones of each constraint. Moreover, we decouple the intertwined bounded-rank and orthogonally invariant constraints into two spaces, leading to optimization on a smooth manifold. Implementing Riemannian algorithms on this manifold is painless as long as the geometry of additional constraints is known. In addition, we unveil the equivalence between the reformulated problem and the original problem. Numerical experiments on real-world applications -- spherical data fitting, graph similarity measuring, low-rank SDP, model reduction of Markov processes, reinforcement learning, and deep learning -- validate the superiority of the proposed framework.
AdaSkip: Adaptive Sublayer Skipping for Accelerating Long-Context LLM Inference
Jan 04, 2025



Long-context large language models (LLMs) inference is increasingly critical, motivating a number of studies devoted to alleviating the substantial storage and computational costs in such scenarios. Layer-wise skipping methods are promising optimizations but rarely explored in long-context inference. We observe that existing layer-wise skipping strategies have several limitations when applied in long-context inference, including the inability to adapt to model and context variability, disregard for sublayer significance, and inapplicability for the prefilling phase. This paper proposes \sysname, an adaptive sublayer skipping method specifically designed for long-context inference. \sysname adaptively identifies less important layers by leveraging on-the-fly similarity information, enables sublayer-wise skipping, and accelerates both the prefilling and decoding phases. The effectiveness of \sysname is demonstrated through extensive experiments on various long-context benchmarks and models, showcasing its superior inference performance over existing baselines.
Bilevel reinforcement learning via the development of hyper-gradient without lower-level convexity
May 30, 2024

Bilevel reinforcement learning (RL), which features intertwined two-level problems, has attracted growing interest recently. The inherent non-convexity of the lower-level RL problem is, however, to be an impediment to developing bilevel optimization methods. By employing the fixed point equation associated with the regularized RL, we characterize the hyper-gradient via fully first-order information, thus circumventing the assumption of lower-level convexity. This, remarkably, distinguishes our development of hyper-gradient from the general AID-based bilevel frameworks since we take advantage of the specific structure of RL problems. Moreover, we propose both model-based and model-free bilevel reinforcement learning algorithms, facilitated by access to the fully first-order hyper-gradient. Both algorithms are provable to enjoy the convergence rate $\mathcal{O}(\epsilon^{-1})$. To the best of our knowledge, this is the first time that AID-based bilevel RL gets rid of additional assumptions on the lower-level problem. In addition, numerical experiments demonstrate that the hyper-gradient indeed serves as an integration of exploitation and exploration.
Optimization without retraction on the random generalized Stiefel manifold
May 02, 2024



Optimization over the set of matrices that satisfy $X^\top B X = I_p$, referred to as the generalized Stiefel manifold, appears in many applications involving sampled covariance matrices such as canonical correlation analysis (CCA), independent component analysis (ICA), and the generalized eigenvalue problem (GEVP). Solving these problems is typically done by iterative methods, such as Riemannian approaches, which require a computationally expensive eigenvalue decomposition involving fully formed $B$. We propose a cheap stochastic iterative method that solves the optimization problem while having access only to a random estimate of the feasible set. Our method does not enforce the constraint in every iteration exactly, but instead it produces iterations that converge to a critical point on the generalized Stiefel manifold defined in expectation. The method has lower per-iteration cost, requires only matrix multiplications, and has the same convergence rates as its Riemannian counterparts involving the full matrix $B$. Experiments demonstrate its effectiveness in various machine learning applications involving generalized orthogonality constraints, including CCA, ICA, and GEVP.
LancBiO: dynamic Lanczos-aided bilevel optimization via Krylov subspace
Apr 04, 2024



Bilevel optimization, with broad applications in machine learning, has an intricate hierarchical structure. Gradient-based methods have emerged as a common approach to large-scale bilevel problems. However, the computation of the hyper-gradient, which involves a Hessian inverse vector product, confines the efficiency and is regarded as a bottleneck. To circumvent the inverse, we construct a sequence of low-dimensional approximate Krylov subspaces with the aid of the Lanczos process. As a result, the constructed subspace is able to dynamically and incrementally approximate the Hessian inverse vector product with less effort and thus leads to a favorable estimate of the hyper-gradient. Moreover, we propose a~provable subspace-based framework for bilevel problems where one central step is to solve a small-size tridiagonal linear system. To the best of our knowledge, this is the first time that subspace techniques are incorporated into bilevel optimization. This successful trial not only enjoys $\mathcal{O}(\epsilon^{-1})$ convergence rate but also demonstrates efficiency in a synthetic problem and two deep learning tasks.
AttentionStore: Cost-effective Attention Reuse across Multi-turn Conversations in Large Language Model Serving
Mar 23, 2024Interacting with humans through multi-turn conversations is a fundamental feature of large language models (LLMs). However, existing LLM serving engines for executing multi-turn conversations are inefficient due to the need to repeatedly compute the key-value (KV) caches of historical tokens, incurring high serving costs. To address the problem, this paper proposes AttentionStore, a new attention mechanism that enables the reuse of KV caches (i.e., attention reuse) across multi-turn conversations, significantly reducing the repetitive computation overheads. AttentionStore maintains a hierarchical KV caching system that leverages cost-effective memory/storage mediums to save KV caches for all requests. To reduce KV cache access overheads from slow mediums, AttentionStore employs layer-wise pre-loading and asynchronous saving schemes to overlap the KV cache access with the GPU computation. To ensure that the KV caches to be accessed are placed in the fastest hierarchy, AttentionStore employs scheduler-aware fetching and eviction schemes to consciously place the KV caches in different layers based on the hints from the inference job scheduler. To avoid the invalidation of the saved KV caches incurred by context window overflow, AttentionStore enables the saved KV caches to remain valid via decoupling the positional encoding and effectively truncating the KV caches. Extensive experimental results demonstrate that AttentionStore significantly decreases the time to the first token (TTFT) by up to 88%, improves the prompt prefilling throughput by 8.2$\times$ for multi-turn conversations, and reduces the end-to-end inference cost by up to 56%. For long sequence inference, AttentionStore reduces the TTFT by up to 95% and improves the prompt prefilling throughput by 22$\times$.
Forging Vision Foundation Models for Autonomous Driving: Challenges, Methodologies, and Opportunities
Jan 16, 2024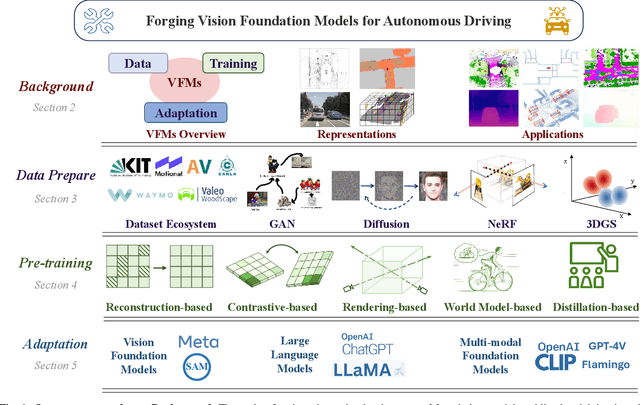
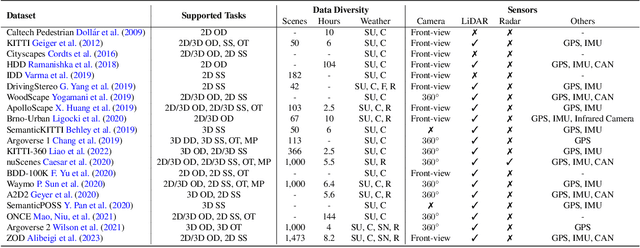
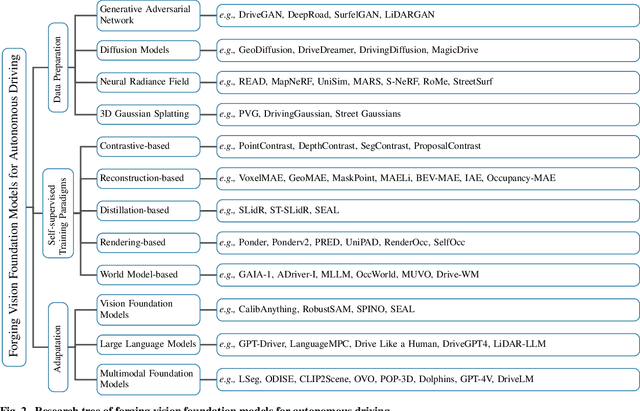

The rise of large foundation models, trained on extensive datasets, is revolutionizing the field of AI. Models such as SAM, DALL-E2, and GPT-4 showcase their adaptability by extracting intricate patterns and performing effectively across diverse tasks, thereby serving as potent building blocks for a wide range of AI applications. Autonomous driving, a vibrant front in AI applications, remains challenged by the lack of dedicated vision foundation models (VFMs). The scarcity of comprehensive training data, the need for multi-sensor integration, and the diverse task-specific architectures pose significant obstacles to the development of VFMs in this field. This paper delves into the critical challenge of forging VFMs tailored specifically for autonomous driving, while also outlining future directions. Through a systematic analysis of over 250 papers, we dissect essential techniques for VFM development, including data preparation, pre-training strategies, and downstream task adaptation. Moreover, we explore key advancements such as NeRF, diffusion models, 3D Gaussian Splatting, and world models, presenting a comprehensive roadmap for future research. To empower researchers, we have built and maintained https://github.com/zhanghm1995/Forge_VFM4AD, an open-access repository constantly updated with the latest advancements in forging VFMs for autonomous driving.
Segment Anything in Defect Detection
Nov 17, 2023



Defect detection plays a crucial role in infrared non-destructive testing systems, offering non-contact, safe, and efficient inspection capabilities. However, challenges such as low resolution, high noise, and uneven heating in infrared thermal images hinder comprehensive and accurate defect detection. In this study, we propose DefectSAM, a novel approach for segmenting defects on highly noisy thermal images based on the widely adopted model, Segment Anything (SAM)\cite{kirillov2023segany}. Harnessing the power of a meticulously curated dataset generated through labor-intensive lab experiments and valuable prompts from experienced experts, DefectSAM surpasses existing state-of-the-art segmentation algorithms and achieves significant improvements in defect detection rates. Notably, DefectSAM excels in detecting weaker and smaller defects on complex and irregular surfaces, reducing the occurrence of missed detections and providing more accurate defect size estimations. Experimental studies conducted on various materials have validated the effectiveness of our solutions in defect detection, which hold significant potential to expedite the evolution of defect detection tools, enabling enhanced inspection capabilities and accuracy in defect identification.