 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA space-decoupling framework for optimization on bounded-rank matrices with orthogonally invariant constraints
Jan 23, 2025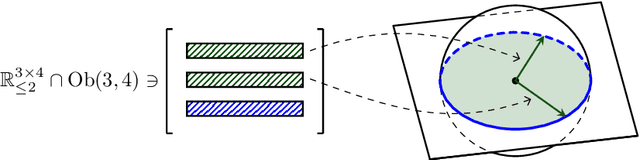
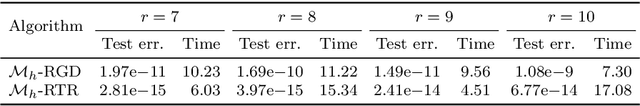

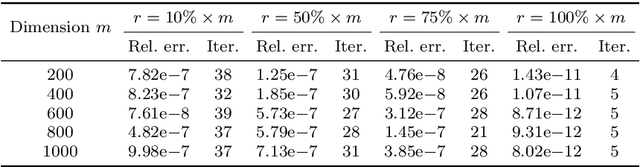
Imposing additional constraints on low-rank optimization has garnered growing interest. However, the geometry of coupled constraints hampers the well-developed low-rank structure and makes the problem intricate. To this end, we propose a space-decoupling framework for optimization on bounded-rank matrices with orthogonally invariant constraints. The ``space-decoupling" is reflected in several ways. We show that the tangent cone of coupled constraints is the intersection of tangent cones of each constraint. Moreover, we decouple the intertwined bounded-rank and orthogonally invariant constraints into two spaces, leading to optimization on a smooth manifold. Implementing Riemannian algorithms on this manifold is painless as long as the geometry of additional constraints is known. In addition, we unveil the equivalence between the reformulated problem and the original problem. Numerical experiments on real-world applications -- spherical data fitting, graph similarity measuring, low-rank SDP, model reduction of Markov processes, reinforcement learning, and deep learning -- validate the superiority of the proposed framework.
Bilevel reinforcement learning via the development of hyper-gradient without lower-level convexity
May 30, 2024

Bilevel reinforcement learning (RL), which features intertwined two-level problems, has attracted growing interest recently. The inherent non-convexity of the lower-level RL problem is, however, to be an impediment to developing bilevel optimization methods. By employing the fixed point equation associated with the regularized RL, we characterize the hyper-gradient via fully first-order information, thus circumventing the assumption of lower-level convexity. This, remarkably, distinguishes our development of hyper-gradient from the general AID-based bilevel frameworks since we take advantage of the specific structure of RL problems. Moreover, we propose both model-based and model-free bilevel reinforcement learning algorithms, facilitated by access to the fully first-order hyper-gradient. Both algorithms are provable to enjoy the convergence rate $\mathcal{O}(\epsilon^{-1})$. To the best of our knowledge, this is the first time that AID-based bilevel RL gets rid of additional assumptions on the lower-level problem. In addition, numerical experiments demonstrate that the hyper-gradient indeed serves as an integration of exploitation and exploration.
LancBiO: dynamic Lanczos-aided bilevel optimization via Krylov subspace
Apr 04, 2024



Bilevel optimization, with broad applications in machine learning, has an intricate hierarchical structure. Gradient-based methods have emerged as a common approach to large-scale bilevel problems. However, the computation of the hyper-gradient, which involves a Hessian inverse vector product, confines the efficiency and is regarded as a bottleneck. To circumvent the inverse, we construct a sequence of low-dimensional approximate Krylov subspaces with the aid of the Lanczos process. As a result, the constructed subspace is able to dynamically and incrementally approximate the Hessian inverse vector product with less effort and thus leads to a favorable estimate of the hyper-gradient. Moreover, we propose a~provable subspace-based framework for bilevel problems where one central step is to solve a small-size tridiagonal linear system. To the best of our knowledge, this is the first time that subspace techniques are incorporated into bilevel optimization. This successful trial not only enjoys $\mathcal{O}(\epsilon^{-1})$ convergence rate but also demonstrates efficiency in a synthetic problem and two deep learning tasks.
Linear convergence of Nesterov-1983 with the strong convexity
Jun 16, 2023


For modern gradient-based optimization, a developmental landmark is Nesterov's accelerated gradient descent method, which is proposed in [Nesterov, 1983], so shorten as Nesterov-1983. Afterward, one of the important progresses is its proximal generalization, named the fast iterative shrinkage-thresholding algorithm (FISTA), which is widely used in image science and engineering. However, it is unknown whether both Nesterov-1983 and FISTA converge linearly on the strongly convex function, which has been listed as the open problem in the comprehensive review [Chambolle and Pock, 2016, Appendix B]. In this paper, we answer this question by the use of the high-resolution differential equation framework. Along with the phase-space representation previously adopted, the key difference here in constructing the Lyapunov function is that the coefficient of the kinetic energy varies with the iteration. Furthermore, we point out that the linear convergence of both the two algorithms above has no dependence on the parameter $r$ on the strongly convex function. Meanwhile, it is also obtained that the proximal subgradient norm converges linearly.
On Underdamped Nesterov's Acceleration
Apr 28, 2023The high-resolution differential equation framework has been proven to be tailor-made for Nesterov's accelerated gradient descent method~(\texttt{NAG}) and its proximal correspondence -- the class of faster iterative shrinkage thresholding algorithms (FISTA). However, the systems of theories is not still complete, since the underdamped case ($r < 2$) has not been included. In this paper, based on the high-resolution differential equation framework, we construct the new Lyapunov functions for the underdamped case, which is motivated by the power of the time $t^{\gamma}$ or the iteration $k^{\gamma}$ in the mixed term. When the momentum parameter $r$ is $2$, the new Lyapunov functions are identical to the previous ones. These new proofs do not only include the convergence rate of the objective value previously obtained according to the low-resolution differential equation framework but also characterize the convergence rate of the minimal gradient norm square. All the convergence rates obtained for the underdamped case are continuously dependent on the parameter $r$. In addition, it is observed that the high-resolution differential equation approximately simulates the convergence behavior of~\texttt{NAG} for the critical case $r=-1$, while the low-resolution differential equation degenerates to the conservative Newton's equation. The high-resolution differential equation framework also theoretically characterizes the convergence rates, which are consistent with that obtained for the underdamped case with $r=-1$.
Linear Convergence of ISTA and FISTA
Dec 13, 2022



In this paper, we revisit the class of iterative shrinkage-thresholding algorithms (ISTA) for solving the linear inverse problem with sparse representation, which arises in signal and image processing. It is shown in the numerical experiment to deblur an image that the convergence behavior in the logarithmic-scale ordinate tends to be linear instead of logarithmic, approximating to be flat. Making meticulous observations, we find that the previous assumption for the smooth part to be convex weakens the least-square model. Specifically, assuming the smooth part to be strongly convex is more reasonable for the least-square model, even though the image matrix is probably ill-conditioned. Furthermore, we improve the pivotal inequality tighter for composite optimization with the smooth part to be strongly convex instead of general convex, which is first found in [Li et al., 2022]. Based on this pivotal inequality, we generalize the linear convergence to composite optimization in both the objective value and the squared proximal subgradient norm. Meanwhile, we set a simple ill-conditioned matrix which is easy to compute the singular values instead of the original blur matrix. The new numerical experiment shows the proximal generalization of Nesterov's accelerated gradient descent (NAG) for the strongly convex function has a faster linear convergence rate than ISTA. Based on the tighter pivotal inequality, we also generalize the faster linear convergence rate to composite optimization, in both the objective value and the squared proximal subgradient norm, by taking advantage of the well-constructed Lyapunov function with a slight modification and the phase-space representation based on the high-resolution differential equation framework from the implicit-velocity scheme.
Revisiting the acceleration phenomenon via high-resolution differential equations
Dec 12, 2022Nesterov's accelerated gradient descent (NAG) is one of the milestones in the history of first-order algorithms. It was not successfully uncovered until the high-resolution differential equation framework was proposed in [Shi et al., 2022] that the mechanism behind the acceleration phenomenon is due to the gradient correction term. To deepen our understanding of the high-resolution differential equation framework on the convergence rate, we continue to investigate NAG for the $\mu$-strongly convex function based on the techniques of Lyapunov analysis and phase-space representation in this paper. First, we revisit the proof from the gradient-correction scheme. Similar to [Chen et al., 2022], the straightforward calculation simplifies the proof extremely and enlarges the step size to $s=1/L$ with minor modification. Meanwhile, the way of constructing Lyapunov functions is principled. Furthermore, we also investigate NAG from the implicit-velocity scheme. Due to the difference in the velocity iterates, we find that the Lyapunov function is constructed from the implicit-velocity scheme without the additional term and the calculation of iterative difference becomes simpler. Together with the optimal step size obtained, the high-resolution differential equation framework from the implicit-velocity scheme of NAG is perfect and outperforms the gradient-correction scheme.
Proximal Subgradient Norm Minimization of ISTA and FISTA
Nov 03, 2022

For first-order smooth optimization, the research on the acceleration phenomenon has a long-time history. Until recently, the mechanism leading to acceleration was not successfully uncovered by the gradient correction term and its equivalent implicit-velocity form. Furthermore, based on the high-resolution differential equation framework with the corresponding emerging techniques, phase-space representation and Lyapunov function, the squared gradient norm of Nesterov's accelerated gradient descent (\texttt{NAG}) method at an inverse cubic rate is discovered. However, this result cannot be directly generalized to composite optimization widely used in practice, e.g., the linear inverse problem with sparse representation. In this paper, we meticulously observe a pivotal inequality used in composite optimization about the step size $s$ and the Lipschitz constant $L$ and find that it can be improved tighter. We apply the tighter inequality discovered in the well-constructed Lyapunov function and then obtain the proximal subgradient norm minimization by the phase-space representation, regardless of gradient-correction or implicit-velocity. Furthermore, we demonstrate that the squared proximal subgradient norm for the class of iterative shrinkage-thresholding algorithms (ISTA) converges at an inverse square rate, and the squared proximal subgradient norm for the class of faster iterative shrinkage-thresholding algorithms (FISTA) is accelerated to convergence at an inverse cubic rate.
Gradient Norm Minimization of Nesterov Acceleration: $o(1/k^3)$
Sep 19, 2022In the history of first-order algorithms, Nesterov's accelerated gradient descent (NAG) is one of the milestones. However, the cause of the acceleration has been a mystery for a long time. It has not been revealed with the existence of gradient correction until the high-resolution differential equation framework proposed in [Shi et al., 2021]. In this paper, we continue to investigate the acceleration phenomenon. First, we provide a significantly simplified proof based on precise observation and a tighter inequality for $L$-smooth functions. Then, a new implicit-velocity high-resolution differential equation framework, as well as the corresponding implicit-velocity version of phase-space representation and Lyapunov function, is proposed to investigate the convergence behavior of the iterative sequence $\{x_k\}_{k=0}^{\infty}$ of NAG. Furthermore, from two kinds of phase-space representations, we find that the role played by gradient correction is equivalent to that by velocity included implicitly in the gradient, where the only difference comes from the iterative sequence $\{y_{k}\}_{k=0}^{\infty}$ replaced by $\{x_k\}_{k=0}^{\infty}$. Finally, for the open question of whether the gradient norm minimization of NAG has a faster rate $o(1/k^3)$, we figure out a positive answer with its proof. Meanwhile, a faster rate of objective value minimization $o(1/k^2)$ is shown for the case $r > 2$.