 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrioritizing Perception-Guided Self-Supervision: A New Paradigm for Causal Modeling in End-to-End Autonomous Driving
Nov 11, 2025End-to-end autonomous driving systems, predominantly trained through imitation learning, have demonstrated considerable effectiveness in leveraging large-scale expert driving data. Despite their success in open-loop evaluations, these systems often exhibit significant performance degradation in closed-loop scenarios due to causal confusion. This confusion is fundamentally exacerbated by the overreliance of the imitation learning paradigm on expert trajectories, which often contain unattributable noise and interfere with the modeling of causal relationships between environmental contexts and appropriate driving actions. To address this fundamental limitation, we propose Perception-Guided Self-Supervision (PGS) - a simple yet effective training paradigm that leverages perception outputs as the primary supervisory signals, explicitly modeling causal relationships in decision-making. The proposed framework aligns both the inputs and outputs of the decision-making module with perception results, such as lane centerlines and the predicted motions of surrounding agents, by introducing positive and negative self-supervision for the ego trajectory. This alignment is specifically designed to mitigate causal confusion arising from the inherent noise in expert trajectories. Equipped with perception-driven supervision, our method, built on a standard end-to-end architecture, achieves a Driving Score of 78.08 and a mean success rate of 48.64% on the challenging closed-loop Bench2Drive benchmark, significantly outperforming existing state-of-the-art methods, including those employing more complex network architectures and inference pipelines. These results underscore the effectiveness and robustness of the proposed PGS framework and point to a promising direction for addressing causal confusion and enhancing real-world generalization in autonomous driving.
NuGrounding: A Multi-View 3D Visual Grounding Framework in Autonomous Driving
Mar 28, 2025Multi-view 3D visual grounding is critical for autonomous driving vehicles to interpret natural languages and localize target objects in complex environments. However, existing datasets and methods suffer from coarse-grained language instructions, and inadequate integration of 3D geometric reasoning with linguistic comprehension. To this end, we introduce NuGrounding, the first large-scale benchmark for multi-view 3D visual grounding in autonomous driving. We present a Hierarchy of Grounding (HoG) method to construct NuGrounding to generate hierarchical multi-level instructions, ensuring comprehensive coverage of human instruction patterns. To tackle this challenging dataset, we propose a novel paradigm that seamlessly combines instruction comprehension abilities of multi-modal LLMs (MLLMs) with precise localization abilities of specialist detection models. Our approach introduces two decoupled task tokens and a context query to aggregate 3D geometric information and semantic instructions, followed by a fusion decoder to refine spatial-semantic feature fusion for precise localization. Extensive experiments demonstrate that our method significantly outperforms the baselines adapted from representative 3D scene understanding methods by a significant margin and achieves 0.59 in precision and 0.64 in recall, with improvements of 50.8% and 54.7%.
Motion Dreamer: Realizing Physically Coherent Video Generation through Scene-Aware Motion Reasoning
Nov 30, 2024



Recent numerous video generation models, also known as world models, have demonstrated the ability to generate plausible real-world videos. However, many studies have shown that these models often produce motion results lacking logical or physical coherence. In this paper, we revisit video generation models and find that single-stage approaches struggle to produce high-quality results while maintaining coherent motion reasoning. To address this issue, we propose \textbf{Motion Dreamer}, a two-stage video generation framework. In Stage I, the model generates an intermediate motion representation-such as a segmentation map or depth map-based on the input image and motion conditions, focusing solely on the motion itself. In Stage II, the model uses this intermediate motion representation as a condition to generate a high-detail video. By decoupling motion reasoning from high-fidelity video synthesis, our approach allows for more accurate and physically plausible motion generation. We validate the effectiveness of our approach on the Physion dataset and in autonomous driving scenarios. For example, given a single push, our model can synthesize the sequential toppling of a set of dominoes. Similarly, by varying the movements of ego-cars, our model can produce different effects on other vehicles. Our work opens new avenues in creating models that can reason about physical interactions in a more coherent and realistic manner.
DetDiffusion: Synergizing Generative and Perceptive Models for Enhanced Data Generation and Perception
Mar 20, 2024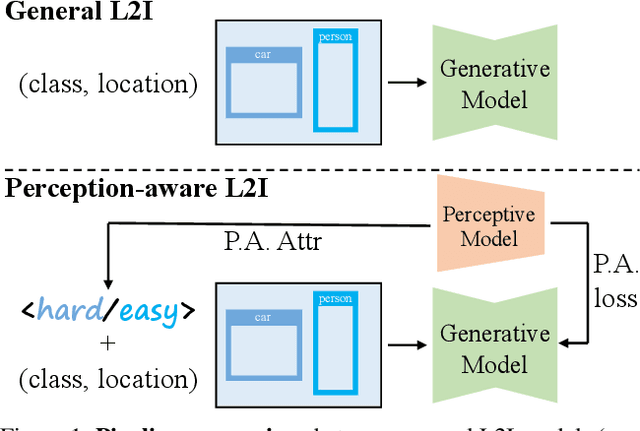
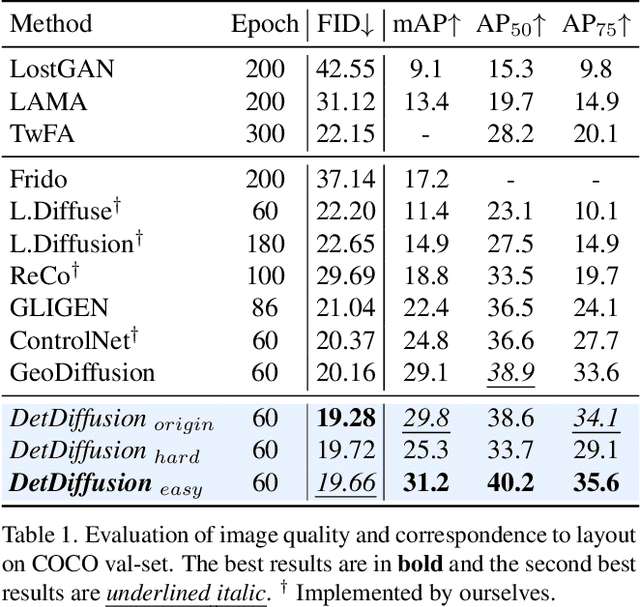
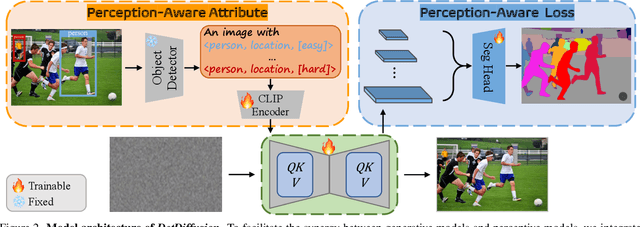
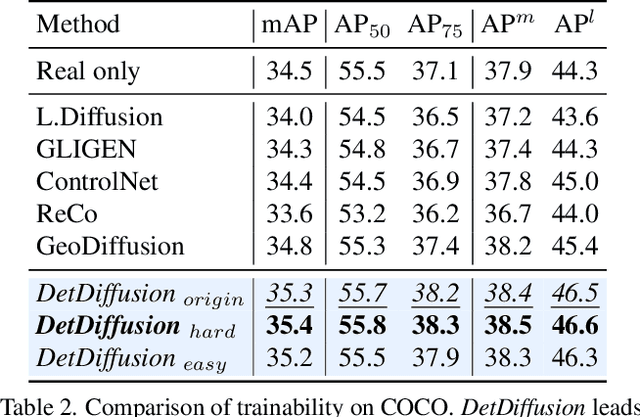
Current perceptive models heavily depend on resource-intensive datasets, prompting the need for innovative solutions. Leveraging recent advances in diffusion models, synthetic data, by constructing image inputs from various annotations, proves beneficial for downstream tasks. While prior methods have separately addressed generative and perceptive models, DetDiffusion, for the first time, harmonizes both, tackling the challenges in generating effective data for perceptive models. To enhance image generation with perceptive models, we introduce perception-aware loss (P.A. loss) through segmentation, improving both quality and controllability. To boost the performance of specific perceptive models, our method customizes data augmentation by extracting and utilizing perception-aware attribute (P.A. Attr) during generation. Experimental results from the object detection task highlight DetDiffusion's superior performance, establishing a new state-of-the-art in layout-guided generation. Furthermore, image syntheses from DetDiffusion can effectively augment training data, significantly enhancing downstream detection performance.
Forging Vision Foundation Models for Autonomous Driving: Challenges, Methodologies, and Opportunities
Jan 16, 2024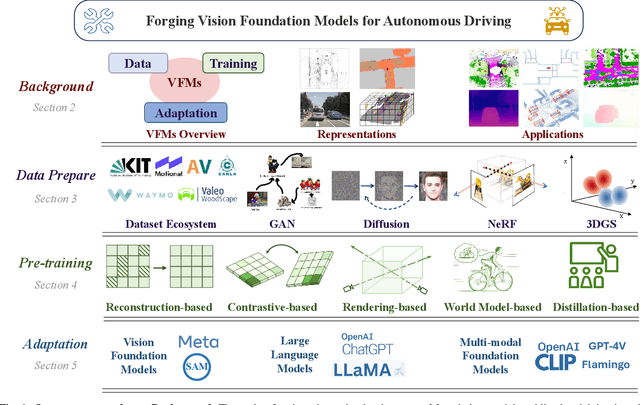
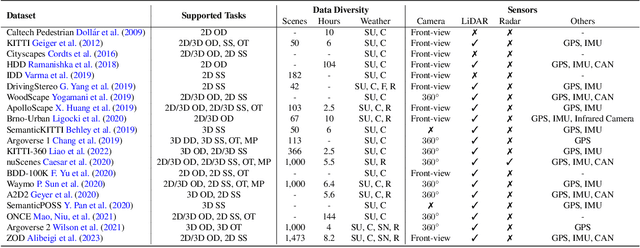
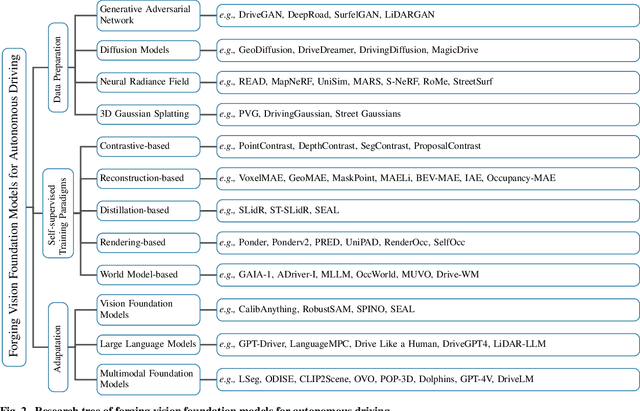

The rise of large foundation models, trained on extensive datasets, is revolutionizing the field of AI. Models such as SAM, DALL-E2, and GPT-4 showcase their adaptability by extracting intricate patterns and performing effectively across diverse tasks, thereby serving as potent building blocks for a wide range of AI applications. Autonomous driving, a vibrant front in AI applications, remains challenged by the lack of dedicated vision foundation models (VFMs). The scarcity of comprehensive training data, the need for multi-sensor integration, and the diverse task-specific architectures pose significant obstacles to the development of VFMs in this field. This paper delves into the critical challenge of forging VFMs tailored specifically for autonomous driving, while also outlining future directions. Through a systematic analysis of over 250 papers, we dissect essential techniques for VFM development, including data preparation, pre-training strategies, and downstream task adaptation. Moreover, we explore key advancements such as NeRF, diffusion models, 3D Gaussian Splatting, and world models, presenting a comprehensive roadmap for future research. To empower researchers, we have built and maintained https://github.com/zhanghm1995/Forge_VFM4AD, an open-access repository constantly updated with the latest advancements in forging VFMs for autonomous driving.
UCC: Uncertainty guided Cross-head Co-training for Semi-Supervised Semantic Segmentation
May 20, 2022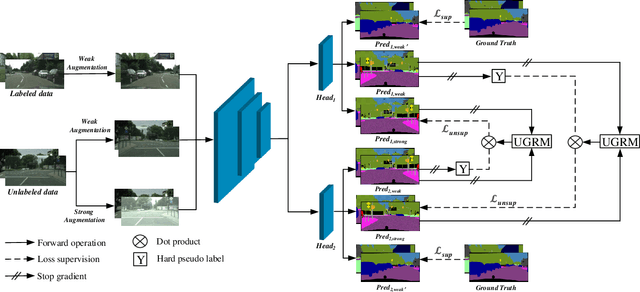
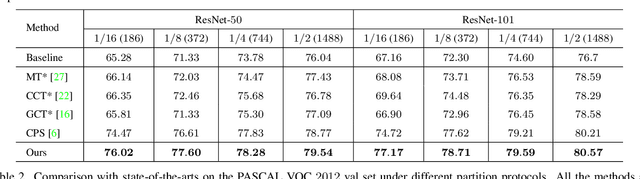

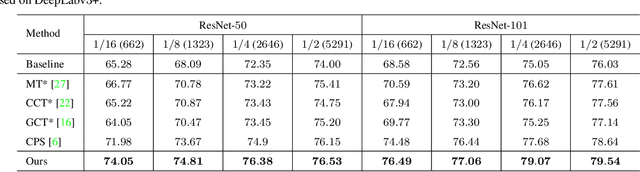
Deep neural networks (DNNs) have witnessed great successes in semantic segmentation, which requires a large number of labeled data for training. We present a novel learning framework called Uncertainty guided Cross-head Co-training (UCC) for semi-supervised semantic segmentation. Our framework introduces weak and strong augmentations within a shared encoder to achieve co-training, which naturally combines the benefits of consistency and self-training. Every segmentation head interacts with its peers and, the weak augmentation result is used for supervising the strong. The consistency training samples' diversity can be boosted by Dynamic Cross-Set Copy-Paste (DCSCP), which also alleviates the distribution mismatch and class imbalance problems. Moreover, our proposed Uncertainty Guided Re-weight Module (UGRM) enhances the self-training pseudo labels by suppressing the effect of the low-quality pseudo labels from its peer via modeling uncertainty. Extensive experiments on Cityscapes and PASCAL VOC 2012 demonstrate the effectiveness of our UCC. Our approach significantly outperforms other state-of-the-art semi-supervised semantic segmentation methods. It achieves 77.17$\%$, 76.49$\%$ mIoU on Cityscapes and PASCAL VOC 2012 datasets respectively under 1/16 protocols, which are +10.1$\%$, +7.91$\%$ better than the supervised baseline.
Diversity Matters: Fully Exploiting Depth Clues for Reliable Monocular 3D Object Detection
May 19, 2022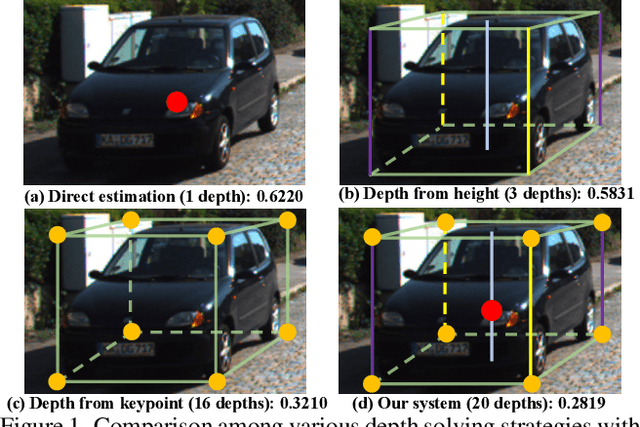
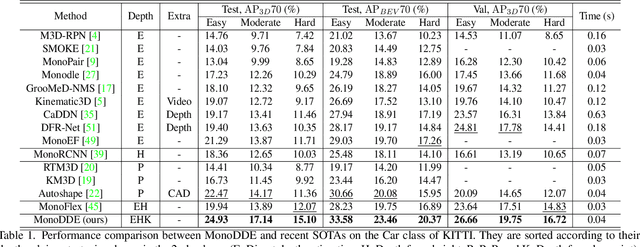
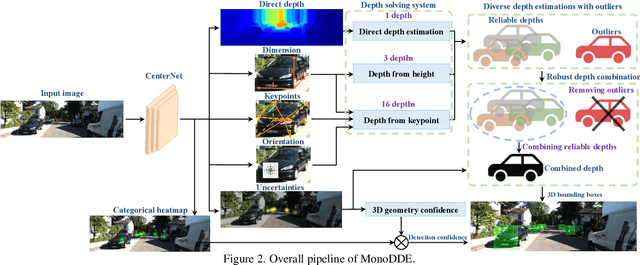
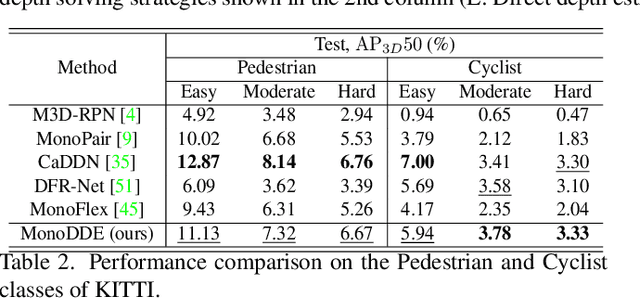
As an inherently ill-posed problem, depth estimation from single images is the most challenging part of monocular 3D object detection (M3OD). Many existing methods rely on preconceived assumptions to bridge the missing spatial information in monocular images, and predict a sole depth value for every object of interest. However, these assumptions do not always hold in practical applications. To tackle this problem, we propose a depth solving system that fully explores the visual clues from the subtasks in M3OD and generates multiple estimations for the depth of each target. Since the depth estimations rely on different assumptions in essence, they present diverse distributions. Even if some assumptions collapse, the estimations established on the remaining assumptions are still reliable. In addition, we develop a depth selection and combination strategy. This strategy is able to remove abnormal estimations caused by collapsed assumptions, and adaptively combine the remaining estimations into a single one. In this way, our depth solving system becomes more precise and robust. Exploiting the clues from multiple subtasks of M3OD and without introducing any extra information, our method surpasses the current best method by more than 20% relatively on the Moderate level of test split in the KITTI 3D object detection benchmark, while still maintaining real-time efficiency.