 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeFix: Boosting 3D Gaussian Splatting via Fine-Tuning-Free Diffusion Models
Jan 28, 2026Neural Radiance Fields and 3D Gaussian Splatting have advanced novel view synthesis, yet still rely on dense inputs and often degrade at extrapolated views. Recent approaches leverage generative models, such as diffusion models, to provide additional supervision, but face a trade-off between generalization and fidelity: fine-tuning diffusion models for artifact removal improves fidelity but risks overfitting, while fine-tuning-free methods preserve generalization but often yield lower fidelity. We introduce FreeFix, a fine-tuning-free approach that pushes the boundary of this trade-off by enhancing extrapolated rendering with pretrained image diffusion models. We present an interleaved 2D-3D refinement strategy, showing that image diffusion models can be leveraged for consistent refinement without relying on costly video diffusion models. Furthermore, we take a closer look at the guidance signal for 2D refinement and propose a per-pixel confidence mask to identify uncertain regions for targeted improvement. Experiments across multiple datasets show that FreeFix improves multi-frame consistency and achieves performance comparable to or surpassing fine-tuning-based methods, while retaining strong generalization ability.
EVolSplat4D: Efficient Volume-based Gaussian Splatting for 4D Urban Scene Synthesis
Jan 22, 2026Novel view synthesis (NVS) of static and dynamic urban scenes is essential for autonomous driving simulation, yet existing methods often struggle to balance reconstruction time with quality. While state-of-the-art neural radiance fields and 3D Gaussian Splatting approaches achieve photorealism, they often rely on time-consuming per-scene optimization. Conversely, emerging feed-forward methods frequently adopt per-pixel Gaussian representations, which lead to 3D inconsistencies when aggregating multi-view predictions in complex, dynamic environments. We propose EvolSplat4D, a feed-forward framework that moves beyond existing per-pixel paradigms by unifying volume-based and pixel-based Gaussian prediction across three specialized branches. For close-range static regions, we predict consistent geometry of 3D Gaussians over multiple frames directly from a 3D feature volume, complemented by a semantically-enhanced image-based rendering module for predicting their appearance. For dynamic actors, we utilize object-centric canonical spaces and a motion-adjusted rendering module to aggregate temporal features, ensuring stable 4D reconstruction despite noisy motion priors. Far-Field scenery is handled by an efficient per-pixel Gaussian branch to ensure full-scene coverage. Experimental results on the KITTI-360, KITTI, Waymo, and PandaSet datasets show that EvolSplat4D reconstructs both static and dynamic environments with superior accuracy and consistency, outperforming both per-scene optimization and state-of-the-art feed-forward baselines.
Spatial4D-Bench: A Versatile 4D Spatial Intelligence Benchmark
Dec 31, 20254D spatial intelligence involves perceiving and processing how objects move or change over time. Humans naturally possess 4D spatial intelligence, supporting a broad spectrum of spatial reasoning abilities. To what extent can Multimodal Large Language Models (MLLMs) achieve human-level 4D spatial intelligence? In this work, we present Spatial4D-Bench, a versatile 4D spatial intelligence benchmark designed to comprehensively assess the 4D spatial reasoning abilities of MLLMs. Unlike existing spatial intelligence benchmarks that are often small-scale or limited in diversity, Spatial4D-Bench provides a large-scale, multi-task evaluation benchmark consisting of ~40,000 question-answer pairs covering 18 well-defined tasks. We systematically organize these tasks into six cognitive categories: object understanding, scene understanding, spatial relationship understanding, spatiotemporal relationship understanding, spatial reasoning and spatiotemporal reasoning. Spatial4D-Bench thereby offers a structured and comprehensive benchmark for evaluating the spatial cognition abilities of MLLMs, covering a broad spectrum of tasks that parallel the versatility of human spatial intelligence. We benchmark various state-of-the-art open-source and proprietary MLLMs on Spatial4D-Bench and reveal their substantial limitations in a wide variety of 4D spatial reasoning aspects, such as route plan, action recognition, and physical plausibility reasoning. We hope that the findings provided in this work offer valuable insights to the community and that our benchmark can facilitate the development of more capable MLLMs toward human-level 4D spatial intelligence. More resources can be found on our project page.
Prioritizing Perception-Guided Self-Supervision: A New Paradigm for Causal Modeling in End-to-End Autonomous Driving
Nov 11, 2025End-to-end autonomous driving systems, predominantly trained through imitation learning, have demonstrated considerable effectiveness in leveraging large-scale expert driving data. Despite their success in open-loop evaluations, these systems often exhibit significant performance degradation in closed-loop scenarios due to causal confusion. This confusion is fundamentally exacerbated by the overreliance of the imitation learning paradigm on expert trajectories, which often contain unattributable noise and interfere with the modeling of causal relationships between environmental contexts and appropriate driving actions. To address this fundamental limitation, we propose Perception-Guided Self-Supervision (PGS) - a simple yet effective training paradigm that leverages perception outputs as the primary supervisory signals, explicitly modeling causal relationships in decision-making. The proposed framework aligns both the inputs and outputs of the decision-making module with perception results, such as lane centerlines and the predicted motions of surrounding agents, by introducing positive and negative self-supervision for the ego trajectory. This alignment is specifically designed to mitigate causal confusion arising from the inherent noise in expert trajectories. Equipped with perception-driven supervision, our method, built on a standard end-to-end architecture, achieves a Driving Score of 78.08 and a mean success rate of 48.64% on the challenging closed-loop Bench2Drive benchmark, significantly outperforming existing state-of-the-art methods, including those employing more complex network architectures and inference pipelines. These results underscore the effectiveness and robustness of the proposed PGS framework and point to a promising direction for addressing causal confusion and enhancing real-world generalization in autonomous driving.
MoVieDrive: Multi-Modal Multi-View Urban Scene Video Generation
Aug 20, 2025
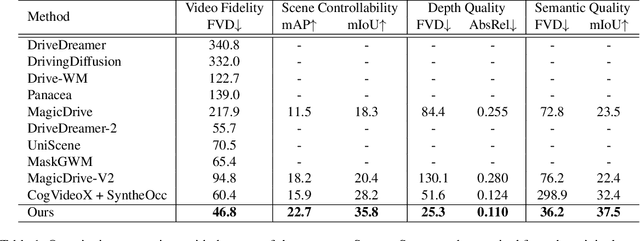
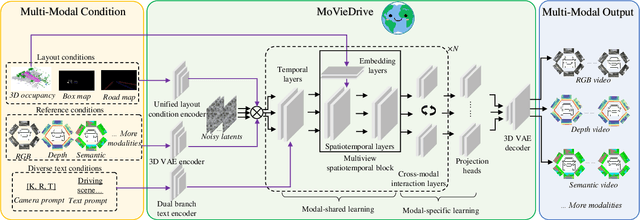
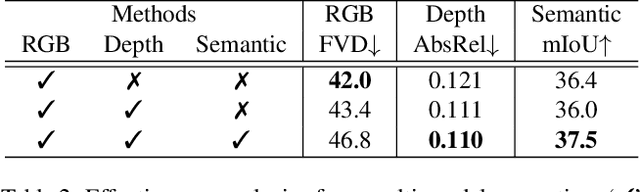
Video generation has recently shown superiority in urban scene synthesis for autonomous driving. Existing video generation approaches to autonomous driving primarily focus on RGB video generation and lack the ability to support multi-modal video generation. However, multi-modal data, such as depth maps and semantic maps, are crucial for holistic urban scene understanding in autonomous driving. Although it is feasible to use multiple models to generate different modalities, this increases the difficulty of model deployment and does not leverage complementary cues for multi-modal data generation. To address this problem, in this work, we propose a novel multi-modal multi-view video generation approach to autonomous driving. Specifically, we construct a unified diffusion transformer model composed of modal-shared components and modal-specific components. Then, we leverage diverse conditioning inputs to encode controllable scene structure and content cues into the unified diffusion model for multi-modal multi-view video generation. In this way, our approach is capable of generating multi-modal multi-view driving scene videos in a unified framework. Our experiments on the challenging real-world autonomous driving dataset, nuScenes, show that our approach can generate multi-modal multi-view urban scene videos with high fidelity and controllability, surpassing the state-of-the-art methods.
ECCV 2024 W-CODA: 1st Workshop on Multimodal Perception and Comprehension of Corner Cases in Autonomous Driving
Jul 02, 2025
In this paper, we present details of the 1st W-CODA workshop, held in conjunction with the ECCV 2024. W-CODA aims to explore next-generation solutions for autonomous driving corner cases, empowered by state-of-the-art multimodal perception and comprehension techniques. 5 Speakers from both academia and industry are invited to share their latest progress and opinions. We collect research papers and hold a dual-track challenge, including both corner case scene understanding and generation. As the pioneering effort, we will continuously bridge the gap between frontier autonomous driving techniques and fully intelligent, reliable self-driving agents robust towards corner cases.
Pose Optimization for Autonomous Driving Datasets using Neural Rendering Models
Apr 22, 2025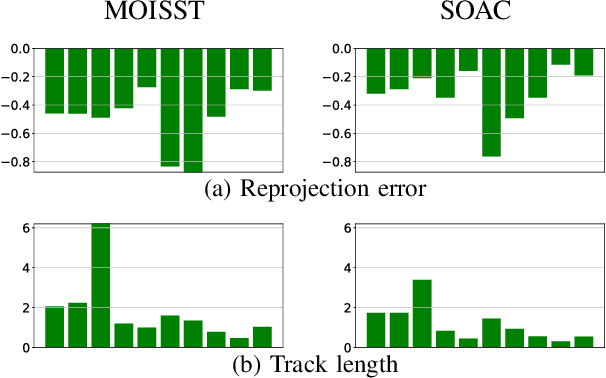
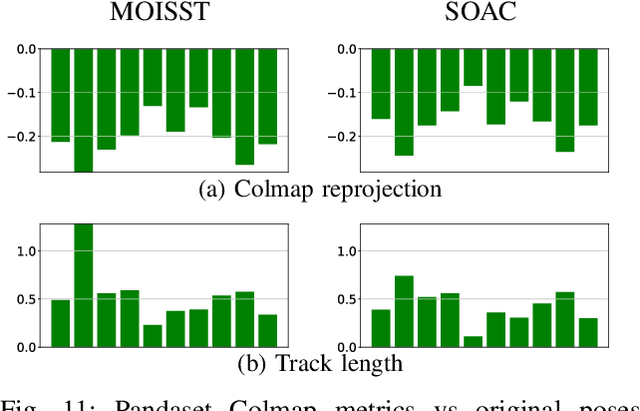
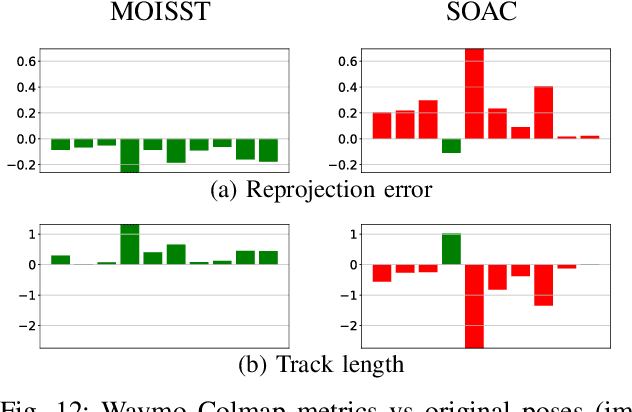
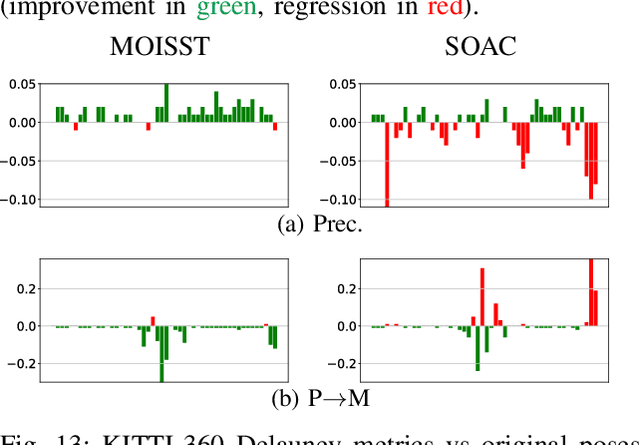
Autonomous driving systems rely on accurate perception and localization of the ego car to ensure safety and reliability in challenging real-world driving scenarios. Public datasets play a vital role in benchmarking and guiding advancement in research by providing standardized resources for model development and evaluation. However, potential inaccuracies in sensor calibration and vehicle poses within these datasets can lead to erroneous evaluations of downstream tasks, adversely impacting the reliability and performance of the autonomous systems. To address this challenge, we propose a robust optimization method based on Neural Radiance Fields (NeRF) to refine sensor poses and calibration parameters, enhancing the integrity of dataset benchmarks. To validate improvement in accuracy of our optimized poses without ground truth, we present a thorough evaluation process, relying on reprojection metrics, Novel View Synthesis rendering quality, and geometric alignment. We demonstrate that our method achieves significant improvements in sensor pose accuracy. By optimizing these critical parameters, our approach not only improves the utility of existing datasets but also paves the way for more reliable autonomous driving models. To foster continued progress in this field, we make the optimized sensor poses publicly available, providing a valuable resource for the research community.
EVolSplat: Efficient Volume-based Gaussian Splatting for Urban View Synthesis
Mar 26, 2025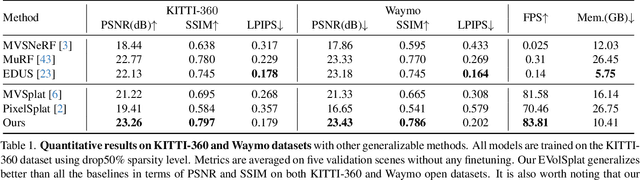
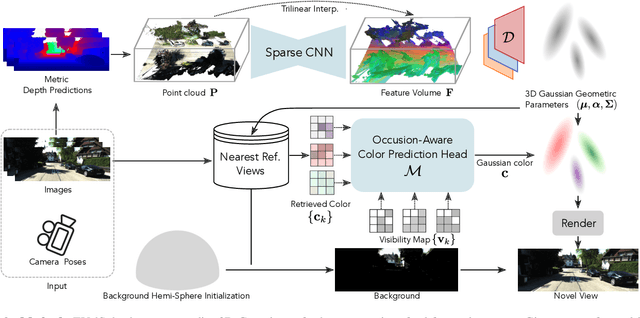
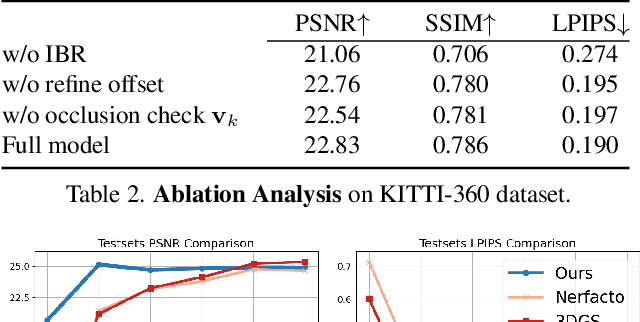
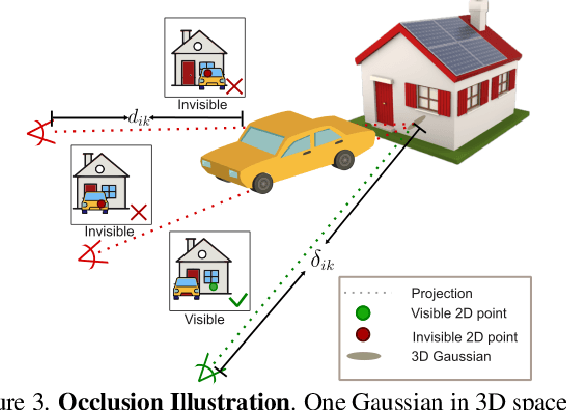
Novel view synthesis of urban scenes is essential for autonomous driving-related applications.Existing NeRF and 3DGS-based methods show promising results in achieving photorealistic renderings but require slow, per-scene optimization. We introduce EVolSplat, an efficient 3D Gaussian Splatting model for urban scenes that works in a feed-forward manner. Unlike existing feed-forward, pixel-aligned 3DGS methods, which often suffer from issues like multi-view inconsistencies and duplicated content, our approach predicts 3D Gaussians across multiple frames within a unified volume using a 3D convolutional network. This is achieved by initializing 3D Gaussians with noisy depth predictions, and then refining their geometric properties in 3D space and predicting color based on 2D textures. Our model also handles distant views and the sky with a flexible hemisphere background model. This enables us to perform fast, feed-forward reconstruction while achieving real-time rendering. Experimental evaluations on the KITTI-360 and Waymo datasets show that our method achieves state-of-the-art quality compared to existing feed-forward 3DGS- and NeRF-based methods.
Occ-LLM: Enhancing Autonomous Driving with Occupancy-Based Large Language Models
Feb 10, 2025Large Language Models (LLMs) have made substantial advancements in the field of robotic and autonomous driving. This study presents the first Occupancy-based Large Language Model (Occ-LLM), which represents a pioneering effort to integrate LLMs with an important representation. To effectively encode occupancy as input for the LLM and address the category imbalances associated with occupancy, we propose Motion Separation Variational Autoencoder (MS-VAE). This innovative approach utilizes prior knowledge to distinguish dynamic objects from static scenes before inputting them into a tailored Variational Autoencoder (VAE). This separation enhances the model's capacity to concentrate on dynamic trajectories while effectively reconstructing static scenes. The efficacy of Occ-LLM has been validated across key tasks, including 4D occupancy forecasting, self-ego planning, and occupancy-based scene question answering. Comprehensive evaluations demonstrate that Occ-LLM significantly surpasses existing state-of-the-art methodologies, achieving gains of about 6\% in Intersection over Union (IoU) and 4\% in mean Intersection over Union (mIoU) for the task of 4D occupancy forecasting. These findings highlight the transformative potential of Occ-LLM in reshaping current paradigms within robotic and autonomous driving.
An Efficient Occupancy World Model via Decoupled Dynamic Flow and Image-assisted Training
Dec 18, 2024



The field of autonomous driving is experiencing a surge of interest in world models, which aim to predict potential future scenarios based on historical observations. In this paper, we introduce DFIT-OccWorld, an efficient 3D occupancy world model that leverages decoupled dynamic flow and image-assisted training strategy, substantially improving 4D scene forecasting performance. To simplify the training process, we discard the previous two-stage training strategy and innovatively reformulate the occupancy forecasting problem as a decoupled voxels warping process. Our model forecasts future dynamic voxels by warping existing observations using voxel flow, whereas static voxels are easily obtained through pose transformation. Moreover, our method incorporates an image-assisted training paradigm to enhance prediction reliability. Specifically, differentiable volume rendering is adopted to generate rendered depth maps through predicted future volumes, which are adopted in render-based photometric consistency. Experiments demonstrate the effectiveness of our approach, showcasing its state-of-the-art performance on the nuScenes and OpenScene benchmarks for 4D occupancy forecasting, end-to-end motion planning and point cloud forecasting. Concretely, it achieves state-of-the-art performances compared to existing 3D world models while incurring substantially lower computational costs.