 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisit Mixture Models for Multi-Agent Simulation: Experimental Study within a Unified Framework
Jan 28, 2025



Simulation plays a crucial role in assessing autonomous driving systems, where the generation of realistic multi-agent behaviors is a key aspect. In multi-agent simulation, the primary challenges include behavioral multimodality and closed-loop distributional shifts. In this study, we revisit mixture models for generating multimodal agent behaviors, which can cover the mainstream methods including continuous mixture models and GPT-like discrete models. Furthermore, we introduce a closed-loop sample generation approach tailored for mixture models to mitigate distributional shifts. Within the unified mixture model~(UniMM) framework, we recognize critical configurations from both model and data perspectives. We conduct a systematic examination of various model configurations, including positive component matching, continuous regression, prediction horizon, and the number of components. Moreover, our investigation into the data configuration highlights the pivotal role of closed-loop samples in achieving realistic simulations. To extend the benefits of closed-loop samples across a broader range of mixture models, we further address the shortcut learning and off-policy learning issues. Leveraging insights from our exploration, the distinct variants proposed within the UniMM framework, including discrete, anchor-free, and anchor-based models, all achieve state-of-the-art performance on the WOSAC benchmark.
HUGSIM: A Real-Time, Photo-Realistic and Closed-Loop Simulator for Autonomous Driving
Dec 02, 2024

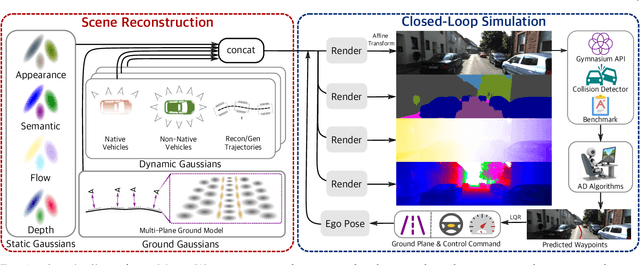
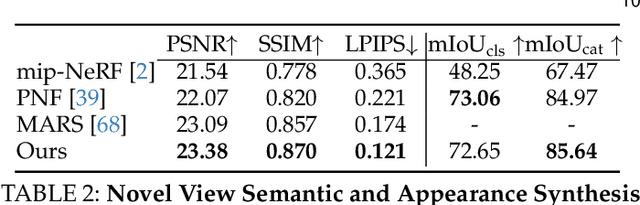
In the past few decades, autonomous driving algorithms have made significant progress in perception, planning, and control. However, evaluating individual components does not fully reflect the performance of entire systems, highlighting the need for more holistic assessment methods. This motivates the development of HUGSIM, a closed-loop, photo-realistic, and real-time simulator for evaluating autonomous driving algorithms. We achieve this by lifting captured 2D RGB images into the 3D space via 3D Gaussian Splatting, improving the rendering quality for closed-loop scenarios, and building the closed-loop environment. In terms of rendering, We tackle challenges of novel view synthesis in closed-loop scenarios, including viewpoint extrapolation and 360-degree vehicle rendering. Beyond novel view synthesis, HUGSIM further enables the full closed simulation loop, dynamically updating the ego and actor states and observations based on control commands. Moreover, HUGSIM offers a comprehensive benchmark across more than 70 sequences from KITTI-360, Waymo, nuScenes, and PandaSet, along with over 400 varying scenarios, providing a fair and realistic evaluation platform for existing autonomous driving algorithms. HUGSIM not only serves as an intuitive evaluation benchmark but also unlocks the potential for fine-tuning autonomous driving algorithms in a photorealistic closed-loop setting.
EDA: Evolving and Distinct Anchors for Multimodal Motion Prediction
Dec 15, 2023



Motion prediction is a crucial task in autonomous driving, and one of its major challenges lands in the multimodality of future behaviors. Many successful works have utilized mixture models which require identification of positive mixture components, and correspondingly fall into two main lines: prediction-based and anchor-based matching. The prediction clustering phenomenon in prediction-based matching makes it difficult to pick representative trajectories for downstream tasks, while the anchor-based matching suffers from a limited regression capability. In this paper, we introduce a novel paradigm, named Evolving and Distinct Anchors (EDA), to define the positive and negative components for multimodal motion prediction based on mixture models. We enable anchors to evolve and redistribute themselves under specific scenes for an enlarged regression capacity. Furthermore, we select distinct anchors before matching them with the ground truth, which results in impressive scoring performance. Our approach enhances all metrics compared to the baseline MTR, particularly with a notable relative reduction of 13.5% in Miss Rate, resulting in state-of-the-art performance on the Waymo Open Motion Dataset. Code is available at https://github.com/Longzhong-Lin/EDA.
Learning Observation-Based Certifiable Safe Policy for Decentralized Multi-Robot Navigation
Sep 16, 2021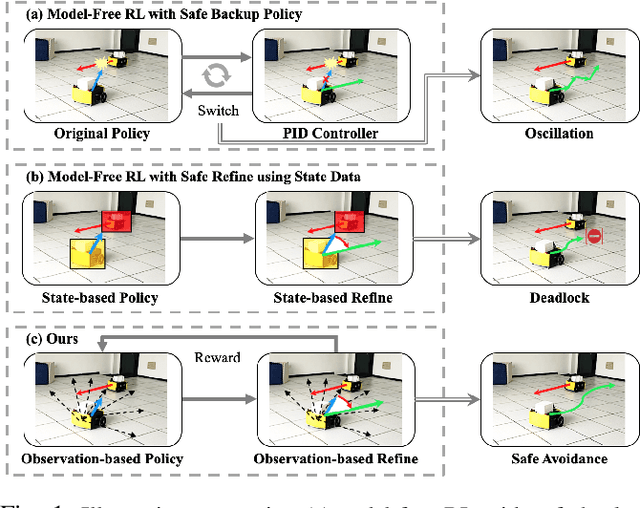
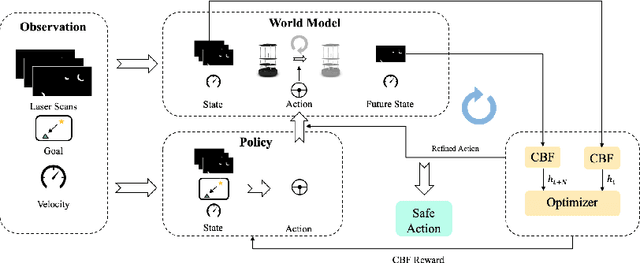


Safety is of great importance in multi-robot navigation problems. In this paper, we propose a control barrier function (CBF) based optimizer that ensures robot safety with both high probability and flexibility, using only sensor measurement. The optimizer takes action commands from the policy network as initial values and then provides refinement to drive the potentially dangerous ones back into safe regions. With the help of a deep transition model that predicts the evolution of surrounding dynamics and the consequences of different actions, the CBF module can guide the optimization in a reasonable time horizon. We also present a novel joint training framework that improves the cooperation between the Reinforcement Learning (RL) based policy and the CBF-based optimizer both in training and inference procedures by utilizing reward feedback from the CBF module. We observe that the policy using our method can achieve a higher success rate while maintaining the safety of multiple robots in significantly fewer episodes compared with other methods. Experiments are conducted in multiple scenarios both in simulation and the real world, the results demonstrate the effectiveness of our method in maintaining the safety of multi-robot navigation. Code is available at \url{https://github.com/YuxiangCui/MARL-OCBF