 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyLO: Towards Accessible Learned Optimizers in PyTorch
Jun 12, 2025Learned optimizers have been an active research topic over the past decade, with increasing progress toward practical, general-purpose optimizers that can serve as drop-in replacements for widely used methods like Adam. However, recent advances -- such as VeLO, which was meta-trained for 4000 TPU-months -- remain largely inaccessible to the broader community, in part due to their reliance on JAX and the absence of user-friendly packages for applying the optimizers after meta-training. To address this gap, we introduce PyLO, a PyTorch-based library that brings learned optimizers to the broader machine learning community through familiar, widely adopted workflows. Unlike prior work focused on synthetic or convex tasks, our emphasis is on applying learned optimization to real-world large-scale pre-training tasks. Our release includes a CUDA-accelerated version of the small_fc_lopt learned optimizer architecture from (Metz et al., 2022a), delivering substantial speedups -- from 39.36 to 205.59 samples/sec throughput for training ViT B/16 with batch size 32. PyLO also allows us to easily combine learned optimizers with existing optimization tools such as learning rate schedules and weight decay. When doing so, we find that learned optimizers can substantially benefit. Our code is available at https://github.com/Belilovsky-Lab/pylo
MuLoCo: Muon is a practical inner optimizer for DiLoCo
May 29, 2025DiLoCo is a powerful framework for training large language models (LLMs) under networking constraints with advantages for increasing parallelism and accelerator utilization in data center settings. Despite significantly reducing communication frequency, however, DiLoCo's communication steps still involve all-reducing a complete copy of the model's parameters. While existing works have explored ways to reduce communication in DiLoCo, the role of error feedback accumulators and the effect of the inner-optimizer on compressibility remain under-explored. In this work, we investigate the effectiveness of standard compression methods including Top-k sparsification and quantization for reducing the communication overhead of DiLoCo when paired with two local optimizers (AdamW and Muon). Our experiments pre-training decoder-only transformer language models (LMs) reveal that leveraging Muon as the inner optimizer for DiLoCo along with an error-feedback accumulator allows to aggressively compress the communicated delta to 2-bits with next to no performance degradation. Crucially, MuLoCo (Muon inner optimizer DiLoCo) significantly outperforms DiLoCo while communicating 8X less and having identical memory complexity.
Scaling Laws of Synthetic Data for Language Models
Mar 26, 2025



Large language models (LLMs) achieve strong performance across diverse tasks, largely driven by high-quality web data used in pre-training. However, recent studies indicate this data source is rapidly depleting. Synthetic data emerges as a promising alternative, but it remains unclear whether synthetic datasets exhibit predictable scalability comparable to raw pre-training data. In this work, we systematically investigate the scaling laws of synthetic data by introducing SynthLLM, a scalable framework that transforms pre-training corpora into diverse, high-quality synthetic datasets. Our approach achieves this by automatically extracting and recombining high-level concepts across multiple documents using a graph algorithm. Key findings from our extensive mathematical experiments on SynthLLM include: (1) SynthLLM generates synthetic data that reliably adheres to the rectified scaling law across various model sizes; (2) Performance improvements plateau near 300B tokens; and (3) Larger models approach optimal performance with fewer training tokens. For instance, an 8B model peaks at 1T tokens, while a 3B model requires 4T. Moreover, comparisons with existing synthetic data generation and augmentation methods demonstrate that SynthLLM achieves superior performance and scalability. Our findings highlight synthetic data as a scalable and reliable alternative to organic pre-training corpora, offering a viable path toward continued improvement in model performance.
WildLong: Synthesizing Realistic Long-Context Instruction Data at Scale
Feb 23, 2025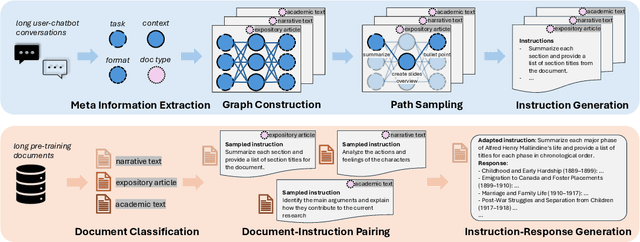
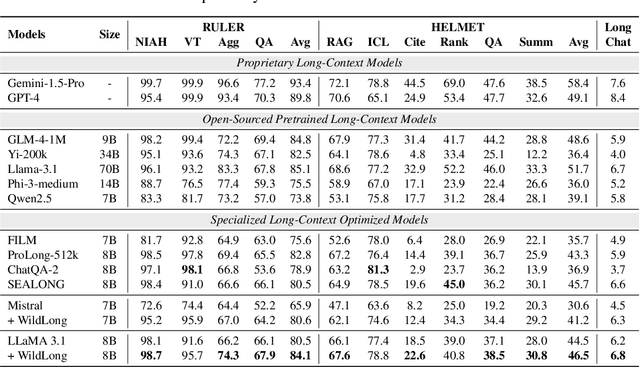
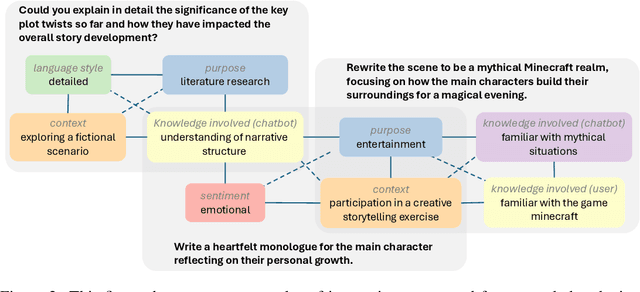
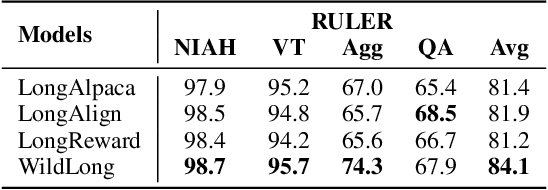
Large language models (LLMs) with extended context windows enable tasks requiring extensive information integration but are limited by the scarcity of high-quality, diverse datasets for long-context instruction tuning. Existing data synthesis methods focus narrowly on objectives like fact retrieval and summarization, restricting their generalizability to complex, real-world tasks. WildLong extracts meta-information from real user queries, models co-occurrence relationships via graph-based methods, and employs adaptive generation to produce scalable data. It extends beyond single-document tasks to support multi-document reasoning, such as cross-document comparison and aggregation. Our models, finetuned on 150K instruction-response pairs synthesized using WildLong, surpasses existing open-source long-context-optimized models across benchmarks while maintaining strong performance on short-context tasks without incorporating supplementary short-context data. By generating a more diverse and realistic long-context instruction dataset, WildLong enhances LLMs' ability to generalize to complex, real-world reasoning over long contexts, establishing a new paradigm for long-context data synthesis.
Chain-of-Retrieval Augmented Generation
Jan 24, 2025



This paper introduces an approach for training o1-like RAG models that retrieve and reason over relevant information step by step before generating the final answer. Conventional RAG methods usually perform a single retrieval step before the generation process, which limits their effectiveness in addressing complex queries due to imperfect retrieval results. In contrast, our proposed method, CoRAG (Chain-of-Retrieval Augmented Generation), allows the model to dynamically reformulate the query based on the evolving state. To train CoRAG effectively, we utilize rejection sampling to automatically generate intermediate retrieval chains, thereby augmenting existing RAG datasets that only provide the correct final answer. At test time, we propose various decoding strategies to scale the model's test-time compute by controlling the length and number of sampled retrieval chains. Experimental results across multiple benchmarks validate the efficacy of CoRAG, particularly in multi-hop question answering tasks, where we observe more than 10 points improvement in EM score compared to strong baselines. On the KILT benchmark, CoRAG establishes a new state-of-the-art performance across a diverse range of knowledge-intensive tasks. Furthermore, we offer comprehensive analyses to understand the scaling behavior of CoRAG, laying the groundwork for future research aimed at developing factual and grounded foundation models.
Bootstrap Your Own Context Length
Dec 25, 2024We introduce a bootstrapping approach to train long-context language models by exploiting their short-context capabilities only. Our method utilizes a simple agent workflow to synthesize diverse long-context instruction tuning data, thereby eliminating the necessity for manual data collection and annotation. The proposed data synthesis workflow requires only a short-context language model, a text retriever, and a document collection, all of which are readily accessible within the open-source ecosystem. Subsequently, language models are fine-tuned using the synthesized data to extend their context lengths. In this manner, we effectively transfer the short-context capabilities of language models to long-context scenarios through a bootstrapping process. We conduct experiments with the open-source Llama-3 family of models and demonstrate that our method can successfully extend the context length to up to 1M tokens, achieving superior performance across various benchmarks.
Synthetic Data (Almost) from Scratch: Generalized Instruction Tuning for Language Models
Feb 20, 2024We introduce Generalized Instruction Tuning (called GLAN), a general and scalable method for instruction tuning of Large Language Models (LLMs). Unlike prior work that relies on seed examples or existing datasets to construct instruction tuning data, GLAN exclusively utilizes a pre-curated taxonomy of human knowledge and capabilities as input and generates large-scale synthetic instruction data across all disciplines. Specifically, inspired by the systematic structure in human education system, we build the taxonomy by decomposing human knowledge and capabilities to various fields, sub-fields and ultimately, distinct disciplines semi-automatically, facilitated by LLMs. Subsequently, we generate a comprehensive list of subjects for every discipline and proceed to design a syllabus tailored to each subject, again utilizing LLMs. With the fine-grained key concepts detailed in every class session of the syllabus, we are able to generate diverse instructions with a broad coverage across the entire spectrum of human knowledge and skills. Extensive experiments on large language models (e.g., Mistral) demonstrate that GLAN excels in multiple dimensions from mathematical reasoning, coding, academic exams, logical reasoning to general instruction following without using task-specific training data of these tasks. In addition, GLAN allows for easy customization and new fields or skills can be added by simply incorporating a new node into our taxonomy.
Multilingual E5 Text Embeddings: A Technical Report
Feb 08, 2024This technical report presents the training methodology and evaluation results of the open-source multilingual E5 text embedding models, released in mid-2023. Three embedding models of different sizes (small / base / large) are provided, offering a balance between the inference efficiency and embedding quality. The training procedure adheres to the English E5 model recipe, involving contrastive pre-training on 1 billion multilingual text pairs, followed by fine-tuning on a combination of labeled datasets. Additionally, we introduce a new instruction-tuned embedding model, whose performance is on par with state-of-the-art, English-only models of similar sizes. Information regarding the model release can be found at https://github.com/microsoft/unilm/tree/master/e5 .
One Step Learning, One Step Review
Jan 19, 2024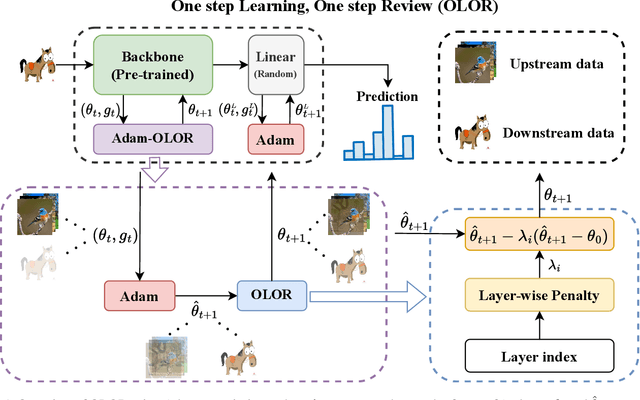
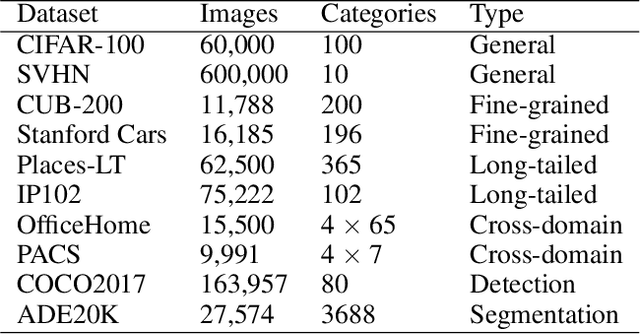
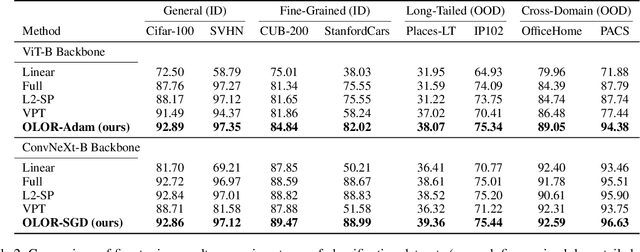
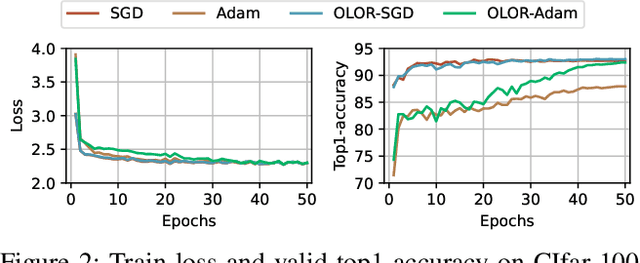
Visual fine-tuning has garnered significant attention with the rise of pre-trained vision models. The current prevailing method, full fine-tuning, suffers from the issue of knowledge forgetting as it focuses solely on fitting the downstream training set. In this paper, we propose a novel weight rollback-based fine-tuning method called OLOR (One step Learning, One step Review). OLOR combines fine-tuning with optimizers, incorporating a weight rollback term into the weight update term at each step. This ensures consistency in the weight range of upstream and downstream models, effectively mitigating knowledge forgetting and enhancing fine-tuning performance. In addition, a layer-wise penalty is presented to employ penalty decay and the diversified decay rate to adjust the weight rollback levels of layers for adapting varying downstream tasks. Through extensive experiments on various tasks such as image classification, object detection, semantic segmentation, and instance segmentation, we demonstrate the general applicability and state-of-the-art performance of our proposed OLOR. Code is available at https://github.com/rainbow-xiao/OLOR-AAAI-2024.
Improving Text Embeddings with Large Language Models
Dec 31, 2023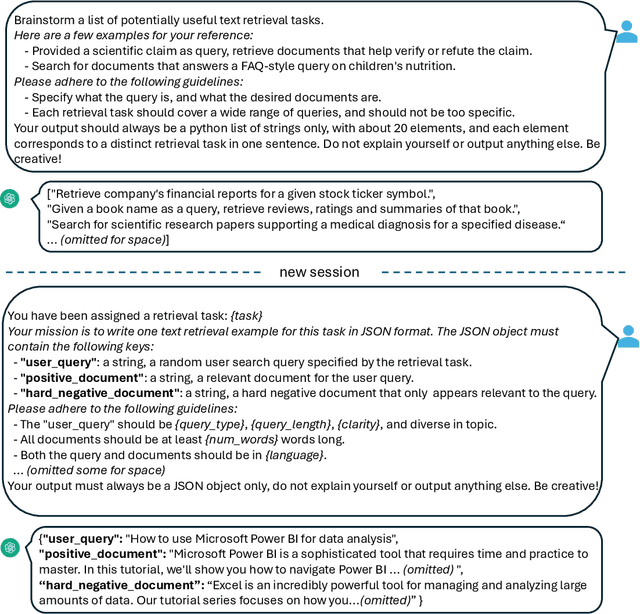
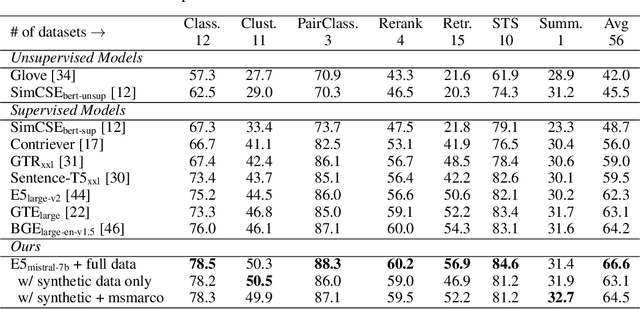
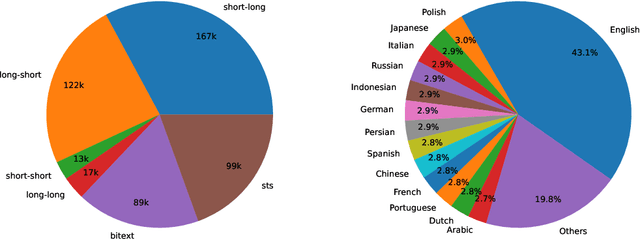
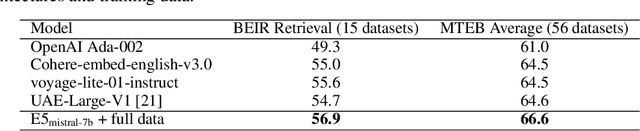
In this paper, we introduce a novel and simple method for obtaining high-quality text embeddings using only synthetic data and less than 1k training steps. Unlike existing methods that often depend on multi-stage intermediate pre-training with billions of weakly-supervised text pairs, followed by fine-tuning with a few labeled datasets, our method does not require building complex training pipelines or relying on manually collected datasets that are often constrained by task diversity and language coverage. We leverage proprietary LLMs to generate diverse synthetic data for hundreds of thousands of text embedding tasks across nearly 100 languages. We then fine-tune open-source decoder-only LLMs on the synthetic data using standard contrastive loss. Experiments demonstrate that our method achieves strong performance on highly competitive text embedding benchmarks without using any labeled data. Furthermore, when fine-tuned with a mixture of synthetic and labeled data, our model sets new state-of-the-art results on the BEIR and MTEB benchmarks.