 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRACE: Boosting Video MLLMs with Grounded Action-Centric Evidence for Viewer Sentiment Prediction
Jun 15, 2026Viewer sentiment prediction in video advertisements aims to infer the latent affective response evoked in the audience. To bridge the gap between what is shown and what is felt, models must deduce hidden viewer emotions from explicit visual narratives, concrete character-object interactions, and visible textual cues. However, standard Multimodal Large Language Models (MLLMs) typically rely on holistic frame representations, which leave these fine-grained, affect-relevant events implicit and complicate precise emotional reasoning. To address this, we propose a grounded action-centric evidence augmentation framework that enhances video MLLMs' clue extraction and comprehension by introducing explicit event structure and localized visual evidence. Our method extracts temporally ordered subject-verb-object (SVO) triplets and auxiliary visible textual cues from action-centric video descriptions, grounds subject and object entities as visual entity crops, and then enables the MLLM to perform clue-enhanced emotional reasoning based on these extracted structured clues. In this way, action triplets specify "what happens", while grounded visual entity crops anchor "who or what participates in each event" to concrete visual evidence. Experiments on the Pitts dataset show consistent improvements over Qwen2.5-VL and Qwen3-VL baselines. Ablation studies, cross-dataset evaluation on AdsQA, and transfer experiments on an emotion-focused TVQA subset further support the effectiveness and generalization of our approach.
One Step Learning, One Step Review
Jan 19, 2024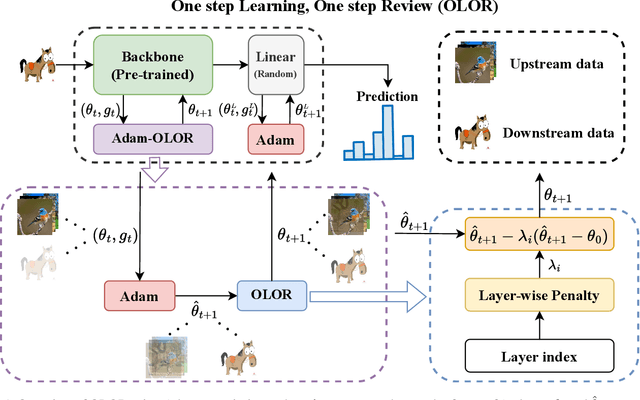
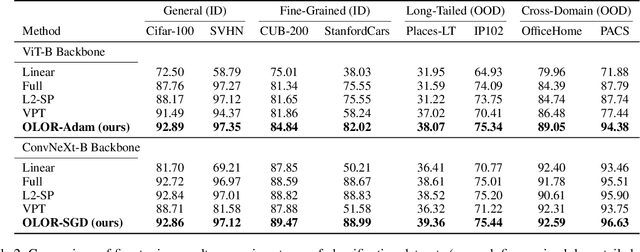
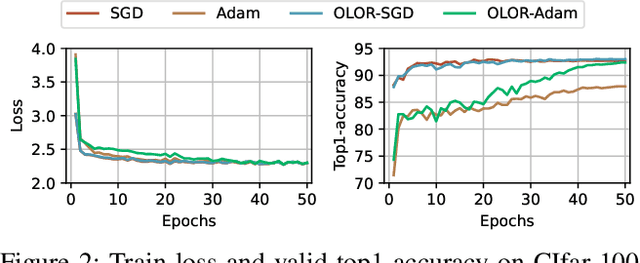
Visual fine-tuning has garnered significant attention with the rise of pre-trained vision models. The current prevailing method, full fine-tuning, suffers from the issue of knowledge forgetting as it focuses solely on fitting the downstream training set. In this paper, we propose a novel weight rollback-based fine-tuning method called OLOR (One step Learning, One step Review). OLOR combines fine-tuning with optimizers, incorporating a weight rollback term into the weight update term at each step. This ensures consistency in the weight range of upstream and downstream models, effectively mitigating knowledge forgetting and enhancing fine-tuning performance. In addition, a layer-wise penalty is presented to employ penalty decay and the diversified decay rate to adjust the weight rollback levels of layers for adapting varying downstream tasks. Through extensive experiments on various tasks such as image classification, object detection, semantic segmentation, and instance segmentation, we demonstrate the general applicability and state-of-the-art performance of our proposed OLOR. Code is available at https://github.com/rainbow-xiao/OLOR-AAAI-2024.
Population-Based Evolutionary Gaming for Unsupervised Person Re-identification
Jun 08, 2023Unsupervised person re-identification has achieved great success through the self-improvement of individual neural networks. However, limited by the lack of diversity of discriminant information, a single network has difficulty learning sufficient discrimination ability by itself under unsupervised conditions. To address this limit, we develop a population-based evolutionary gaming (PEG) framework in which a population of diverse neural networks is trained concurrently through selection, reproduction, mutation, and population mutual learning iteratively. Specifically, the selection of networks to preserve is modeled as a cooperative game and solved by the best-response dynamics, then the reproduction and mutation are implemented by cloning and fluctuating hyper-parameters of networks to learn more diversity, and population mutual learning improves the discrimination of networks by knowledge distillation from each other within the population. In addition, we propose a cross-reference scatter (CRS) to approximately evaluate re-ID models without labeled samples and adopt it as the criterion of network selection in PEG. CRS measures a model's performance by indirectly estimating the accuracy of its predicted pseudo-labels according to the cohesion and separation of the feature space. Extensive experiments demonstrate that (1) CRS approximately measures the performance of models without labeled samples; (2) and PEG produces new state-of-the-art accuracy for person re-identification, indicating the great potential of population-based network cooperative training for unsupervised learning.
High-Resolution Image Harmonization via Collaborative Dual Transformations
Sep 14, 2021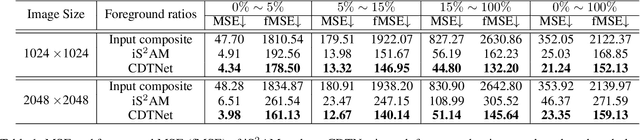

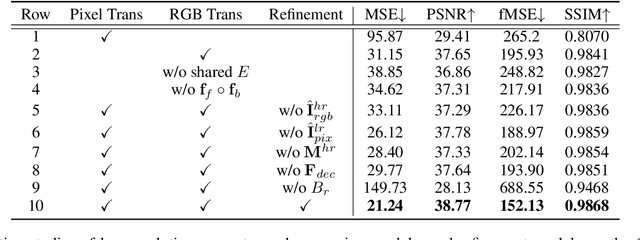
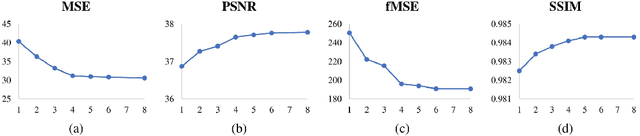
Given a composite image, image harmonization aims to adjust the foreground to make it compatible with the background. High-resolution image harmonization is in high demand, but still remains unexplored. Conventional image harmonization methods learn global RGB-to-RGB transformation which could effortlessly scale to high resolution, but ignore diverse local context. Recent deep learning methods learn the dense pixel-to-pixel transformation which could generate harmonious outputs, but are highly constrained in low resolution. In this work, we propose a high-resolution image harmonization network with Collaborative Dual Transformation (CDTNet) to combine pixel-to-pixel transformation and RGB-to-RGB transformation coherently in an end-to-end framework. Our CDTNet consists of a low-resolution generator for pixel-to-pixel transformation, a color mapping module for RGB-to-RGB transformation, and a refinement module to take advantage of both. Extensive experiments on high-resolution image harmonization dataset demonstrate that our CDTNet strikes a good balance between efficiency and effectiveness.
Deep Image Harmonization by Bridging the Reality Gap
Mar 31, 2021
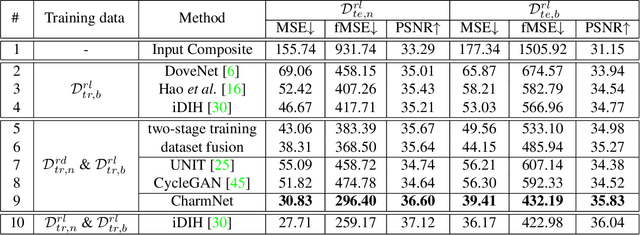
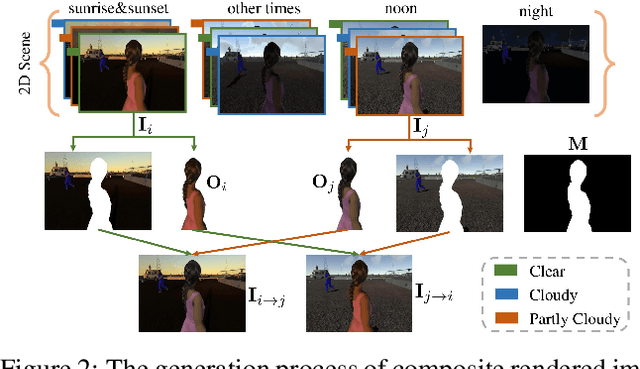
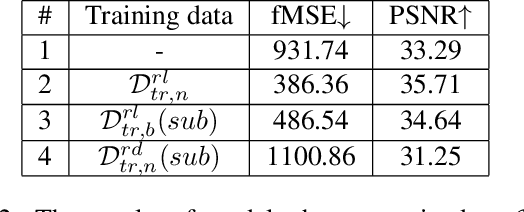
Image harmonization has been significantly advanced with large-scale harmonization dataset. However, the current way to build dataset is still labor-intensive, which adversely affects the extendability of dataset. To address this problem, we propose to construct a large-scale rendered harmonization dataset RHHarmony with fewer human efforts to augment the existing real-world dataset. To leverage both real-world images and rendered images, we propose a cross-domain harmonization network CharmNet to bridge the domain gap between two domains. Moreover, we also employ well-designed style classifiers and losses to facilitate cross-domain knowledge transfer. Extensive experiments demonstrate the potential of using rendered images for image harmonization and the effectiveness of our proposed network. Our dataset and code are available at https://github.com/bcmi/Rendered_Image_Harmonization_Datasets.
Deinterlacing Network for Early Interlaced Videos
Nov 27, 2020

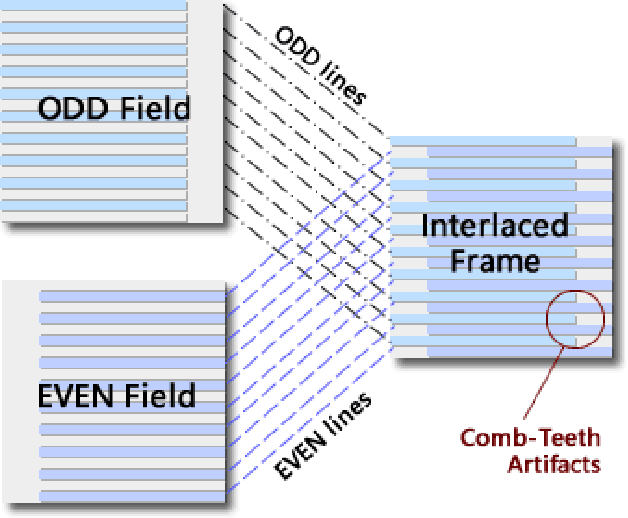
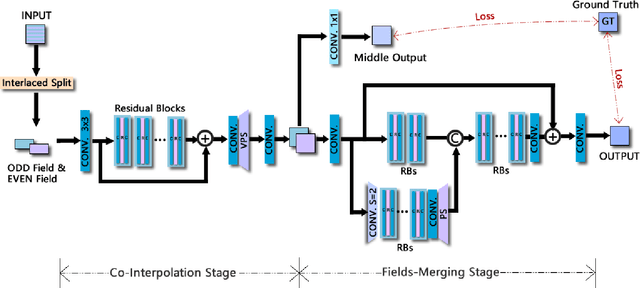
With the rapid development of image restoration techniques, high-definition reconstruction of early videos has achieved impressive results. However, there are few studies about the interlacing artifacts that often appear in early videos and significantly affect visual perception. Traditional deinterlacing approaches are mainly focused on early interlacing scanning systems and thus cannot handle the complex and complicated artifacts in real-world early interlaced videos. Hence, this paper proposes a specific deinterlacing network (DIN), which is motivated by the traditional deinterlacing strategy. The proposed DIN consists of two stages, i.e., a cooperative vertical interpolation stage for split fields, and a merging stage that is applied to perceive movements and remove ghost artifacts. Experimental results demonstrate that the proposed method can effectively remove complex artifacts in early interlaced videos.