 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Iterative Task-Driven Framework for Resilient LiDAR Place Recognition in Adverse Weather
Apr 21, 2025LiDAR place recognition (LPR) plays a vital role in autonomous navigation. However, existing LPR methods struggle to maintain robustness under adverse weather conditions such as rain, snow, and fog, where weather-induced noise and point cloud degradation impair LiDAR reliability and perception accuracy. To tackle these challenges, we propose an Iterative Task-Driven Framework (ITDNet), which integrates a LiDAR Data Restoration (LDR) module and a LiDAR Place Recognition (LPR) module through an iterative learning strategy. These modules are jointly trained end-to-end, with alternating optimization to enhance performance. The core rationale of ITDNet is to leverage the LDR module to recover the corrupted point clouds while preserving structural consistency with clean data, thereby improving LPR accuracy in adverse weather. Simultaneously, the LPR task provides feature pseudo-labels to guide the LDR module's training, aligning it more effectively with the LPR task. To achieve this, we first design a task-driven LPR loss and a reconstruction loss to jointly supervise the optimization of the LDR module. Furthermore, for the LDR module, we propose a Dual-Domain Mixer (DDM) block for frequency-spatial feature fusion and a Semantic-Aware Generator (SAG) block for semantic-guided restoration. In addition, for the LPR module, we introduce a Multi-Frequency Transformer (MFT) block and a Wavelet Pyramid NetVLAD (WPN) block to aggregate multi-scale, robust global descriptors. Finally, extensive experiments on the Weather-KITTI, Boreas, and our proposed Weather-Apollo datasets demonstrate that, demonstrate that ITDNet outperforms existing LPR methods, achieving state-of-the-art performance in adverse weather. The datasets and code will be made publicly available at https://github.com/Grandzxw/ITDNet.
SplatPose: Geometry-Aware 6-DoF Pose Estimation from Single RGB Image via 3D Gaussian Splatting
Mar 07, 20256-DoF pose estimation is a fundamental task in computer vision with wide-ranging applications in augmented reality and robotics. Existing single RGB-based methods often compromise accuracy due to their reliance on initial pose estimates and susceptibility to rotational ambiguity, while approaches requiring depth sensors or multi-view setups incur significant deployment costs. To address these limitations, we introduce SplatPose, a novel framework that synergizes 3D Gaussian Splatting (3DGS) with a dual-branch neural architecture to achieve high-precision pose estimation using only a single RGB image. Central to our approach is the Dual-Attention Ray Scoring Network (DARS-Net), which innovatively decouples positional and angular alignment through geometry-domain attention mechanisms, explicitly modeling directional dependencies to mitigate rotational ambiguity. Additionally, a coarse-to-fine optimization pipeline progressively refines pose estimates by aligning dense 2D features between query images and 3DGS-synthesized views, effectively correcting feature misalignment and depth errors from sparse ray sampling. Experiments on three benchmark datasets demonstrate that SplatPose achieves state-of-the-art 6-DoF pose estimation accuracy in single RGB settings, rivaling approaches that depend on depth or multi-view images.
MQADet: A Plug-and-Play Paradigm for Enhancing Open-Vocabulary Object Detection via Multimodal Question Answering
Feb 26, 2025Open-vocabulary detection (OVD) is a challenging task to detect and classify objects from an unrestricted set of categories, including those unseen during training. Existing open-vocabulary detectors are limited by complex visual-textual misalignment and long-tailed category imbalances, leading to suboptimal performance in challenging scenarios. To address these limitations, we introduce MQADet, a universal paradigm for enhancing existing open-vocabulary detectors by leveraging the cross-modal reasoning capabilities of multimodal large language models (MLLMs). MQADet functions as a plug-and-play solution that integrates seamlessly with pre-trained object detectors without substantial additional training costs. Specifically, we design a novel three-stage Multimodal Question Answering (MQA) pipeline to guide the MLLMs to precisely localize complex textual and visual targets while effectively enhancing the focus of existing object detectors on relevant objects. To validate our approach, we present a new benchmark for evaluating our paradigm on four challenging open-vocabulary datasets, employing three state-of-the-art object detectors as baselines. Experimental results demonstrate that our proposed paradigm significantly improves the performance of existing detectors, particularly in unseen complex categories, across diverse and challenging scenarios. To facilitate future research, we will publicly release our code.
High-Resolution Image Harmonization via Collaborative Dual Transformations
Sep 14, 2021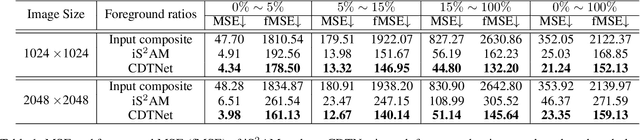

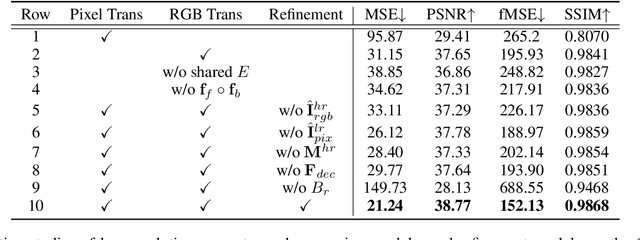
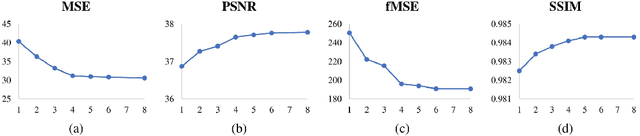
Given a composite image, image harmonization aims to adjust the foreground to make it compatible with the background. High-resolution image harmonization is in high demand, but still remains unexplored. Conventional image harmonization methods learn global RGB-to-RGB transformation which could effortlessly scale to high resolution, but ignore diverse local context. Recent deep learning methods learn the dense pixel-to-pixel transformation which could generate harmonious outputs, but are highly constrained in low resolution. In this work, we propose a high-resolution image harmonization network with Collaborative Dual Transformation (CDTNet) to combine pixel-to-pixel transformation and RGB-to-RGB transformation coherently in an end-to-end framework. Our CDTNet consists of a low-resolution generator for pixel-to-pixel transformation, a color mapping module for RGB-to-RGB transformation, and a refinement module to take advantage of both. Extensive experiments on high-resolution image harmonization dataset demonstrate that our CDTNet strikes a good balance between efficiency and effectiveness.