 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAny3DAvatar: Fast and High-Quality Full-Head 3D Avatar Reconstruction from Single Portrait Image
Apr 15, 2026Reconstructing a complete 3D head from a single portrait remains challenging because existing methods still face a sharp quality-speed trade-off: high-fidelity pipelines often rely on multi-stage processing and per-subject optimization, while fast feed-forward models struggle with complete geometry and fine appearance details. To bridge this gap, we propose Any3DAvatar, a fast and high-quality method for single-image 3D Gaussian head avatar generation, whose fastest setting reconstructs a full head in under one second while preserving high-fidelity geometry and texture. First, we build AnyHead, a unified data suite that combines identity diversity, dense multi-view supervision, and realistic accessories, filling the main gaps of existing head data in coverage, full-head geometry, and complex appearance. Second, rather than sampling unstructured noise, we initialize from a Plücker-aware structured 3D Gaussian scaffold and perform one-step conditional denoising, formulating full-head reconstruction into a single forward pass while retaining high fidelity. Third, we introduce auxiliary view-conditioned appearance supervision on the same latent tokens alongside 3D Gaussian reconstruction, improving novel-view texture details at zero extra inference cost. Experiments show that Any3DAvatar outperforms prior single-image full-head reconstruction methods in rendering fidelity while remaining substantially faster.
Towards Source-Aware Object Swapping with Initial Noise Perturbation
Mar 02, 2026Object swapping aims to replace a source object in a scene with a reference object while preserving object fidelity, scene fidelity, and object-scene harmony. Existing methods either require per-object finetuning and slow inference or rely on extra paired data that mostly depict the same object across contexts, forcing models to rely on background cues rather than learning cross-object alignment. We propose SourceSwap, a self-supervised and source-aware framework that learns cross-object alignment. Our key insight is to synthesize high-quality pseudo pairs from any image via a frequency-separated perturbation in the initial-noise space, which alters appearance while preserving pose, coarse shape, and scene layout, requiring no videos, multi-view data, or additional images. We then train a dual U-Net with full-source conditioning and a noise-free reference encoder, enabling direct inter-object alignment, zero-shot inference without per-object finetuning, and lightweight iterative refinement. We further introduce SourceBench, a high-quality benchmark with higher resolution, more categories, and richer interactions. Experiments demonstrate that SourceSwap achieves superior fidelity, stronger scene preservation, and more natural harmony, and it transfers well to edits such as subject-driven refinement and face swapping.
VTONGuard: Automatic Detection and Authentication of AI-Generated Virtual Try-On Content
Jan 20, 2026With the rapid advancement of generative AI, virtual try-on (VTON) systems are becoming increasingly common in e-commerce and digital entertainment. However, the growing realism of AI-generated try-on content raises pressing concerns about authenticity and responsible use. To address this, we present VTONGuard, a large-scale benchmark dataset containing over 775,000 real and synthetic try-on images. The dataset covers diverse real-world conditions, including variations in pose, background, and garment styles, and provides both authentic and manipulated examples. Based on this benchmark, we conduct a systematic evaluation of multiple detection paradigms under unified training and testing protocols. Our results reveal each method's strengths and weaknesses and highlight the persistent challenge of cross-paradigm generalization. To further advance detection, we design a multi-task framework that integrates auxiliary segmentation to enhance boundary-aware feature learning, achieving the best overall performance on VTONGuard. We expect this benchmark to enable fair comparisons, facilitate the development of more robust detection models, and promote the safe and responsible deployment of VTON technologies in practice.
Interpretable and Reliable Detection of AI-Generated Images via Grounded Reasoning in MLLMs
Jun 08, 2025
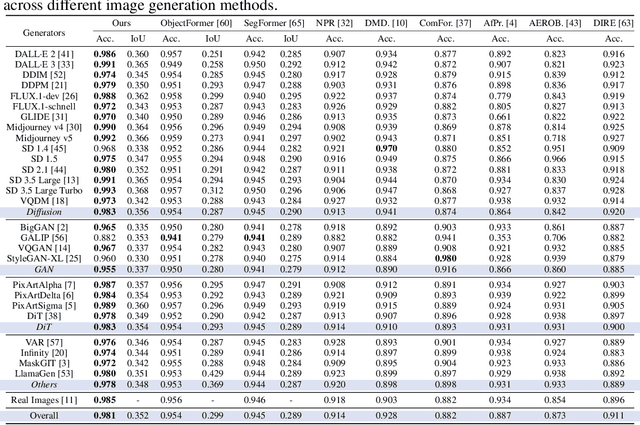


The rapid advancement of image generation technologies intensifies the demand for interpretable and robust detection methods. Although existing approaches often attain high accuracy, they typically operate as black boxes without providing human-understandable justifications. Multi-modal Large Language Models (MLLMs), while not originally intended for forgery detection, exhibit strong analytical and reasoning capabilities. When properly fine-tuned, they can effectively identify AI-generated images and offer meaningful explanations. However, existing MLLMs still struggle with hallucination and often fail to align their visual interpretations with actual image content and human reasoning. To bridge this gap, we construct a dataset of AI-generated images annotated with bounding boxes and descriptive captions that highlight synthesis artifacts, establishing a foundation for human-aligned visual-textual grounded reasoning. We then finetune MLLMs through a multi-stage optimization strategy that progressively balances the objectives of accurate detection, visual localization, and coherent textual explanation. The resulting model achieves superior performance in both detecting AI-generated images and localizing visual flaws, significantly outperforming baseline methods.
COCO-Inpaint: A Benchmark for Image Inpainting Detection and Manipulation Localization
Apr 25, 2025
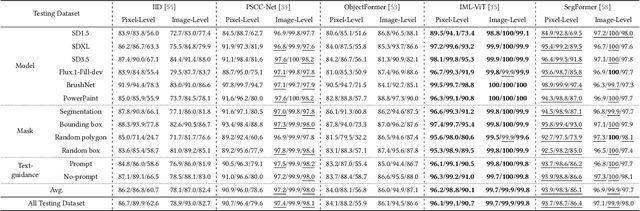


Recent advancements in image manipulation have achieved unprecedented progress in generating photorealistic content, but also simultaneously eliminating barriers to arbitrary manipulation and editing, raising concerns about multimedia authenticity and cybersecurity. However, existing Image Manipulation Detection and Localization (IMDL) methodologies predominantly focus on splicing or copy-move forgeries, lacking dedicated benchmarks for inpainting-based manipulations. To bridge this gap, we present COCOInpaint, a comprehensive benchmark specifically designed for inpainting detection, with three key contributions: 1) High-quality inpainting samples generated by six state-of-the-art inpainting models, 2) Diverse generation scenarios enabled by four mask generation strategies with optional text guidance, and 3) Large-scale coverage with 258,266 inpainted images with rich semantic diversity. Our benchmark is constructed to emphasize intrinsic inconsistencies between inpainted and authentic regions, rather than superficial semantic artifacts such as object shapes. We establish a rigorous evaluation protocol using three standard metrics to assess existing IMDL approaches. The dataset will be made publicly available to facilitate future research in this area.
Towards Explainable Fake Image Detection with Multi-Modal Large Language Models
Apr 19, 2025
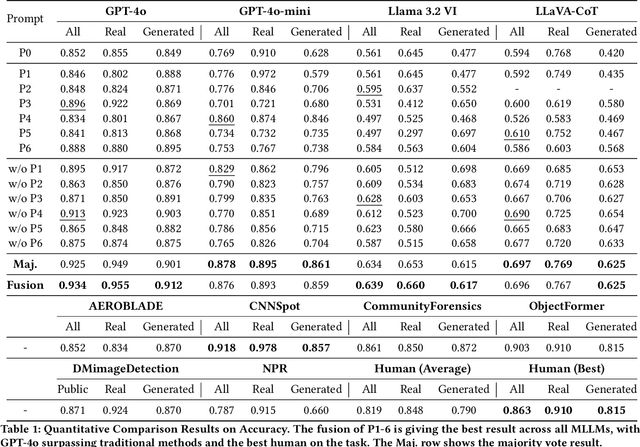

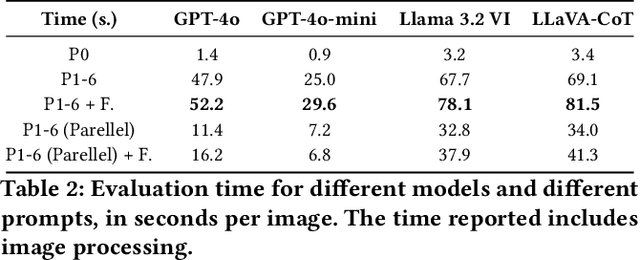
Progress in image generation raises significant public security concerns. We argue that fake image detection should not operate as a "black box". Instead, an ideal approach must ensure both strong generalization and transparency. Recent progress in Multi-modal Large Language Models (MLLMs) offers new opportunities for reasoning-based AI-generated image detection. In this work, we evaluate the capabilities of MLLMs in comparison to traditional detection methods and human evaluators, highlighting their strengths and limitations. Furthermore, we design six distinct prompts and propose a framework that integrates these prompts to develop a more robust, explainable, and reasoning-driven detection system. The code is available at https://github.com/Gennadiyev/mllm-defake.
InterAnimate: Taming Region-aware Diffusion Model for Realistic Human Interaction Animation
Apr 15, 2025Recent video generation research has focused heavily on isolated actions, leaving interactive motions-such as hand-face interactions-largely unexamined. These interactions are essential for emerging biometric authentication systems, which rely on interactive motion-based anti-spoofing approaches. From a security perspective, there is a growing need for large-scale, high-quality interactive videos to train and strengthen authentication models. In this work, we introduce a novel paradigm for animating realistic hand-face interactions. Our approach simultaneously learns spatio-temporal contact dynamics and biomechanically plausible deformation effects, enabling natural interactions where hand movements induce anatomically accurate facial deformations while maintaining collision-free contact. To facilitate this research, we present InterHF, a large-scale hand-face interaction dataset featuring 18 interaction patterns and 90,000 annotated videos. Additionally, we propose InterAnimate, a region-aware diffusion model designed specifically for interaction animation. InterAnimate leverages learnable spatial and temporal latents to effectively capture dynamic interaction priors and integrates a region-aware interaction mechanism that injects these priors into the denoising process. To the best of our knowledge, this work represents the first large-scale effort to systematically study human hand-face interactions. Qualitative and quantitative results show InterAnimate produces highly realistic animations, setting a new benchmark. Code and data will be made public to advance research.
High-Quality 3D Head Reconstruction from Any Single Portrait Image
Mar 11, 2025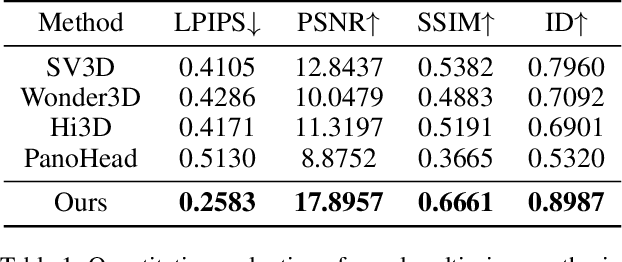
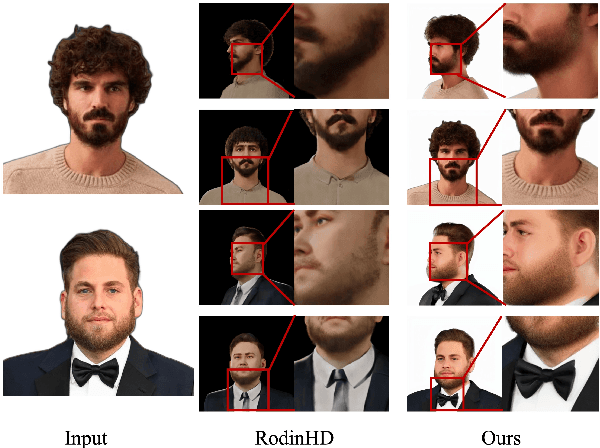
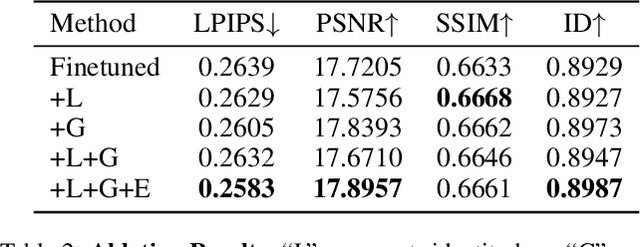
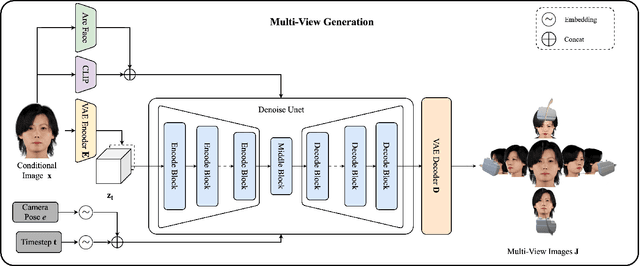
In this work, we introduce a novel high-fidelity 3D head reconstruction method from a single portrait image, regardless of perspective, expression, or accessories. Despite significant efforts in adapting 2D generative models for novel view synthesis and 3D optimization, most methods struggle to produce high-quality 3D portraits. The lack of crucial information, such as identity, expression, hair, and accessories, limits these approaches in generating realistic 3D head models. To address these challenges, we construct a new high-quality dataset containing 227 sequences of digital human portraits captured from 96 different perspectives, totalling 21,792 frames, featuring diverse expressions and accessories. To further improve performance, we integrate identity and expression information into the multi-view diffusion process to enhance facial consistency across views. Specifically, we apply identity- and expression-aware guidance and supervision to extract accurate facial representations, which guide the model and enforce objective functions to ensure high identity and expression consistency during generation. Finally, we generate an orbital video around the portrait consisting of 96 multi-view frames, which can be used for 3D portrait model reconstruction. Our method demonstrates robust performance across challenging scenarios, including side-face angles and complex accessories
GeneMAN: Generalizable Single-Image 3D Human Reconstruction from Multi-Source Human Data
Nov 27, 2024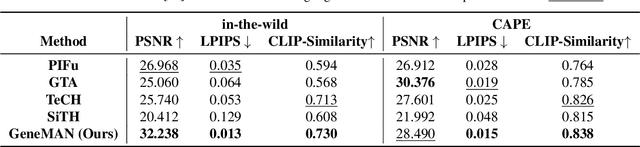


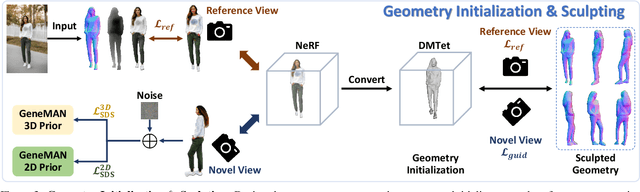
Given a single in-the-wild human photo, it remains a challenging task to reconstruct a high-fidelity 3D human model. Existing methods face difficulties including a) the varying body proportions captured by in-the-wild human images; b) diverse personal belongings within the shot; and c) ambiguities in human postures and inconsistency in human textures. In addition, the scarcity of high-quality human data intensifies the challenge. To address these problems, we propose a Generalizable image-to-3D huMAN reconstruction framework, dubbed GeneMAN, building upon a comprehensive multi-source collection of high-quality human data, including 3D scans, multi-view videos, single photos, and our generated synthetic human data. GeneMAN encompasses three key modules. 1) Without relying on parametric human models (e.g., SMPL), GeneMAN first trains a human-specific text-to-image diffusion model and a view-conditioned diffusion model, serving as GeneMAN 2D human prior and 3D human prior for reconstruction, respectively. 2) With the help of the pretrained human prior models, the Geometry Initialization-&-Sculpting pipeline is leveraged to recover high-quality 3D human geometry given a single image. 3) To achieve high-fidelity 3D human textures, GeneMAN employs the Multi-Space Texture Refinement pipeline, consecutively refining textures in the latent and the pixel spaces. Extensive experimental results demonstrate that GeneMAN could generate high-quality 3D human models from a single image input, outperforming prior state-of-the-art methods. Notably, GeneMAN could reveal much better generalizability in dealing with in-the-wild images, often yielding high-quality 3D human models in natural poses with common items, regardless of the body proportions in the input images.
DomainGallery: Few-shot Domain-driven Image Generation by Attribute-centric Finetuning
Nov 07, 2024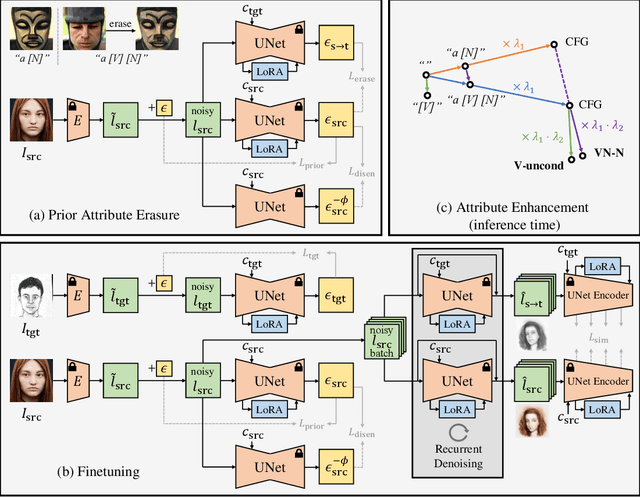
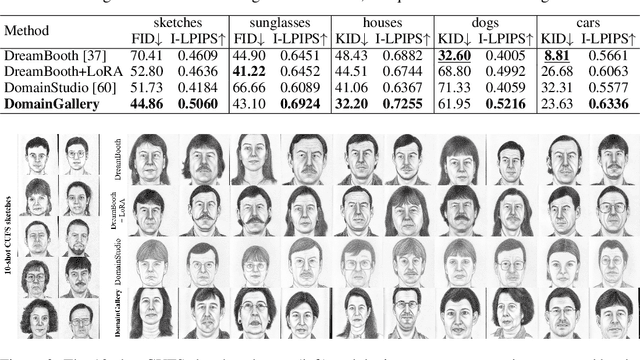


The recent progress in text-to-image models pretrained on large-scale datasets has enabled us to generate various images as long as we provide a text prompt describing what we want. Nevertheless, the availability of these models is still limited when we expect to generate images that fall into a specific domain either hard to describe or just unseen to the models. In this work, we propose DomainGallery, a few-shot domain-driven image generation method which aims at finetuning pretrained Stable Diffusion on few-shot target datasets in an attribute-centric manner. Specifically, DomainGallery features prior attribute erasure, attribute disentanglement, regularization and enhancement. These techniques are tailored to few-shot domain-driven generation in order to solve key issues that previous works have failed to settle. Extensive experiments are given to validate the superior performance of DomainGallery on a variety of domain-driven generation scenarios. Codes are available at https://github.com/Ldhlwh/DomainGallery.