 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent Video Colorization via Palette Guidance
Jan 31, 2025



Colorization is a traditional computer vision task and it plays an important role in many time-consuming tasks, such as old film restoration. Existing methods suffer from unsaturated color and temporally inconsistency. In this paper, we propose a novel pipeline to overcome the challenges. We regard the colorization task as a generative task and introduce Stable Video Diffusion (SVD) as our base model. We design a palette-based color guider to assist the model in generating vivid and consistent colors. The color context introduced by the palette not only provides guidance for color generation, but also enhances the stability of the generated colors through a unified color context across multiple sequences. Experiments demonstrate that the proposed method can provide vivid and stable colors for videos, surpassing previous methods.
Self-Supervised Vision Transformer for Enhanced Virtual Clothes Try-On
Jun 15, 2024Virtual clothes try-on has emerged as a vital feature in online shopping, offering consumers a critical tool to visualize how clothing fits. In our research, we introduce an innovative approach for virtual clothes try-on, utilizing a self-supervised Vision Transformer (ViT) coupled with a diffusion model. Our method emphasizes detail enhancement by contrasting local clothing image embeddings, generated by ViT, with their global counterparts. Techniques such as conditional guidance and focus on key regions have been integrated into our approach. These combined strategies empower the diffusion model to reproduce clothing details with increased clarity and realism. The experimental results showcase substantial advancements in the realism and precision of details in virtual try-on experiences, significantly surpassing the capabilities of existing technologies.
DreamCom: Finetuning Text-guided Inpainting Model for Image Composition
Sep 27, 2023

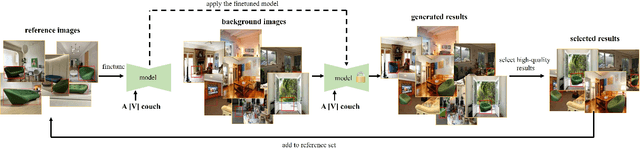

The goal of image composition is merging a foreground object into a background image to obtain a realistic composite image. Recently, generative composition methods are built on large pretrained diffusion models, due to their unprecedented image generation ability. They train a model on abundant pairs of foregrounds and backgrounds, so that it can be directly applied to a new pair of foreground and background at test time. However, the generated results often lose the foreground details and exhibit noticeable artifacts. In this work, we propose an embarrassingly simple approach named DreamCom inspired by DreamBooth. Specifically, given a few reference images for a subject, we finetune text-guided inpainting diffusion model to associate this subject with a special token and inpaint this subject in the specified bounding box. We also construct a new dataset named MureCom well-tailored for this task.
Painterly Image Harmonization using Diffusion Model
Aug 04, 2023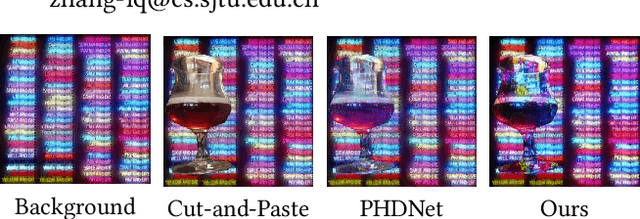

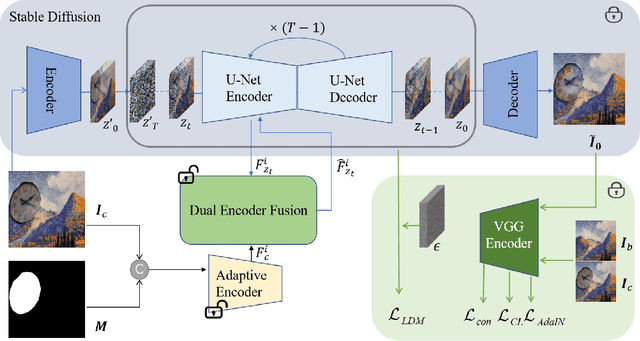
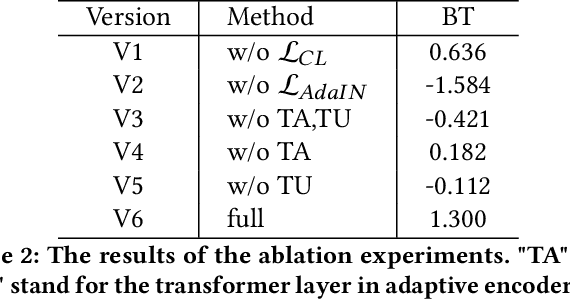
Painterly image harmonization aims to insert photographic objects into paintings and obtain artistically coherent composite images. Previous methods for this task mainly rely on inference optimization or generative adversarial network, but they are either very time-consuming or struggling at fine control of the foreground objects (e.g., texture and content details). To address these issues, we propose a novel Painterly Harmonization stable Diffusion model (PHDiffusion), which includes a lightweight adaptive encoder and a Dual Encoder Fusion (DEF) module. Specifically, the adaptive encoder and the DEF module first stylize foreground features within each encoder. Then, the stylized foreground features from both encoders are combined to guide the harmonization process. During training, besides the noise loss in diffusion model, we additionally employ content loss and two style losses, i.e., AdaIN style loss and contrastive style loss, aiming to balance the trade-off between style migration and content preservation. Compared with the state-of-the-art models from related fields, our PHDiffusion can stylize the foreground more sufficiently and simultaneously retain finer content. Our code and model are available at https://github.com/bcmi/PHDiffusion-Painterly-Image-Harmonization.