 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Guided Hyperspectral Object Tracking via Semantics Fusion and Contextual Template Updating
Jun 08, 2026Hyperspectral object tracking (HOT) leverages the rich spectral information provided by hyperspectral videos (HSVs), offering substantial potential for object tracking. However, efficiently extracting and exploiting spectral information from redundant spectral bands remains a fundamental challenge, which severely limits model generalization and tracking performance. Moreover, in dynamic scenes, targets often experience drastic appearance variations due to factors such as occlusion and illumination changes. These variations lead to large deformations between the current frame and the template. Such discrepancies pose major challenges for existing temporal modeling approaches. In this work, we propose VLHTrack, a novel hyperspectral vision-language (VL) joint tracking framework. Specifically, we incorporate language priors to address the fundamental challenge of spectral redundancy by designing a Language-Guided Band Selection Module (LBSM). By leveraging Large Language Model (LLM) descriptions, LBSM establishes a semantic-to-spectral mapping that mitigates redundancy and accentuates discriminative spectral features. A Multi-Modal Vision-Language Fusion Module is then employed to seamlessly integrate visual and linguistic embeddings, harnessing their complementary advantages to learn coherent cross-modal representations. To address target deformation in long-term sequences, we propose a dynamic update template feature strategy implemented via the Dynamic Template Update with Mamba (DTUM) module. By leveraging selective state space modeling, DTUM learns inter-frame dependencies to update template feature, ensuring efficient template feature evolution guided by temporal context. Experiments on HOT2023 and HOT2024 demonstrate that VLHTrack outperforms state-of-the-art (SOTA) methods.
$M^2$-VLA: Boosting Vision-Language Models for Generalizable Manipulation via Layer Mixture and Meta-Skills
Apr 27, 2026Current Vision-Language-Action (VLA) models predominantly rely on end-to-end fine-tuning. While effective, this paradigm compromises the inherent generalization capabilities of Vision-Language Models (VLMs) and incurs catastrophic forgetting. To address these limitations, we propose $M^2$-VLA, which demonstrates that a generalized VLM is able to serve as a powerful backbone for robotic manipulation directly. However, it remains a key challenge to bridge the gap between the high-level semantic understanding of VLMs and the precise requirements of robotic control. To overcome this, we introduce the Mixture of Layers (MoL) strategy that selectively extracts task-critical information from dense semantic features. Furthermore, to facilitate efficient trajectory learning under constrained model capacity, we propose a Meta Skill Module (MSM) that integrates strong inductive biases. Extensive experiments in both simulated and real-world environments demonstrate the effectiveness of our approach. Furthermore, generalization and ablation studies validate the architecture's zero-shot capabilities and confirm the contribution of each key component. Our code and pre-trained models will be made publicly available.
Motion2Motion: Cross-topology Motion Transfer with Sparse Correspondence
Aug 18, 2025

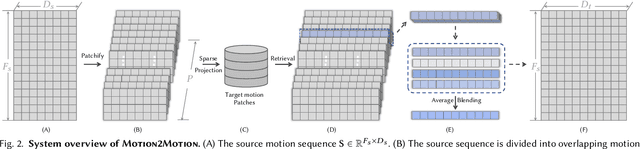

This work studies the challenge of transfer animations between characters whose skeletal topologies differ substantially. While many techniques have advanced retargeting techniques in decades, transfer motions across diverse topologies remains less-explored. The primary obstacle lies in the inherent topological inconsistency between source and target skeletons, which restricts the establishment of straightforward one-to-one bone correspondences. Besides, the current lack of large-scale paired motion datasets spanning different topological structures severely constrains the development of data-driven approaches. To address these limitations, we introduce Motion2Motion, a novel, training-free framework. Simply yet effectively, Motion2Motion works with only one or a few example motions on the target skeleton, by accessing a sparse set of bone correspondences between the source and target skeletons. Through comprehensive qualitative and quantitative evaluations, we demonstrate that Motion2Motion achieves efficient and reliable performance in both similar-skeleton and cross-species skeleton transfer scenarios. The practical utility of our approach is further evidenced by its successful integration in downstream applications and user interfaces, highlighting its potential for industrial applications. Code and data are available at https://lhchen.top/Motion2Motion.
AnimeColor: Reference-based Animation Colorization with Diffusion Transformers
Jul 27, 2025Animation colorization plays a vital role in animation production, yet existing methods struggle to achieve color accuracy and temporal consistency. To address these challenges, we propose \textbf{AnimeColor}, a novel reference-based animation colorization framework leveraging Diffusion Transformers (DiT). Our approach integrates sketch sequences into a DiT-based video diffusion model, enabling sketch-controlled animation generation. We introduce two key components: a High-level Color Extractor (HCE) to capture semantic color information and a Low-level Color Guider (LCG) to extract fine-grained color details from reference images. These components work synergistically to guide the video diffusion process. Additionally, we employ a multi-stage training strategy to maximize the utilization of reference image color information. Extensive experiments demonstrate that AnimeColor outperforms existing methods in color accuracy, sketch alignment, temporal consistency, and visual quality. Our framework not only advances the state of the art in animation colorization but also provides a practical solution for industrial applications. The code will be made publicly available at \href{https://github.com/IamCreateAI/AnimeColor}{https://github.com/IamCreateAI/AnimeColor}.
Graph Representations for Reading Comprehension Analysis using Large Language Model and Eye-Tracking Biomarker
Jul 16, 2025Reading comprehension is a fundamental skill in human cognitive development. With the advancement of Large Language Models (LLMs), there is a growing need to compare how humans and LLMs understand language across different contexts and apply this understanding to functional tasks such as inference, emotion interpretation, and information retrieval. Our previous work used LLMs and human biomarkers to study the reading comprehension process. The results showed that the biomarkers corresponding to words with high and low relevance to the inference target, as labeled by the LLMs, exhibited distinct patterns, particularly when validated using eye-tracking data. However, focusing solely on individual words limited the depth of understanding, which made the conclusions somewhat simplistic despite their potential significance. This study used an LLM-based AI agent to group words from a reading passage into nodes and edges, forming a graph-based text representation based on semantic meaning and question-oriented prompts. We then compare the distribution of eye fixations on important nodes and edges. Our findings indicate that LLMs exhibit high consistency in language understanding at the level of graph topological structure. These results build on our previous findings and offer insights into effective human-AI co-learning strategies.
NOVA3D: Normal Aligned Video Diffusion Model for Single Image to 3D Generation
Jun 09, 2025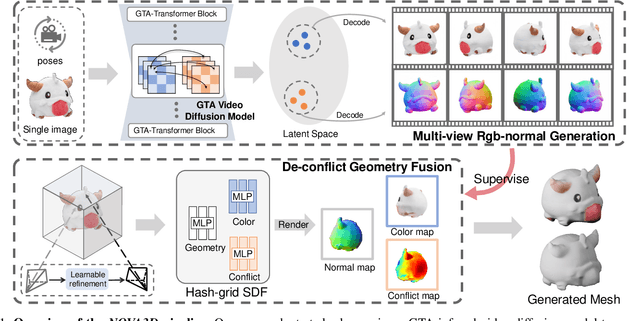
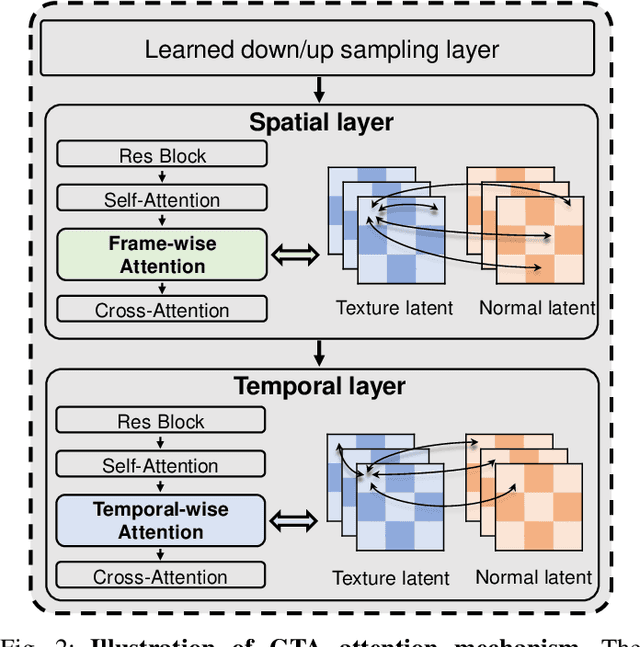


3D AI-generated content (AIGC) has made it increasingly accessible for anyone to become a 3D content creator. While recent methods leverage Score Distillation Sampling to distill 3D objects from pretrained image diffusion models, they often suffer from inadequate 3D priors, leading to insufficient multi-view consistency. In this work, we introduce NOVA3D, an innovative single-image-to-3D generation framework. Our key insight lies in leveraging strong 3D priors from a pretrained video diffusion model and integrating geometric information during multi-view video fine-tuning. To facilitate information exchange between color and geometric domains, we propose the Geometry-Temporal Alignment (GTA) attention mechanism, thereby improving generalization and multi-view consistency. Moreover, we introduce the de-conflict geometry fusion algorithm, which improves texture fidelity by addressing multi-view inaccuracies and resolving discrepancies in pose alignment. Extensive experiments validate the superiority of NOVA3D over existing baselines.
HumanMM: Global Human Motion Recovery from Multi-shot Videos
Mar 10, 2025In this paper, we present a novel framework designed to reconstruct long-sequence 3D human motion in the world coordinates from in-the-wild videos with multiple shot transitions. Such long-sequence in-the-wild motions are highly valuable to applications such as motion generation and motion understanding, but are of great challenge to be recovered due to abrupt shot transitions, partial occlusions, and dynamic backgrounds presented in such videos. Existing methods primarily focus on single-shot videos, where continuity is maintained within a single camera view, or simplify multi-shot alignment in camera space only. In this work, we tackle the challenges by integrating an enhanced camera pose estimation with Human Motion Recovery (HMR) by incorporating a shot transition detector and a robust alignment module for accurate pose and orientation continuity across shots. By leveraging a custom motion integrator, we effectively mitigate the problem of foot sliding and ensure temporal consistency in human pose. Extensive evaluations on our created multi-shot dataset from public 3D human datasets demonstrate the robustness of our method in reconstructing realistic human motion in world coordinates.
Frequency-Based Alignment of EEG and Audio Signals Using Contrastive Learning and SincNet for Auditory Attention Detection
Mar 06, 2025Humans exhibit a remarkable ability to focus auditory attention in complex acoustic environments, such as cocktail parties. Auditory attention detection (AAD) aims to identify the attended speaker by analyzing brain signals, such as electroencephalography (EEG) data. Existing AAD algorithms often leverage deep learning's powerful nonlinear modeling capabilities, few consider the neural mechanisms underlying auditory processing in the brain. In this paper, we propose SincAlignNet, a novel network based on an improved SincNet and contrastive learning, designed to align audio and EEG features for auditory attention detection. The SincNet component simulates the brain's processing of audio during auditory attention, while contrastive learning guides the model to learn the relationship between EEG signals and attended speech. During inference, we calculate the cosine similarity between EEG and audio features and also explore direct inference of the attended speaker using EEG data. Cross-trial evaluations results demonstrate that SincAlignNet outperforms state-of-the-art AAD methods on two publicly available datasets, KUL and DTU, achieving average accuracies of 78.3% and 92.2%, respectively, with a 1-second decision window. The model exhibits strong interpretability, revealing that the left and right temporal lobes are more active during both male and female speaker scenarios. Furthermore, we found that using data from only six electrodes near the temporal lobes maintains similar or even better performance compared to using 64 electrodes. These findings indicate that efficient low-density EEG online decoding is achievable, marking an important step toward the practical implementation of neuro-guided hearing aids in real-world applications. Code is available at: https://github.com/LiaoEuan/SincAlignNet.
Consistent Video Colorization via Palette Guidance
Jan 31, 2025



Colorization is a traditional computer vision task and it plays an important role in many time-consuming tasks, such as old film restoration. Existing methods suffer from unsaturated color and temporally inconsistency. In this paper, we propose a novel pipeline to overcome the challenges. We regard the colorization task as a generative task and introduce Stable Video Diffusion (SVD) as our base model. We design a palette-based color guider to assist the model in generating vivid and consistent colors. The color context introduced by the palette not only provides guidance for color generation, but also enhances the stability of the generated colors through a unified color context across multiple sequences. Experiments demonstrate that the proposed method can provide vivid and stable colors for videos, surpassing previous methods.
Motion-X++: A Large-Scale Multimodal 3D Whole-body Human Motion Dataset
Jan 09, 2025



In this paper, we introduce Motion-X++, a large-scale multimodal 3D expressive whole-body human motion dataset. Existing motion datasets predominantly capture body-only poses, lacking facial expressions, hand gestures, and fine-grained pose descriptions, and are typically limited to lab settings with manually labeled text descriptions, thereby restricting their scalability. To address this issue, we develop a scalable annotation pipeline that can automatically capture 3D whole-body human motion and comprehensive textural labels from RGB videos and build the Motion-X dataset comprising 81.1K text-motion pairs. Furthermore, we extend Motion-X into Motion-X++ by improving the annotation pipeline, introducing more data modalities, and scaling up the data quantities. Motion-X++ provides 19.5M 3D whole-body pose annotations covering 120.5K motion sequences from massive scenes, 80.8K RGB videos, 45.3K audios, 19.5M frame-level whole-body pose descriptions, and 120.5K sequence-level semantic labels. Comprehensive experiments validate the accuracy of our annotation pipeline and highlight Motion-X++'s significant benefits for generating expressive, precise, and natural motion with paired multimodal labels supporting several downstream tasks, including text-driven whole-body motion generation,audio-driven motion generation, 3D whole-body human mesh recovery, and 2D whole-body keypoints estimation, etc.