 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamSwapV: Mask-guided Subject Swapping for Any Customized Video Editing
Aug 20, 2025With the rapid progress of video generation, demand for customized video editing is surging, where subject swapping constitutes a key component yet remains under-explored. Prevailing swapping approaches either specialize in narrow domains--such as human-body animation or hand-object interaction--or rely on some indirect editing paradigm or ambiguous text prompts that compromise final fidelity. In this paper, we propose DreamSwapV, a mask-guided, subject-agnostic, end-to-end framework that swaps any subject in any video for customization with a user-specified mask and reference image. To inject fine-grained guidance, we introduce multiple conditions and a dedicated condition fusion module that integrates them efficiently. In addition, an adaptive mask strategy is designed to accommodate subjects of varying scales and attributes, further improving interactions between the swapped subject and its surrounding context. Through our elaborate two-phase dataset construction and training scheme, our DreamSwapV outperforms existing methods, as validated by comprehensive experiments on VBench indicators and our first introduced DreamSwapV-Benchmark.
Make Your MoVe: Make Your 3D Contents by Adapting Multi-View Diffusion Models to External Editing
Aug 11, 2025As 3D generation techniques continue to flourish, the demand for generating personalized content is rapidly rising. Users increasingly seek to apply various editing methods to polish generated 3D content, aiming to enhance its color, style, and lighting without compromising the underlying geometry. However, most existing editing tools focus on the 2D domain, and directly feeding their results into 3D generation methods (like multi-view diffusion models) will introduce information loss, degrading the quality of the final 3D assets. In this paper, we propose a tuning-free, plug-and-play scheme that aligns edited assets with their original geometry in a single inference run. Central to our approach is a geometry preservation module that guides the edited multi-view generation with original input normal latents. Besides, an injection switcher is proposed to deliberately control the supervision extent of the original normals, ensuring the alignment between the edited color and normal views. Extensive experiments show that our method consistently improves both the multi-view consistency and mesh quality of edited 3D assets, across multiple combinations of multi-view diffusion models and editing methods.
NOVA3D: Normal Aligned Video Diffusion Model for Single Image to 3D Generation
Jun 09, 2025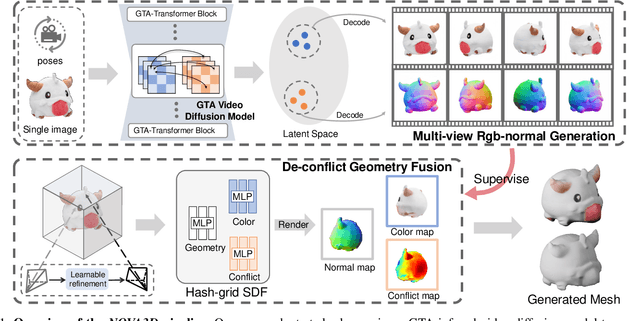
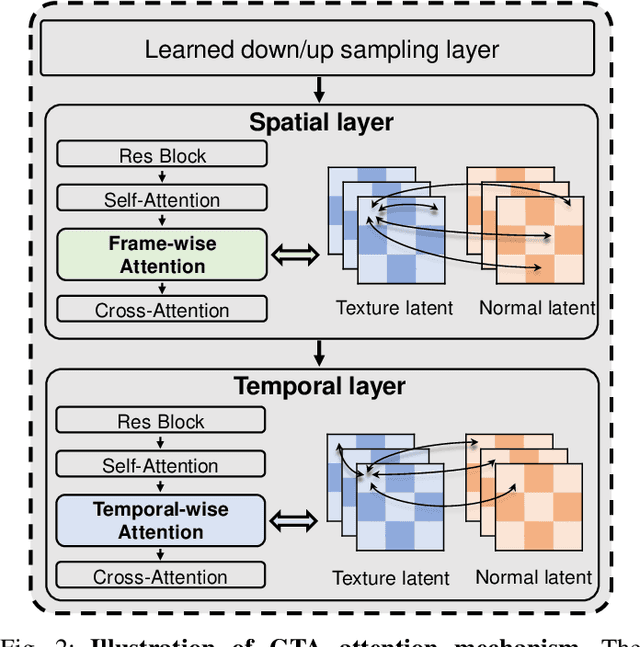


3D AI-generated content (AIGC) has made it increasingly accessible for anyone to become a 3D content creator. While recent methods leverage Score Distillation Sampling to distill 3D objects from pretrained image diffusion models, they often suffer from inadequate 3D priors, leading to insufficient multi-view consistency. In this work, we introduce NOVA3D, an innovative single-image-to-3D generation framework. Our key insight lies in leveraging strong 3D priors from a pretrained video diffusion model and integrating geometric information during multi-view video fine-tuning. To facilitate information exchange between color and geometric domains, we propose the Geometry-Temporal Alignment (GTA) attention mechanism, thereby improving generalization and multi-view consistency. Moreover, we introduce the de-conflict geometry fusion algorithm, which improves texture fidelity by addressing multi-view inaccuracies and resolving discrepancies in pose alignment. Extensive experiments validate the superiority of NOVA3D over existing baselines.
MVReward: Better Aligning and Evaluating Multi-View Diffusion Models with Human Preferences
Dec 09, 2024



Recent years have witnessed remarkable progress in 3D content generation. However, corresponding evaluation methods struggle to keep pace. Automatic approaches have proven challenging to align with human preferences, and the mixed comparison of text- and image-driven methods often leads to unfair evaluations. In this paper, we present a comprehensive framework to better align and evaluate multi-view diffusion models with human preferences. To begin with, we first collect and filter a standardized image prompt set from DALL$\cdot$E and Objaverse, which we then use to generate multi-view assets with several multi-view diffusion models. Through a systematic ranking pipeline on these assets, we obtain a human annotation dataset with 16k expert pairwise comparisons and train a reward model, coined MVReward, to effectively encode human preferences. With MVReward, image-driven 3D methods can be evaluated against each other in a more fair and transparent manner. Building on this, we further propose Multi-View Preference Learning (MVP), a plug-and-play multi-view diffusion tuning strategy. Extensive experiments demonstrate that MVReward can serve as a reliable metric and MVP consistently enhances the alignment of multi-view diffusion models with human preferences.
Gaussian in the Wild: 3D Gaussian Splatting for Unconstrained Image Collections
Mar 23, 2024Novel view synthesis from unconstrained in-the-wild images remains a meaningful but challenging task. The photometric variation and transient occluders in those unconstrained images make it difficult to reconstruct the original scene accurately. Previous approaches tackle the problem by introducing a global appearance feature in Neural Radiance Fields (NeRF). However, in the real world, the unique appearance of each tiny point in a scene is determined by its independent intrinsic material attributes and the varying environmental impacts it receives. Inspired by this fact, we propose Gaussian in the wild (GS-W), a method that uses 3D Gaussian points to reconstruct the scene and introduces separated intrinsic and dynamic appearance feature for each point, capturing the unchanged scene appearance along with dynamic variation like illumination and weather. Additionally, an adaptive sampling strategy is presented to allow each Gaussian point to focus on the local and detailed information more effectively. We also reduce the impact of transient occluders using a 2D visibility map. More experiments have demonstrated better reconstruction quality and details of GS-W compared to previous methods, with a $1000\times$ increase in rendering speed.
A Comprehensive Survey for Evaluation Methodologies of AI-Generated Music
Aug 26, 2023In recent years, AI-generated music has made significant progress, with several models performing well in multimodal and complex musical genres and scenes. While objective metrics can be used to evaluate generative music, they often lack interpretability for musical evaluation. Therefore, researchers often resort to subjective user studies to assess the quality of the generated works, which can be resource-intensive and less reproducible than objective metrics. This study aims to comprehensively evaluate the subjective, objective, and combined methodologies for assessing AI-generated music, highlighting the advantages and disadvantages of each approach. Ultimately, this study provides a valuable reference for unifying generative AI in the field of music evaluation.
Scissorhands: Exploiting the Persistence of Importance Hypothesis for LLM KV Cache Compression at Test Time
May 26, 2023



Large language models(LLMs) have sparked a new wave of exciting AI applications. Hosting these models at scale requires significant memory resources. One crucial memory bottleneck for the deployment stems from the context window. It is commonly recognized that model weights are memory hungry; however, the size of key-value embedding stored during the generation process (KV cache) can easily surpass the model size. The enormous size of the KV cache puts constraints on the inference batch size, which is crucial for high throughput inference workload. Inspired by an interesting observation of the attention scores, we hypothesize the persistence of importance: only pivotal tokens, which had a substantial influence at one step, will significantly influence future generations. Based on our empirical verification and theoretical analysis around this hypothesis, we propose Scissorhands, a system that maintains the memory usage of the KV cache at a fixed budget without finetuning the model. In essence, Scissorhands manages the KV cache by storing the pivotal tokens with a higher probability. We validate that Scissorhands reduces the inference memory usage of the KV cache by up to 5X without compromising model quality. We further demonstrate that Scissorhands can be combined with 4-bit quantization, traditionally used to compress model weights, to achieve up to 20X compression.
Learning Deep Robotic Skills on Riemannian manifolds
Oct 27, 2022In this paper, we propose RiemannianFlow, a deep generative model that allows robots to learn complex and stable skills evolving on Riemannian manifolds. Examples of Riemannian data in robotics include stiffness (symmetric and positive definite matrix (SPD)) and orientation (unit quaternion (UQ)) trajectories. For Riemannian data, unlike Euclidean ones, different dimensions are interconnected by geometric constraints which have to be properly considered during the learning process. Using distance preserving mappings, our approach transfers the data between their original manifold and the tangent space, realizing the removing and re-fulfilling of the geometric constraints. This allows to extend existing frameworks to learn stable skills from Riemannian data while guaranteeing the stability of the learning results. The ability of RiemannianFlow to learn various data patterns and the stability of the learned models are experimentally shown on a dataset of manifold motions. Further, we analyze from different perspectives the robustness of the model with different hyperparameter combinations. It turns out that the model's stability is not affected by different hyperparameters, a proper combination of the hyperparameters leads to a significant improvement (up to 27.6%) of the model accuracy. Last, we show the effectiveness of RiemannianFlow in a real peg-in-hole (PiH) task where we need to generate stable and consistent position and orientation trajectories for the robot starting from different initial poses.