 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference Time Context Sparsity: Illusion or Opportunity?
May 22, 2026Sparsity has long been a central theme in LLM efficiency, but its role in context processing remains unresolved. As LLM workloads shift toward longer contexts and agentic interactions, the compute and memory bottlenecks of attention become increasingly critical, raising the question of whether these constraints are fundamental. Our position is that these constraints are artificial and unnecessary, and that the future of LLM inference lies in extreme but principled sparsity along the context dimension. This position is supported by several strands of empirical and theoretical evidence. First, we find the insistence on dense attention unreasonable, since in a long context a query effectively projects O(N) attention information into a hidden space of dimension d << N, making the process inherently lossy. Second, we perform an extensive study of sparsity in LLMs spanning 20 models across five model families, varying context lengths, and different sparsity levels. We empirically demonstrate a strong trend: current LLMs, despite not being trained for context sparsity, are remarkably robust to inference-time decode sparsity across tasks of varying complexity, including retrieval, multi-hop QA, mathematical reasoning, and agentic coding. Importantly, we also show that current hardware is already sufficient to realize substantial gains from this sparsity. For example, our sparse decode kernels accelerate large-context processing by up to 10x over FlashInfer at 50x sparsity levels on hardware such as the H100. Overall, these results position extreme context sparsity not as a heuristic, but as a principled foundation for LLM inference, training, and architecture design: one that is both feasible and beneficial, and a compelling direction for future systems.
SOCKET: SOft Collison Kernel EsTimator for Sparse Attention
Feb 06, 2026Exploiting sparsity during long-context inference is central to scaling large language models, as attention dominates the cost of autoregressive decoding. Sparse attention reduces this cost by restricting computation to a subset of tokens, but its effectiveness depends critically on efficient scoring and selection of relevant tokens at inference time. We revisit Locality-Sensitive Hashing (LSH) as a sparsification primitive and introduce SOCKET, a SOft Collision Kernel EsTimator that replaces hard bucket matches with probabilistic, similarity-aware aggregation. Our key insight is that hard LSH produces discrete collision signals and is therefore poorly suited for ranking. In contrast, soft LSH aggregates graded collision evidence across hash tables, preserving the stability of relative ordering among the true top-$k$ tokens. This transformation elevates LSH from a candidate-generation heuristic to a principled and mathematically grounded scoring kernel for sparse attention. Leveraging this property, SOCKET enables efficient token selection without ad-hoc voting mechanism, and matches or surpasses established sparse attention baselines across multiple long-context benchmarks using diverse set of models. With a custom CUDA kernel for scoring keys and a Flash Decode Triton backend for sparse attention, SOCKET achieves up to 1.5$\times$ higher throughput than FlashAttention, making it an effective tool for long-context inference. Code is open-sourced at https://github.com/amarka8/SOCKET.
Let the Barbarians In: How AI Can Accelerate Systems Performance Research
Dec 22, 2025Artificial Intelligence (AI) is beginning to transform the research process by automating the discovery of new solutions. This shift depends on the availability of reliable verifiers, which AI-driven approaches require to validate candidate solutions. Research focused on improving systems performance is especially well-suited to this paradigm because system performance problems naturally admit such verifiers: candidates can be implemented in real systems or simulators and evaluated against predefined workloads. We term this iterative cycle of generation, evaluation, and refinement AI-Driven Research for Systems (ADRS). Using several open-source ADRS instances (i.e., OpenEvolve, GEPA, and ShinkaEvolve), we demonstrate across ten case studies (e.g., multi-region cloud scheduling, mixture-of-experts load balancing, LLM-based SQL, transaction scheduling) that ADRS-generated solutions can match or even outperform human state-of-the-art designs. Based on these findings, we outline best practices (e.g., level of prompt specification, amount of feedback, robust evaluation) for effectively using ADRS, and we discuss future research directions and their implications. Although we do not yet have a universal recipe for applying ADRS across all of systems research, we hope our preliminary findings, together with the challenges we identify, offer meaningful guidance for future work as researcher effort shifts increasingly toward problem formulation and strategic oversight. Note: This paper is an extension of our prior work [14]. It adds extensive evaluation across multiple ADRS frameworks and provides deeper analysis and insights into best practices.
The Danger of Overthinking: Examining the Reasoning-Action Dilemma in Agentic Tasks
Feb 12, 2025



Large Reasoning Models (LRMs) represent a breakthrough in AI problem-solving capabilities, but their effectiveness in interactive environments can be limited. This paper introduces and analyzes overthinking in LRMs. A phenomenon where models favor extended internal reasoning chains over environmental interaction. Through experiments on software engineering tasks using SWE Bench Verified, we observe three recurring patterns: Analysis Paralysis, Rogue Actions, and Premature Disengagement. We propose a framework to study these behaviors, which correlates with human expert assessments, and analyze 4018 trajectories. We observe that higher overthinking scores correlate with decreased performance, with reasoning models exhibiting stronger tendencies toward overthinking compared to non-reasoning models. Our analysis reveals that simple efforts to mitigate overthinking in agentic environments, such as selecting the solution with the lower overthinking score, can improve model performance by almost 30% while reducing computational costs by 43%. These results suggest that mitigating overthinking has strong practical implications. We suggest that by leveraging native function-calling capabilities and selective reinforcement learning overthinking tendencies could be mitigated. We also open-source our evaluation framework and dataset to facilitate research in this direction at https://github.com/AlexCuadron/Overthinking.
HashAttention: Semantic Sparsity for Faster Inference
Dec 19, 2024



Utilizing longer contexts is increasingly essential to power better AI systems. However, the cost of attending to long contexts is high due to the involved softmax computation. While the scaled dot-product attention (SDPA) exhibits token sparsity, with only a few pivotal tokens significantly contributing to attention, leveraging this sparsity effectively remains an open challenge. Previous methods either suffer from model degradation or require considerable additional resources. We propose HashAttention --a principled approach casting pivotal token identification as a recommendation problem. Given a query, HashAttention encodes keys and queries in Hamming space capturing the required semantic similarity using learned mapping functions. HashAttention efficiently identifies pivotal tokens for a given query in this Hamming space using bitwise operations, and only these pivotal tokens are used for attention computation, significantly improving overall attention efficiency. HashAttention can reduce the number of tokens used by a factor of $1/32\times$ for the Llama-3.1-8B model with LongBench, keeping average quality loss within 0.6 points, while using only 32 bits per token auxiliary memory. At $32\times$ sparsity, HashAttention is $3{-}6\times$ faster than LightLLM and $2.5{-}4.5\times$ faster than gpt-fast on Nvidia-L4 GPU.
IDentity with Locality: An ideal hash for gene sequence search
Jun 21, 2024



Gene sequence search is a fundamental operation in computational genomics. Due to the petabyte scale of genome archives, most gene search systems now use hashing-based data structures such as Bloom Filters (BF). The state-of-the-art systems such as Compact bit-slicing signature index (COBS) and Repeated And Merged Bloom filters (RAMBO) use BF with Random Hash (RH) functions for gene representation and identification. The standard recipe is to cast the gene search problem as a sequence of membership problems testing if each subsequent gene substring (called kmer) of Q is present in the set of kmers of the entire gene database D. We observe that RH functions, which are crucial to the memory and the computational advantage of BF, are also detrimental to the system performance of gene-search systems. While subsequent kmers being queried are likely very similar, RH, oblivious to any similarity, uniformly distributes the kmers to different parts of potentially large BF, thus triggering excessive cache misses and causing system slowdown. We propose a novel hash function called the Identity with Locality (IDL) hash family, which co-locates the keys close in input space without causing collisions. This approach ensures both cache locality and key preservation. IDL functions can be a drop-in replacement for RH functions and help improve the performance of information retrieval systems. We give a simple but practical construction of IDL function families and show that replacing the RH with IDL functions reduces cache misses by a factor of 5x, thus improving query and indexing times of SOTA methods such as COBS and RAMBO by factors up to 2x without compromising their quality. We also provide a theoretical analysis of the false positive rate of BF with IDL functions. Our hash function is the first study that bridges Locality Sensitive Hash (LSH) and RH to obtain cache efficiency.
Heterogeneous federated collaborative filtering using FAIR: Federated Averaging in Random Subspaces
Nov 03, 2023



Recommendation systems (RS) for items (e.g., movies, books) and ads are widely used to tailor content to users on various internet platforms. Traditionally, recommendation models are trained on a central server. However, due to rising concerns for data privacy and regulations like the GDPR, federated learning is an increasingly popular paradigm in which data never leaves the client device. Applying federated learning to recommendation models is non-trivial due to large embedding tables, which often exceed the memory constraints of most user devices. To include data from all devices in federated learning, we must enable collective training of embedding tables on devices with heterogeneous memory capacities. Current solutions to heterogeneous federated learning can only accommodate a small range of capacities and thus limit the number of devices that can participate in training. We present Federated Averaging in Random subspaces (FAIR), which allows arbitrary compression of embedding tables based on device capacity and ensures the participation of all devices in training. FAIR uses what we call consistent and collapsible subspaces defined by hashing-based random projections to jointly train large embedding tables while using varying amounts of compression on user devices. We evaluate FAIR on Neural Collaborative Filtering tasks with multiple datasets and verify that FAIR can gather and share information from a wide range of devices with varying capacities, allowing for seamless collaboration. We prove the convergence of FAIR in the homogeneous setting with non-i.i.d data distribution. Our code is open source at {https://github.com/apd10/FLCF}
In defense of parameter sharing for model-compression
Oct 17, 2023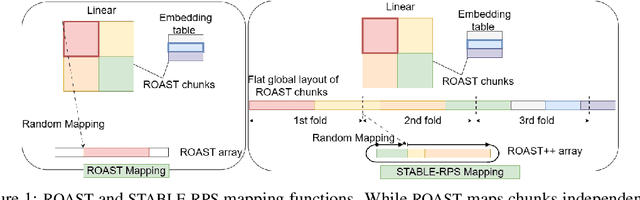



When considering a model architecture, there are several ways to reduce its memory footprint. Historically, popular approaches included selecting smaller architectures and creating sparse networks through pruning. More recently, randomized parameter-sharing (RPS) methods have gained traction for model compression at start of training. In this paper, we comprehensively assess the trade-off between memory and accuracy across RPS, pruning techniques, and building smaller models. Our findings demonstrate that RPS, which is both data and model-agnostic, consistently outperforms/matches smaller models and all moderately informed pruning strategies, such as MAG, SNIP, SYNFLOW, and GRASP, across the entire compression range. This advantage becomes particularly pronounced in higher compression scenarios. Notably, even when compared to highly informed pruning techniques like Lottery Ticket Rewinding (LTR), RPS exhibits superior performance in high compression settings. This points out inherent capacity advantage that RPS enjoys over sparse models. Theoretically, we establish RPS as a superior technique in terms of memory-efficient representation when compared to pruning for linear models. This paper argues in favor of paradigm shift towards RPS based models. During our rigorous evaluation of RPS, we identified issues in the state-of-the-art RPS technique ROAST, specifically regarding stability (ROAST's sensitivity to initialization hyperparameters, often leading to divergence) and Pareto-continuity (ROAST's inability to recover the accuracy of the original model at zero compression). We provably address both of these issues. We refer to the modified RPS, which incorporates our improvements, as STABLE-RPS.
Scissorhands: Exploiting the Persistence of Importance Hypothesis for LLM KV Cache Compression at Test Time
May 26, 2023



Large language models(LLMs) have sparked a new wave of exciting AI applications. Hosting these models at scale requires significant memory resources. One crucial memory bottleneck for the deployment stems from the context window. It is commonly recognized that model weights are memory hungry; however, the size of key-value embedding stored during the generation process (KV cache) can easily surpass the model size. The enormous size of the KV cache puts constraints on the inference batch size, which is crucial for high throughput inference workload. Inspired by an interesting observation of the attention scores, we hypothesize the persistence of importance: only pivotal tokens, which had a substantial influence at one step, will significantly influence future generations. Based on our empirical verification and theoretical analysis around this hypothesis, we propose Scissorhands, a system that maintains the memory usage of the KV cache at a fixed budget without finetuning the model. In essence, Scissorhands manages the KV cache by storing the pivotal tokens with a higher probability. We validate that Scissorhands reduces the inference memory usage of the KV cache by up to 5X without compromising model quality. We further demonstrate that Scissorhands can be combined with 4-bit quantization, traditionally used to compress model weights, to achieve up to 20X compression.
The trade-offs of model size in large recommendation models : A 10000 $\times$ compressed criteo-tb DLRM model
Jul 21, 2022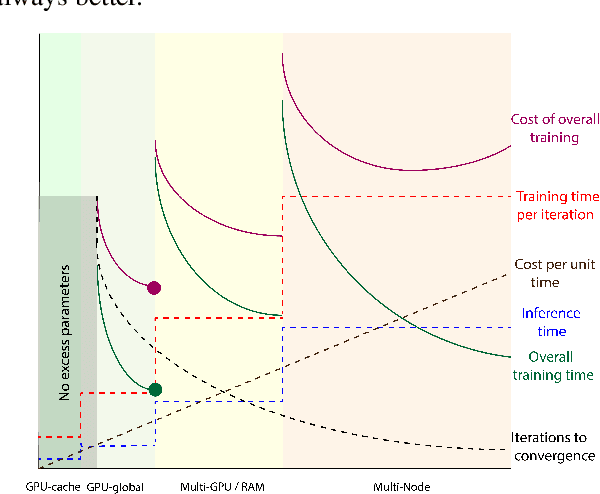
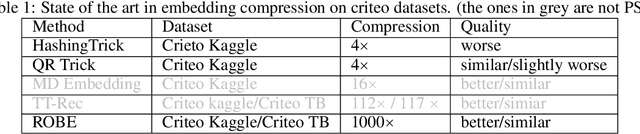


Embedding tables dominate industrial-scale recommendation model sizes, using up to terabytes of memory. A popular and the largest publicly available machine learning MLPerf benchmark on recommendation data is a Deep Learning Recommendation Model (DLRM) trained on a terabyte of click-through data. It contains 100GB of embedding memory (25+Billion parameters). DLRMs, due to their sheer size and the associated volume of data, face difficulty in training, deploying for inference, and memory bottlenecks due to large embedding tables. This paper analyzes and extensively evaluates a generic parameter sharing setup (PSS) for compressing DLRM models. We show theoretical upper bounds on the learnable memory requirements for achieving $(1 \pm \epsilon)$ approximations to the embedding table. Our bounds indicate exponentially fewer parameters suffice for good accuracy. To this end, we demonstrate a PSS DLRM reaching 10000$\times$ compression on criteo-tb without losing quality. Such a compression, however, comes with a caveat. It requires 4.5 $\times$ more iterations to reach the same saturation quality. The paper argues that this tradeoff needs more investigations as it might be significantly favorable. Leveraging the small size of the compressed model, we show a 4.3$\times$ improvement in training latency leading to similar overall training times. Thus, in the tradeoff between system advantage of a small DLRM model vs. slower convergence, we show that scales are tipped towards having a smaller DLRM model, leading to faster inference, easier deployment, and similar training times.