 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Offset Block Embedding Array (ROBE) for CriteoTB Benchmark MLPerf DLRM Model : 1000$\times$ Compression and 2.7$\times$ Faster Inference
Aug 04, 2021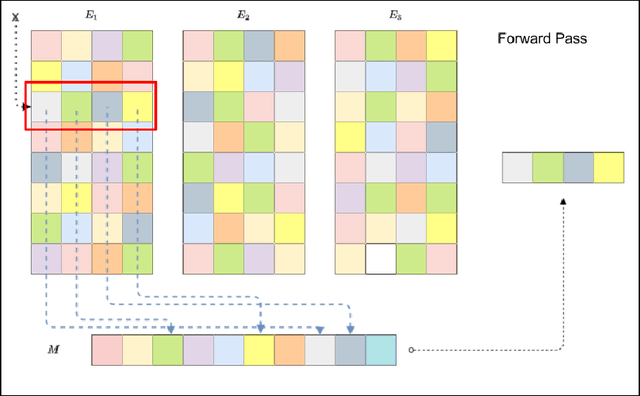

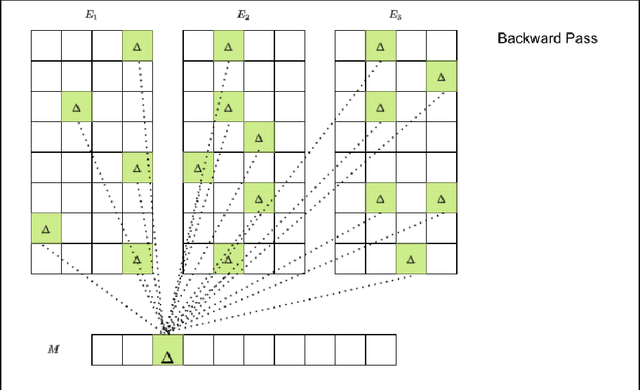
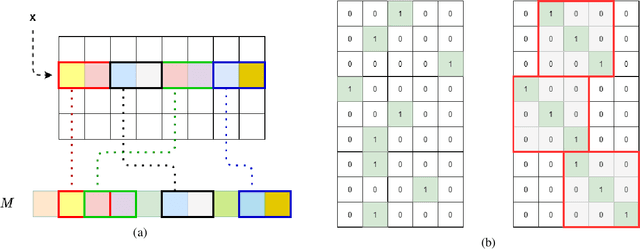
Deep learning for recommendation data is the one of the most pervasive and challenging AI workload in recent times. State-of-the-art recommendation models are one of the largest models rivalling the likes of GPT-3 and Switch Transformer. Challenges in deep learning recommendation models (DLRM) stem from learning dense embeddings for each of the categorical values. These embedding tables in industrial scale models can be as large as hundreds of terabytes. Such large models lead to a plethora of engineering challenges, not to mention prohibitive communication overheads, and slower training and inference times. Of these, slower inference time directly impacts user experience. Model compression for DLRM is gaining traction and the community has recently shown impressive compression results. In this paper, we present Random Offset Block Embedding Array (ROBE) as a low memory alternative to embedding tables which provide orders of magnitude reduction in memory usage while maintaining accuracy and boosting execution speed. ROBE is a simple fundamental approach in improving both cache performance and the variance of randomized hashing, which could be of independent interest in itself. We demonstrate that we can successfully train DLRM models with same accuracy while using $1000 \times$ less memory. A $1000\times$ compressed model directly results in faster inference without any engineering. In particular, we show that we can train DLRM model using ROBE Array of size 100MB on a single GPU to achieve AUC of 0.8025 or higher as required by official MLPerf CriteoTB benchmark DLRM model of 100GB while achieving about $2.7\times$ (170\%) improvement in inference throughput.
Semantically Constrained Memory Allocation (SCMA) for Embedding in Efficient Recommendation Systems
Feb 24, 2021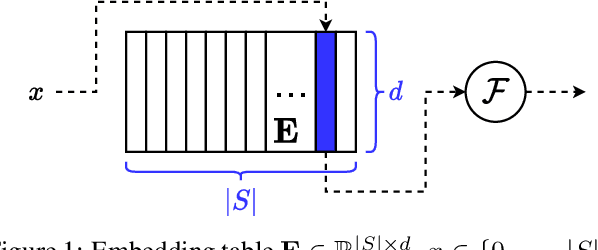
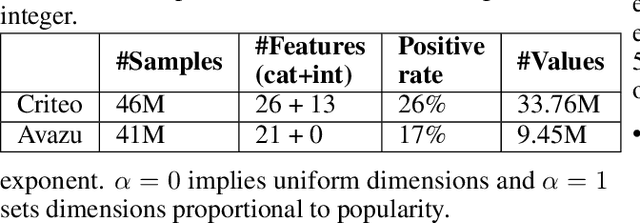
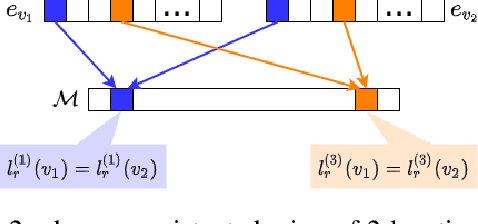
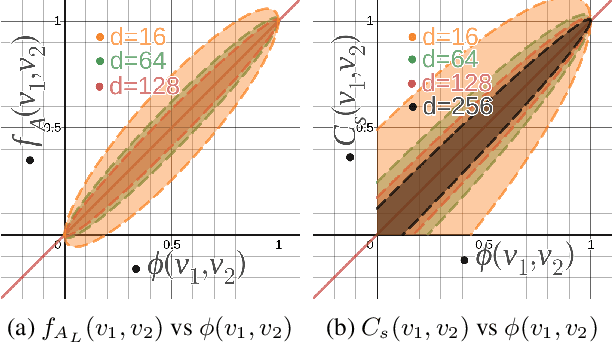
Deep learning-based models are utilized to achieve state-of-the-art performance for recommendation systems. A key challenge for these models is to work with millions of categorical classes or tokens. The standard approach is to learn end-to-end, dense latent representations or embeddings for each token. The resulting embeddings require large amounts of memory that blow up with the number of tokens. Training and inference with these models create storage, and memory bandwidth bottlenecks leading to significant computing and energy consumption when deployed in practice. To this end, we present the problem of \textit{Memory Allocation} under budget for embeddings and propose a novel formulation of memory shared embedding, where memory is shared in proportion to the overlap in semantic information. Our formulation admits a practical and efficient randomized solution with Locality sensitive hashing based Memory Allocation (LMA). We demonstrate a significant reduction in the memory footprint while maintaining performance. In particular, our LMA embeddings achieve the same performance compared to standard embeddings with a 16$\times$ reduction in memory footprint. Moreover, LMA achieves an average improvement of over 0.003 AUC across different memory regimes than standard DLRM models on Criteo and Avazu datasets
Neighbor Oblivious Learning (NObLe) for Device Localization and Tracking
Nov 23, 2020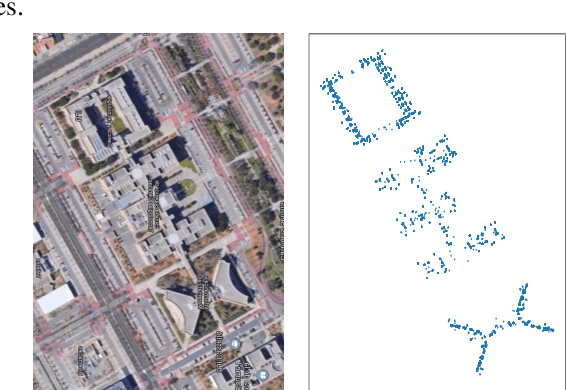
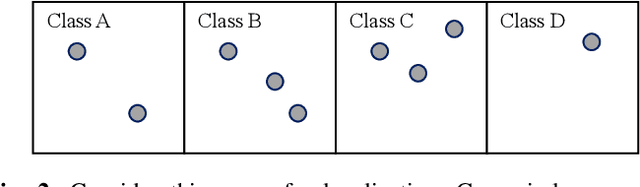
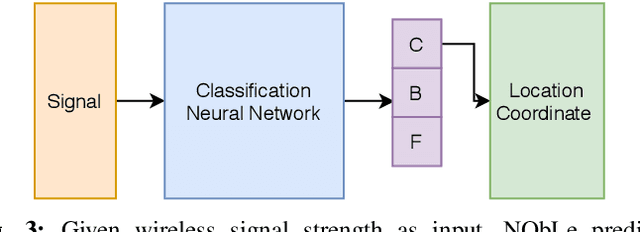
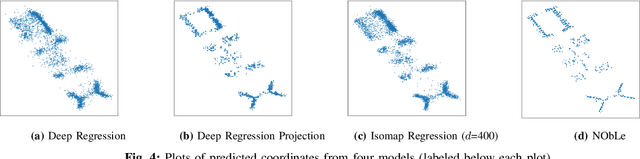
On-device localization and tracking are increasingly crucial for various applications. Along with a rapidly growing amount of location data, machine learning (ML) techniques are becoming widely adopted. A key reason is that ML inference is significantly more energy-efficient than GPS query at comparable accuracy, and GPS signals can become extremely unreliable for specific scenarios. To this end, several techniques such as deep neural networks have been proposed. However, during training, almost none of them incorporate the known structural information such as floor plan, which can be especially useful in indoor or other structured environments. In this paper, we argue that the state-of-the-art-systems are significantly worse in terms of accuracy because they are incapable of utilizing these essential structural information. The problem is incredibly hard because the structural properties are not explicitly available, making most structural learning approaches inapplicable. Given that both input and output space potentially contain rich structures, we study our method through the intuitions from manifold-projection. Whereas existing manifold based learning methods actively utilized neighborhood information, such as Euclidean distances, our approach performs Neighbor Oblivious Learning (NObLe). We demonstrate our approach's effectiveness on two orthogonal applications, including WiFi-based fingerprint localization and inertial measurement unit(IMU) based device tracking, and show that it gives significant improvement over state-of-art prediction accuracy.