 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Wisdom of Committee: Distilling from Foundation Model to Specialized Application Model
Feb 27, 2024Recent advancements in foundation models have yielded impressive performance across a wide range of tasks. Meanwhile, for specific applications, practitioners have been developing specialized application models. To enjoy the benefits of both kinds of models, one natural path is to transfer the knowledge in foundation models into specialized application models, which are generally more efficient for serving. Techniques from knowledge distillation may be applied here, where the application model learns to mimic the foundation model. However, specialized application models and foundation models have substantial gaps in capacity, employing distinct architectures, using different input features from different modalities, and being optimized on different distributions. These differences in model characteristics lead to significant challenges for distillation methods. In this work, we propose creating a teaching committee comprising both foundation model teachers and complementary teachers. Complementary teachers possess model characteristics akin to the student's, aiming to bridge the gap between the foundation model and specialized application models for a smoother knowledge transfer. Further, to accommodate the dissimilarity among the teachers in the committee, we introduce DiverseDistill, which allows the student to understand the expertise of each teacher and extract task knowledge. Our evaluations demonstrate that adding complementary teachers enhances student performance. Finally, DiverseDistill consistently outperforms baseline distillation methods, regardless of the teacher choices, resulting in significantly improved student performance.
Heterogeneous federated collaborative filtering using FAIR: Federated Averaging in Random Subspaces
Nov 03, 2023



Recommendation systems (RS) for items (e.g., movies, books) and ads are widely used to tailor content to users on various internet platforms. Traditionally, recommendation models are trained on a central server. However, due to rising concerns for data privacy and regulations like the GDPR, federated learning is an increasingly popular paradigm in which data never leaves the client device. Applying federated learning to recommendation models is non-trivial due to large embedding tables, which often exceed the memory constraints of most user devices. To include data from all devices in federated learning, we must enable collective training of embedding tables on devices with heterogeneous memory capacities. Current solutions to heterogeneous federated learning can only accommodate a small range of capacities and thus limit the number of devices that can participate in training. We present Federated Averaging in Random subspaces (FAIR), which allows arbitrary compression of embedding tables based on device capacity and ensures the participation of all devices in training. FAIR uses what we call consistent and collapsible subspaces defined by hashing-based random projections to jointly train large embedding tables while using varying amounts of compression on user devices. We evaluate FAIR on Neural Collaborative Filtering tasks with multiple datasets and verify that FAIR can gather and share information from a wide range of devices with varying capacities, allowing for seamless collaboration. We prove the convergence of FAIR in the homogeneous setting with non-i.i.d data distribution. Our code is open source at {https://github.com/apd10/FLCF}
Deja Vu: Contextual Sparsity for Efficient LLMs at Inference Time
Oct 26, 2023Large language models (LLMs) with hundreds of billions of parameters have sparked a new wave of exciting AI applications. However, they are computationally expensive at inference time. Sparsity is a natural approach to reduce this cost, but existing methods either require costly retraining, have to forgo LLM's in-context learning ability, or do not yield wall-clock time speedup on modern hardware. We hypothesize that contextual sparsity, which are small, input-dependent sets of attention heads and MLP parameters that yield approximately the same output as the dense model for a given input, can address these issues. We show that contextual sparsity exists, that it can be accurately predicted, and that we can exploit it to speed up LLM inference in wall-clock time without compromising LLM's quality or in-context learning ability. Based on these insights, we propose DejaVu, a system that uses a low-cost algorithm to predict contextual sparsity on the fly given inputs to each layer, along with an asynchronous and hardware-aware implementation that speeds up LLM inference. We validate that DejaVu can reduce the inference latency of OPT-175B by over 2X compared to the state-of-the-art FasterTransformer, and over 6X compared to the widely used Hugging Face implementation, without compromising model quality. The code is available at https://github.com/FMInference/DejaVu.
Scissorhands: Exploiting the Persistence of Importance Hypothesis for LLM KV Cache Compression at Test Time
May 26, 2023



Large language models(LLMs) have sparked a new wave of exciting AI applications. Hosting these models at scale requires significant memory resources. One crucial memory bottleneck for the deployment stems from the context window. It is commonly recognized that model weights are memory hungry; however, the size of key-value embedding stored during the generation process (KV cache) can easily surpass the model size. The enormous size of the KV cache puts constraints on the inference batch size, which is crucial for high throughput inference workload. Inspired by an interesting observation of the attention scores, we hypothesize the persistence of importance: only pivotal tokens, which had a substantial influence at one step, will significantly influence future generations. Based on our empirical verification and theoretical analysis around this hypothesis, we propose Scissorhands, a system that maintains the memory usage of the KV cache at a fixed budget without finetuning the model. In essence, Scissorhands manages the KV cache by storing the pivotal tokens with a higher probability. We validate that Scissorhands reduces the inference memory usage of the KV cache by up to 5X without compromising model quality. We further demonstrate that Scissorhands can be combined with 4-bit quantization, traditionally used to compress model weights, to achieve up to 20X compression.
Learning Multimodal Data Augmentation in Feature Space
Dec 29, 2022



The ability to jointly learn from multiple modalities, such as text, audio, and visual data, is a defining feature of intelligent systems. While there have been promising advances in designing neural networks to harness multimodal data, the enormous success of data augmentation currently remains limited to single-modality tasks like image classification. Indeed, it is particularly difficult to augment each modality while preserving the overall semantic structure of the data; for example, a caption may no longer be a good description of an image after standard augmentations have been applied, such as translation. Moreover, it is challenging to specify reasonable transformations that are not tailored to a particular modality. In this paper, we introduce LeMDA, Learning Multimodal Data Augmentation, an easy-to-use method that automatically learns to jointly augment multimodal data in feature space, with no constraints on the identities of the modalities or the relationship between modalities. We show that LeMDA can (1) profoundly improve the performance of multimodal deep learning architectures, (2) apply to combinations of modalities that have not been previously considered, and (3) achieve state-of-the-art results on a wide range of applications comprised of image, text, and tabular data.
DONet: Learning Category-Level 6D Object Pose and Size Estimation from Depth Observation
Jun 27, 2021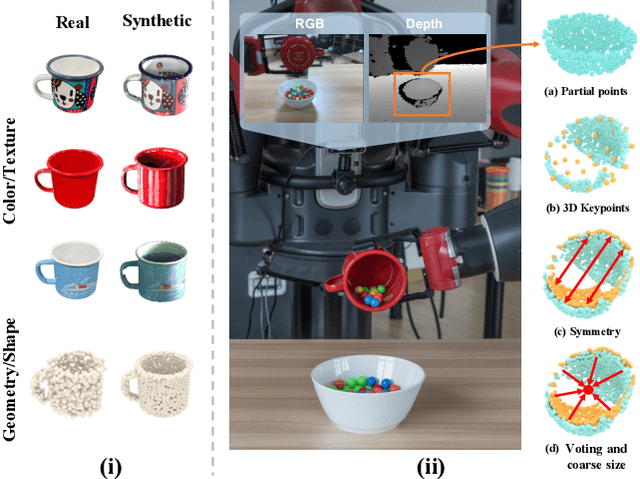
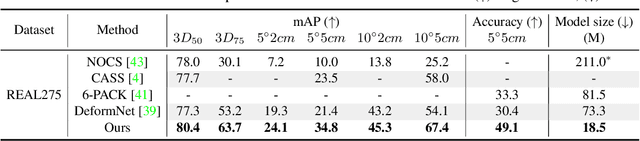
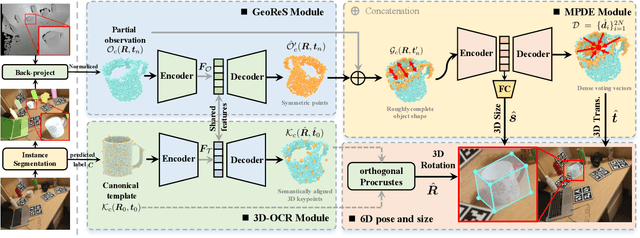
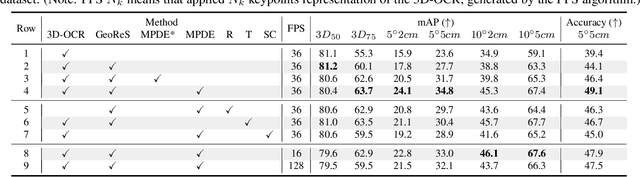
We propose a method of Category-level 6D Object Pose and Size Estimation (COPSE) from a single depth image, without external pose-annotated real-world training data. While previous works exploit visual cues in RGB(D) images, our method makes inferences based on the rich geometric information of the object in the depth channel alone. Essentially, our framework explores such geometric information by learning the unified 3D Orientation-Consistent Representations (3D-OCR) module, and further enforced by the property of Geometry-constrained Reflection Symmetry (GeoReS) module. The magnitude information of object size and the center point is finally estimated by Mirror-Paired Dimensional Estimation (MPDE) module. Extensive experiments on the category-level NOCS benchmark demonstrate that our framework competes with state-of-the-art approaches that require labeled real-world images. We also deploy our approach to a physical Baxter robot to perform manipulation tasks on unseen but category-known instances, and the results further validate the efficacy of our proposed model. Our videos are available in the supplementary material.
Efficient Inference via Universal LSH Kernel
Jun 21, 2021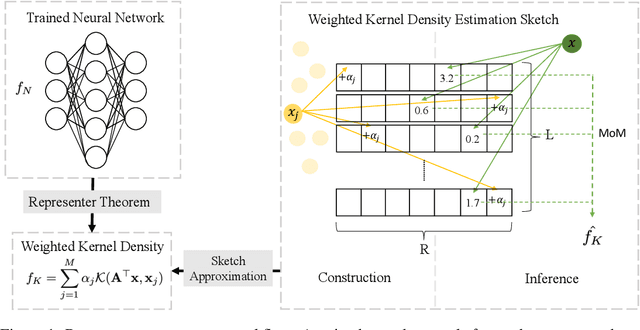
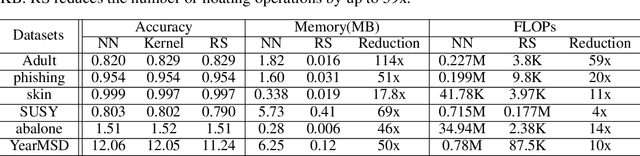
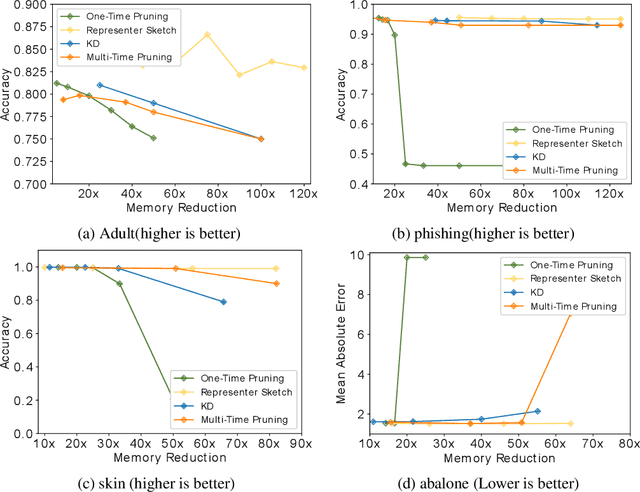
Large machine learning models achieve unprecedented performance on various tasks and have evolved as the go-to technique. However, deploying these compute and memory hungry models on resource constraint environments poses new challenges. In this work, we propose mathematically provable Representer Sketch, a concise set of count arrays that can approximate the inference procedure with simple hashing computations and aggregations. Representer Sketch builds upon the popular Representer Theorem from kernel literature, hence the name, providing a generic fundamental alternative to the problem of efficient inference that goes beyond the popular approach such as quantization, iterative pruning and knowledge distillation. A neural network function is transformed to its weighted kernel density representation, which can be very efficiently estimated with our sketching algorithm. Empirically, we show that Representer Sketch achieves up to 114x reduction in storage requirement and 59x reduction in computation complexity without any drop in accuracy.
Neighbor Oblivious Learning (NObLe) for Device Localization and Tracking
Nov 23, 2020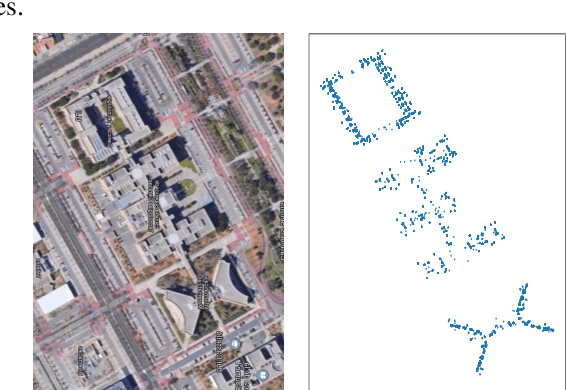
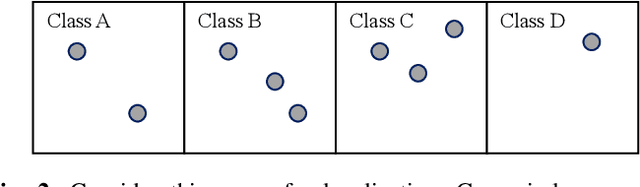
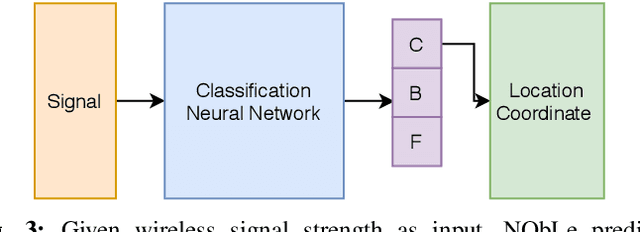
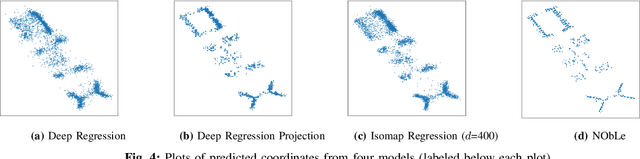
On-device localization and tracking are increasingly crucial for various applications. Along with a rapidly growing amount of location data, machine learning (ML) techniques are becoming widely adopted. A key reason is that ML inference is significantly more energy-efficient than GPS query at comparable accuracy, and GPS signals can become extremely unreliable for specific scenarios. To this end, several techniques such as deep neural networks have been proposed. However, during training, almost none of them incorporate the known structural information such as floor plan, which can be especially useful in indoor or other structured environments. In this paper, we argue that the state-of-the-art-systems are significantly worse in terms of accuracy because they are incapable of utilizing these essential structural information. The problem is incredibly hard because the structural properties are not explicitly available, making most structural learning approaches inapplicable. Given that both input and output space potentially contain rich structures, we study our method through the intuitions from manifold-projection. Whereas existing manifold based learning methods actively utilized neighborhood information, such as Euclidean distances, our approach performs Neighbor Oblivious Learning (NObLe). We demonstrate our approach's effectiveness on two orthogonal applications, including WiFi-based fingerprint localization and inertial measurement unit(IMU) based device tracking, and show that it gives significant improvement over state-of-art prediction accuracy.