 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClimbing the WOL: Training for Cheaper Inference
Paper and Code
Jul 03, 2020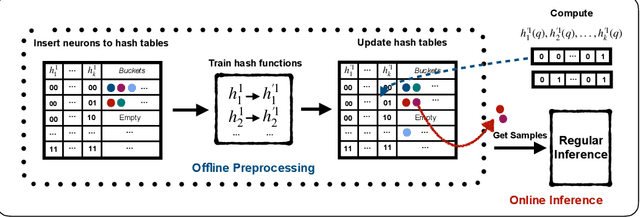
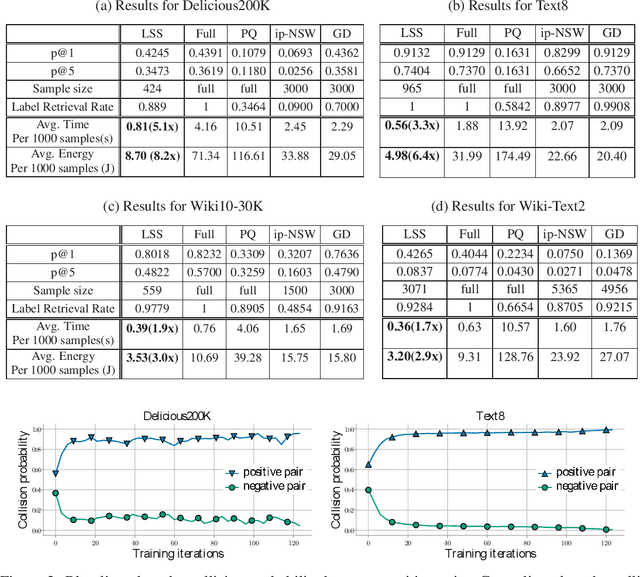

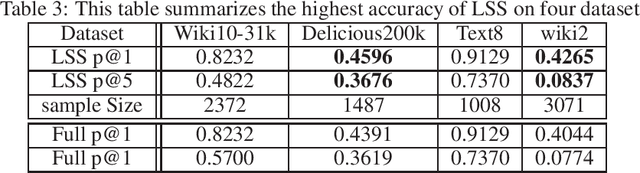
Efficient inference for wide output layers (WOLs) is an essential yet challenging task in large scale machine learning. Most approaches reduce this problem to approximate maximum inner product search (MIPS), which relies heavily on the observation that for a given model, ground truth labels correspond to logits of highest value during full model inference. However, such an assumption is restrictive in practice. In this paper, we argue that approximate MIPS subroutines, despite having sub-linear computation time, are sub-optimal because they are tailored for retrieving large inner products with high recall instead of retrieving the correct labels. With WOL, the labels often have moderate inner products, which makes approximate MIPS more challenging. We propose an alternative problem formulation, called Label Superior Sampling (LSS), where the objective is to tailor the system to ensure retrieval of the correct label. Accordingly, we propose a novel learned hash approach, which is significantly more efficient and sufficient for high inference accuracy than MIPS baselines. Our extensive evaluation indicates that LSS can match or even outperform full inference accuracy with around 5x speed up and 87% energy reduction.