 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Inference via Universal LSH Kernel
Paper and Code
Jun 21, 2021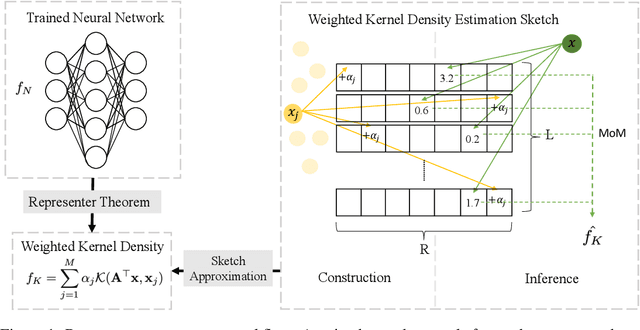
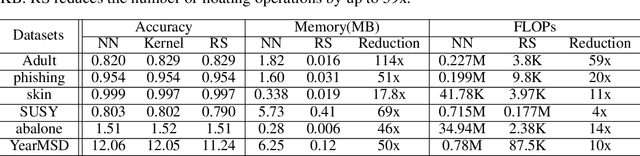
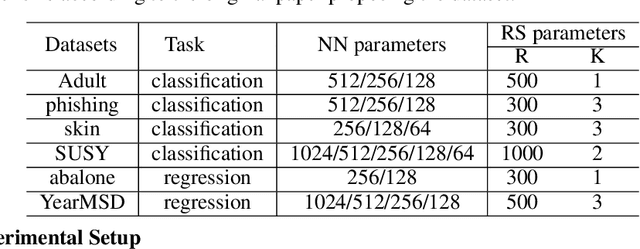
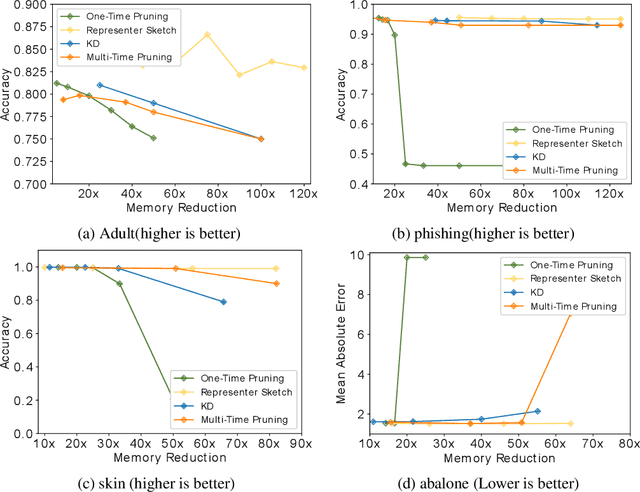
Large machine learning models achieve unprecedented performance on various tasks and have evolved as the go-to technique. However, deploying these compute and memory hungry models on resource constraint environments poses new challenges. In this work, we propose mathematically provable Representer Sketch, a concise set of count arrays that can approximate the inference procedure with simple hashing computations and aggregations. Representer Sketch builds upon the popular Representer Theorem from kernel literature, hence the name, providing a generic fundamental alternative to the problem of efficient inference that goes beyond the popular approach such as quantization, iterative pruning and knowledge distillation. A neural network function is transformed to its weighted kernel density representation, which can be very efficiently estimated with our sketching algorithm. Empirically, we show that Representer Sketch achieves up to 114x reduction in storage requirement and 59x reduction in computation complexity without any drop in accuracy.