 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
Conditional Automated Channel Pruning for Deep Neural Networks
Sep 27, 2020
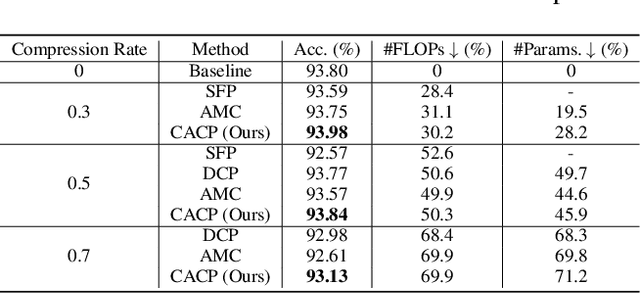
Model compression aims to reduce the redundancy of deep networks to obtain compact models. Recently, channel pruning has become one of the predominant compression methods to deploy deep models on resource-constrained devices. Most channel pruning methods often use a fixed compression rate for all the layers of the model, which, however, may not be optimal. To address this issue, given a target compression rate for the whole model, one can search for the optimal compression rate for each layer. Nevertheless, these methods perform channel pruning for a specific target compression rate. When we consider multiple compression rates, they have to repeat the channel pruning process multiple times, which is very inefficient yet unnecessary. To address this issue, we propose a Conditional Automated Channel Pruning(CACP) method to obtain the compressed models with different compression rates through single channel pruning process. To this end, we develop a conditional model that takes an arbitrary compression rate as input and outputs the corresponding compressed model. In the experiments, the resultant models with different compression rates consistently outperform the models compressed by existing methods with a channel pruning process for each target compression rate.