 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-Level LLM Collaboration via FusionRoute
Jan 08, 2026Large language models (LLMs) exhibit strengths across diverse domains. However, achieving strong performance across these domains with a single general-purpose model typically requires scaling to sizes that are prohibitively expensive to train and deploy. On the other hand, while smaller domain-specialized models are much more efficient, they struggle to generalize beyond their training distributions. To address this dilemma, we propose FusionRoute, a robust and effective token-level multi-LLM collaboration framework in which a lightweight router simultaneously (i) selects the most suitable expert at each decoding step and (ii) contributes a complementary logit that refines or corrects the selected expert's next-token distribution via logit addition. Unlike existing token-level collaboration methods that rely solely on fixed expert outputs, we provide a theoretical analysis showing that pure expert-only routing is fundamentally limited: unless strong global coverage assumptions hold, it cannot in general realize the optimal decoding policy. By augmenting expert selection with a trainable complementary generator, FusionRoute expands the effective policy class and enables recovery of optimal value functions under mild conditions. Empirically, across both Llama-3 and Gemma-2 families and diverse benchmarks spanning mathematical reasoning, code generation, and instruction following, FusionRoute outperforms both sequence- and token-level collaboration, model merging, and direct fine-tuning, while remaining competitive with domain experts on their respective tasks.
LLMs for User Interest Exploration: A Hybrid Approach
May 25, 2024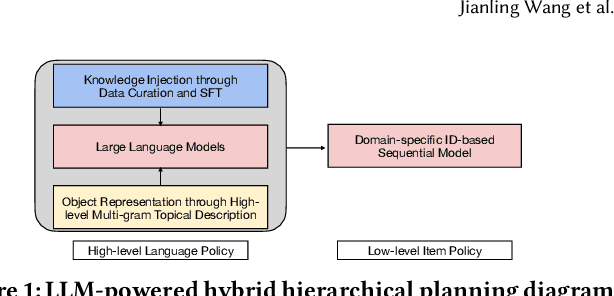

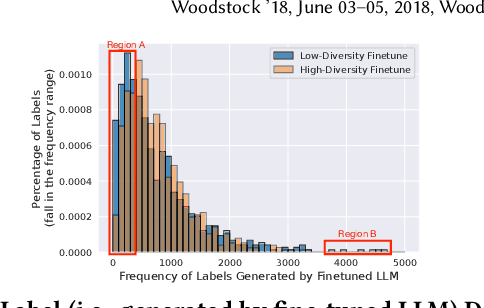
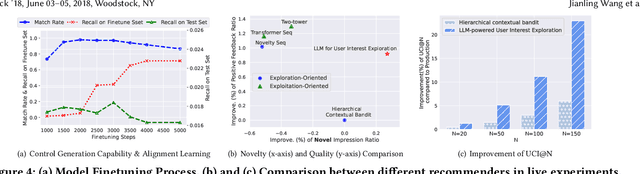
Traditional recommendation systems are subject to a strong feedback loop by learning from and reinforcing past user-item interactions, which in turn limits the discovery of novel user interests. To address this, we introduce a hybrid hierarchical framework combining Large Language Models (LLMs) and classic recommendation models for user interest exploration. The framework controls the interfacing between the LLMs and the classic recommendation models through "interest clusters", the granularity of which can be explicitly determined by algorithm designers. It recommends the next novel interests by first representing "interest clusters" using language, and employs a fine-tuned LLM to generate novel interest descriptions that are strictly within these predefined clusters. At the low level, it grounds these generated interests to an item-level policy by restricting classic recommendation models, in this case a transformer-based sequence recommender to return items that fall within the novel clusters generated at the high level. We showcase the efficacy of this approach on an industrial-scale commercial platform serving billions of users. Live experiments show a significant increase in both exploration of novel interests and overall user enjoyment of the platform.
Wisdom of Committee: Distilling from Foundation Model to Specialized Application Model
Feb 27, 2024Recent advancements in foundation models have yielded impressive performance across a wide range of tasks. Meanwhile, for specific applications, practitioners have been developing specialized application models. To enjoy the benefits of both kinds of models, one natural path is to transfer the knowledge in foundation models into specialized application models, which are generally more efficient for serving. Techniques from knowledge distillation may be applied here, where the application model learns to mimic the foundation model. However, specialized application models and foundation models have substantial gaps in capacity, employing distinct architectures, using different input features from different modalities, and being optimized on different distributions. These differences in model characteristics lead to significant challenges for distillation methods. In this work, we propose creating a teaching committee comprising both foundation model teachers and complementary teachers. Complementary teachers possess model characteristics akin to the student's, aiming to bridge the gap between the foundation model and specialized application models for a smoother knowledge transfer. Further, to accommodate the dissimilarity among the teachers in the committee, we introduce DiverseDistill, which allows the student to understand the expertise of each teacher and extract task knowledge. Our evaluations demonstrate that adding complementary teachers enhances student performance. Finally, DiverseDistill consistently outperforms baseline distillation methods, regardless of the teacher choices, resulting in significantly improved student performance.
LEVI: Generalizable Fine-tuning via Layer-wise Ensemble of Different Views
Feb 07, 2024



Fine-tuning is becoming widely used for leveraging the power of pre-trained foundation models in new downstream tasks. While there are many successes of fine-tuning on various tasks, recent studies have observed challenges in the generalization of fine-tuned models to unseen distributions (i.e., out-of-distribution; OOD). To improve OOD generalization, some previous studies identify the limitations of fine-tuning data and regulate fine-tuning to preserve the general representation learned from pre-training data. However, potential limitations in the pre-training data and models are often ignored. In this paper, we contend that overly relying on the pre-trained representation may hinder fine-tuning from learning essential representations for downstream tasks and thus hurt its OOD generalization. It can be especially catastrophic when new tasks are from different (sub)domains compared to pre-training data. To address the issues in both pre-training and fine-tuning data, we propose a novel generalizable fine-tuning method LEVI, where the pre-trained model is adaptively ensembled layer-wise with a small task-specific model, while preserving training and inference efficiencies. By combining two complementing models, LEVI effectively suppresses problematic features in both the fine-tuning data and pre-trained model and preserves useful features for new tasks. Broad experiments with large language and vision models show that LEVI greatly improves fine-tuning generalization via emphasizing different views from fine-tuning data and pre-trained features.
Learning from Negative User Feedback and Measuring Responsiveness for Sequential Recommenders
Aug 23, 2023


Sequential recommenders have been widely used in industry due to their strength in modeling user preferences. While these models excel at learning a user's positive interests, less attention has been paid to learning from negative user feedback. Negative user feedback is an important lever of user control, and comes with an expectation that recommenders should respond quickly and reduce similar recommendations to the user. However, negative feedback signals are often ignored in the training objective of sequential retrieval models, which primarily aim at predicting positive user interactions. In this work, we incorporate explicit and implicit negative user feedback into the training objective of sequential recommenders in the retrieval stage using a "not-to-recommend" loss function that optimizes for the log-likelihood of not recommending items with negative feedback. We demonstrate the effectiveness of this approach using live experiments on a large-scale industrial recommender system. Furthermore, we address a challenge in measuring recommender responsiveness to negative feedback by developing a counterfactual simulation framework to compare recommender responses between different user actions, showing improved responsiveness from the modeling change.
Value of Exploration: Measurements, Findings and Algorithms
May 12, 2023



Effective exploration is believed to positively influence the long-term user experience on recommendation platforms. Determining its exact benefits, however, has been challenging. Regular A/B tests on exploration often measure neutral or even negative engagement metrics while failing to capture its long-term benefits. To address this, we present a systematic study to formally quantify the value of exploration by examining its effects on the content corpus, a key entity in the recommender system that directly affects user experiences. Specifically, we introduce new metrics and the associated experiment design to measure the benefit of exploration on the corpus change, and further connect the corpus change to the long-term user experience. Furthermore, we investigate the possibility of introducing the Neural Linear Bandit algorithm to build an exploration-based ranking system, and use it as the backbone algorithm for our case study. We conduct extensive live experiments on a large-scale commercial recommendation platform that serves billions of users to validate the new experiment designs, quantify the long-term values of exploration, and to verify the effectiveness of the adopted neural linear bandit algorithm for exploration.