 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Think-on-Graph: Wider, Deeper and Faster Reasoning of Large Language Model on Knowledge Graph
Jan 24, 2025
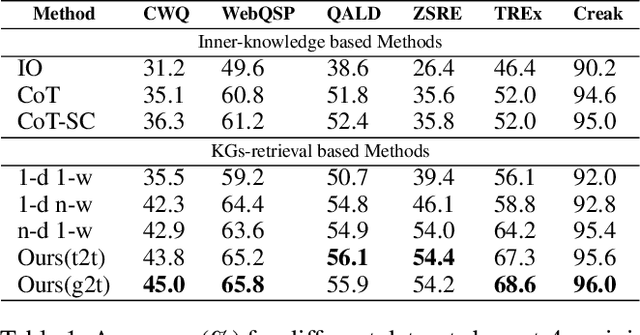

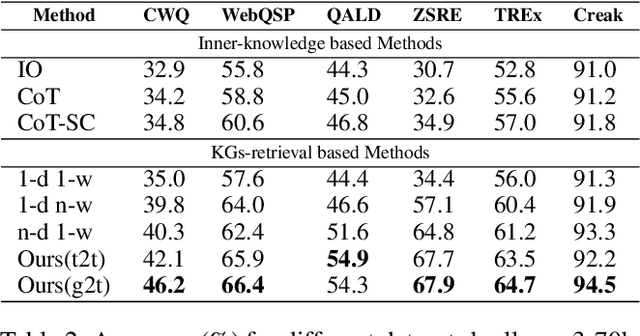
Graph Retrieval Augmented Generation (GRAG) is a novel paradigm that takes the naive RAG system a step further by integrating graph information, such as knowledge graph (KGs), into large-scale language models (LLMs) to mitigate hallucination. However, existing GRAG still encounter limitations: 1) simple paradigms usually fail with the complex problems due to the narrow and shallow correlations capture from KGs 2) methods of strong coupling with KGs tend to be high computation cost and time consuming if the graph is dense. In this paper, we propose the Fast Think-on-Graph (FastToG), an innovative paradigm for enabling LLMs to think ``community by community" within KGs. To do this, FastToG employs community detection for deeper correlation capture and two stages community pruning - coarse and fine pruning for faster retrieval. Furthermore, we also develop two Community-to-Text methods to convert the graph structure of communities into textual form for better understanding by LLMs. Experimental results demonstrate the effectiveness of FastToG, showcasing higher accuracy, faster reasoning, and better explainability compared to the previous works.
Minimizing Live Experiments in Recommender Systems: User Simulation to Evaluate Preference Elicitation Policies
Sep 26, 2024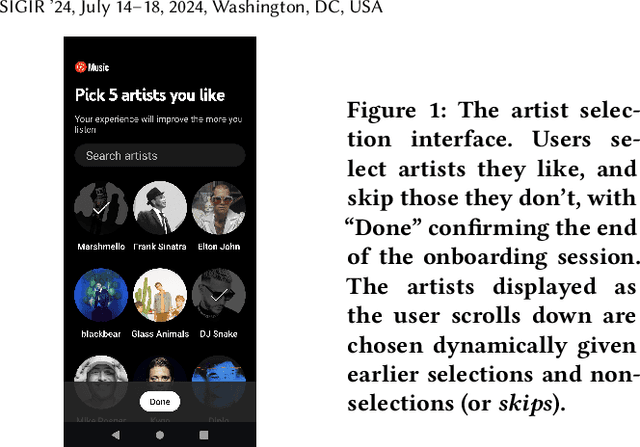
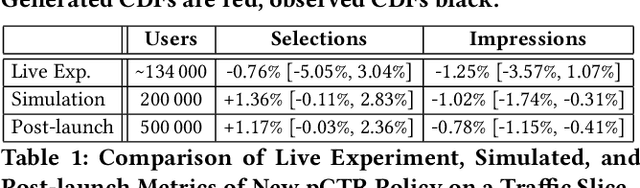
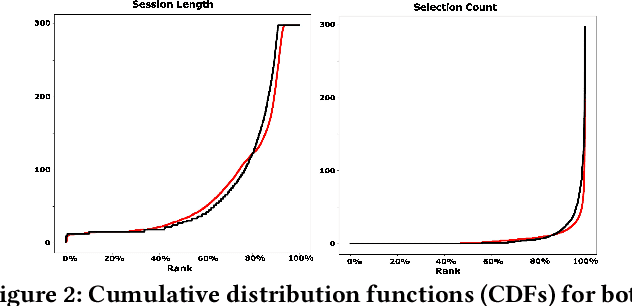
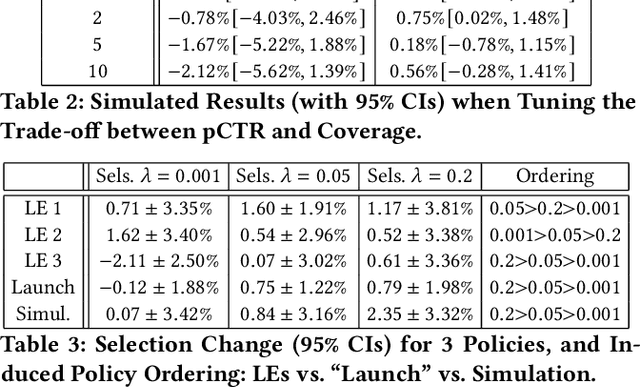
Evaluation of policies in recommender systems typically involves A/B testing using live experiments on real users to assess a new policy's impact on relevant metrics. This ``gold standard'' comes at a high cost, however, in terms of cycle time, user cost, and potential user retention. In developing policies for ``onboarding'' new users, these costs can be especially problematic, since on-boarding occurs only once. In this work, we describe a simulation methodology used to augment (and reduce) the use of live experiments. We illustrate its deployment for the evaluation of ``preference elicitation'' algorithms used to onboard new users of the YouTube Music platform. By developing counterfactually robust user behavior models, and a simulation service that couples such models with production infrastructure, we are able to test new algorithms in a way that reliably predicts their performance on key metrics when deployed live. We describe our domain, our simulation models and platform, results of experiments and deployment, and suggest future steps needed to further realistic simulation as a powerful complement to live experiments.
Learning from Negative User Feedback and Measuring Responsiveness for Sequential Recommenders
Aug 23, 2023


Sequential recommenders have been widely used in industry due to their strength in modeling user preferences. While these models excel at learning a user's positive interests, less attention has been paid to learning from negative user feedback. Negative user feedback is an important lever of user control, and comes with an expectation that recommenders should respond quickly and reduce similar recommendations to the user. However, negative feedback signals are often ignored in the training objective of sequential retrieval models, which primarily aim at predicting positive user interactions. In this work, we incorporate explicit and implicit negative user feedback into the training objective of sequential recommenders in the retrieval stage using a "not-to-recommend" loss function that optimizes for the log-likelihood of not recommending items with negative feedback. We demonstrate the effectiveness of this approach using live experiments on a large-scale industrial recommender system. Furthermore, we address a challenge in measuring recommender responsiveness to negative feedback by developing a counterfactual simulation framework to compare recommender responses between different user actions, showing improved responsiveness from the modeling change.