 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Multimodal Models for Ukrainian Language Understanding Across Academic and Cultural Domains
Nov 22, 2024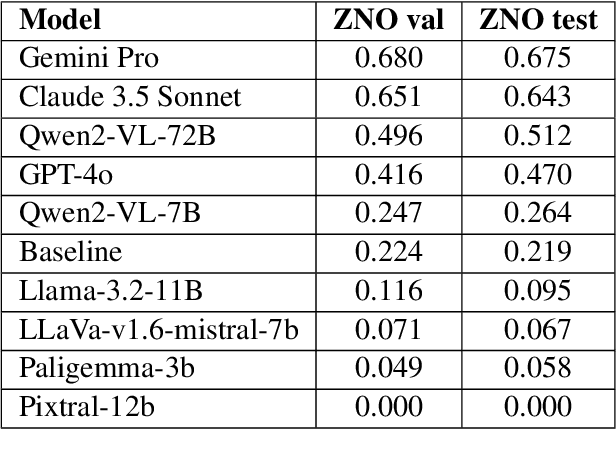
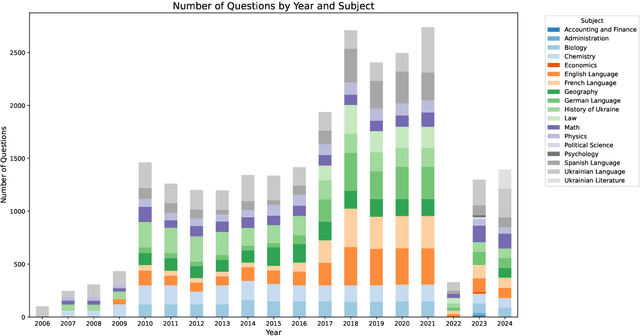
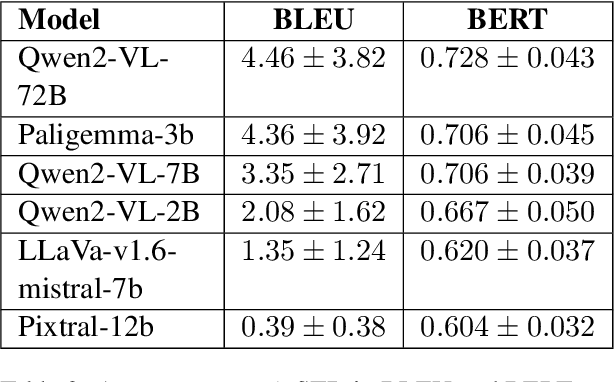
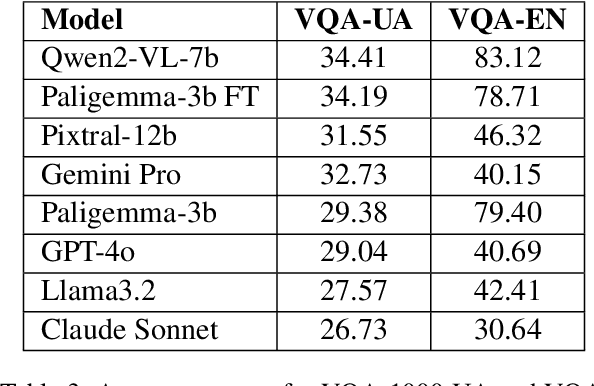
While the evaluation of multimodal English-centric models is an active area of research with numerous benchmarks, there is a profound lack of benchmarks or evaluation suites for low- and mid-resource languages. We introduce ZNO-Vision, a comprehensive multimodal Ukrainian-centric benchmark derived from standardized university entrance examination (ZNO). The benchmark consists of over 4,300 expert-crafted questions spanning 12 academic disciplines, including mathematics, physics, chemistry, and humanities. We evaluated the performance of both open-source models and API providers, finding that only a handful of models performed above baseline. Alongside the new benchmark, we performed the first evaluation study of multimodal text generation for the Ukrainian language: we measured caption generation quality on the Multi30K-UK dataset, translated the VQA benchmark into Ukrainian, and measured performance degradation relative to original English versions. Lastly, we tested a few models from a cultural perspective on knowledge of national cuisine. We believe our work will advance multimodal generation capabilities for the Ukrainian language and our approach could be useful for other low-resource languages.
From English-Centric to Effective Bilingual: LLMs with Custom Tokenizers for Underrepresented Languages
Oct 24, 2024


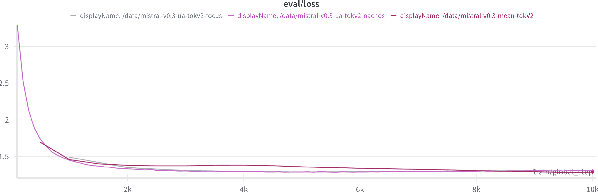
In this paper, we propose a model-agnostic cost-effective approach to developing bilingual base large language models (LLMs) to support English and any target language. The method includes vocabulary expansion, initialization of new embeddings, model training and evaluation. We performed our experiments with three languages, each using a non-Latin script - Ukrainian, Arabic, and Georgian. Our approach demonstrates improved language performance while reducing computational costs. It mitigates the disproportionate penalization of underrepresented languages, promoting fairness and minimizing adverse phenomena such as code-switching and broken grammar. Additionally, we introduce new metrics to evaluate language quality, revealing that vocabulary size significantly impacts the quality of generated text.
Minimizing Live Experiments in Recommender Systems: User Simulation to Evaluate Preference Elicitation Policies
Sep 26, 2024
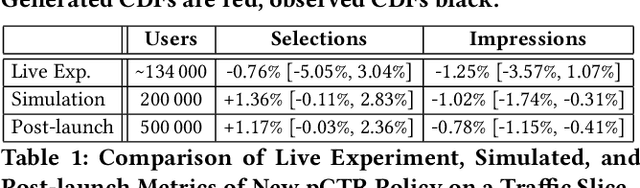
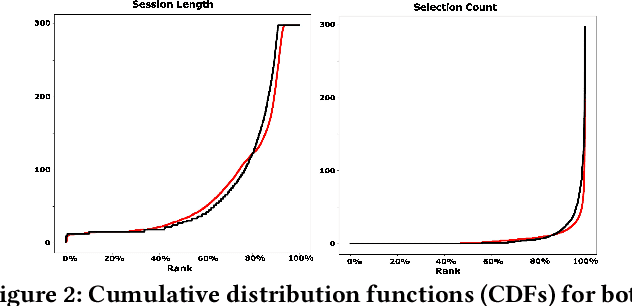
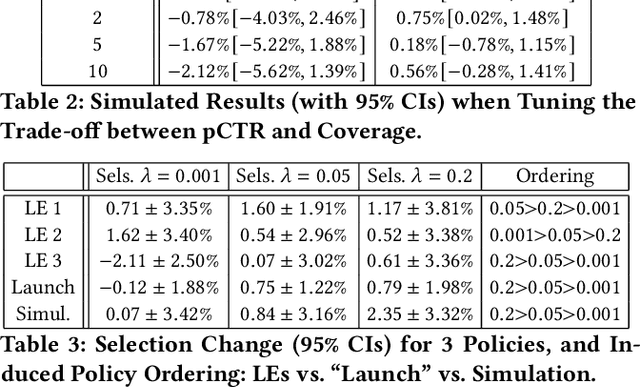
Evaluation of policies in recommender systems typically involves A/B testing using live experiments on real users to assess a new policy's impact on relevant metrics. This ``gold standard'' comes at a high cost, however, in terms of cycle time, user cost, and potential user retention. In developing policies for ``onboarding'' new users, these costs can be especially problematic, since on-boarding occurs only once. In this work, we describe a simulation methodology used to augment (and reduce) the use of live experiments. We illustrate its deployment for the evaluation of ``preference elicitation'' algorithms used to onboard new users of the YouTube Music platform. By developing counterfactually robust user behavior models, and a simulation service that couples such models with production infrastructure, we are able to test new algorithms in a way that reliably predicts their performance on key metrics when deployed live. We describe our domain, our simulation models and platform, results of experiments and deployment, and suggest future steps needed to further realistic simulation as a powerful complement to live experiments.
From Bytes to Borsch: Fine-Tuning Gemma and Mistral for the Ukrainian Language Representation
Apr 14, 2024In the rapidly advancing field of AI and NLP, generative large language models (LLMs) stand at the forefront of innovation, showcasing unparalleled abilities in text understanding and generation. However, the limited representation of low-resource languages like Ukrainian poses a notable challenge, restricting the reach and relevance of this technology. Our paper addresses this by fine-tuning the open-source Gemma and Mistral LLMs with Ukrainian datasets, aiming to improve their linguistic proficiency and benchmarking them against other existing models capable of processing Ukrainian language. This endeavor not only aims to mitigate language bias in technology but also promotes inclusivity in the digital realm. Our transparent and reproducible approach encourages further NLP research and development. Additionally, we present the Ukrainian Knowledge and Instruction Dataset (UKID) to aid future efforts in language model fine-tuning. Our research not only advances the field of NLP but also highlights the importance of linguistic diversity in AI, which is crucial for cultural preservation, education, and expanding AI's global utility. Ultimately, we advocate for a future where technology is inclusive, enabling AI to communicate effectively across all languages, especially those currently underrepresented.