 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Multimodal Models for Ukrainian Language Understanding Across Academic and Cultural Domains
Nov 22, 2024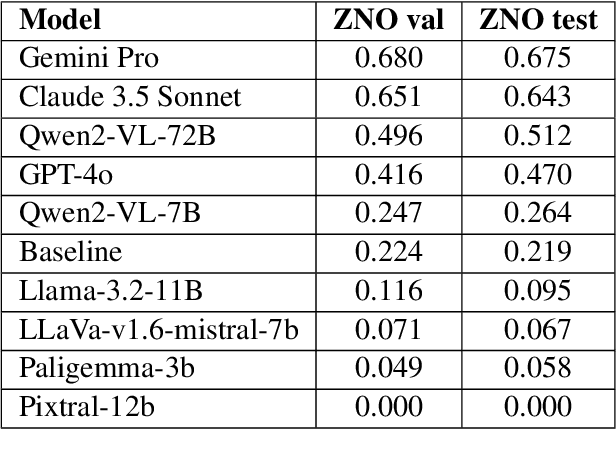
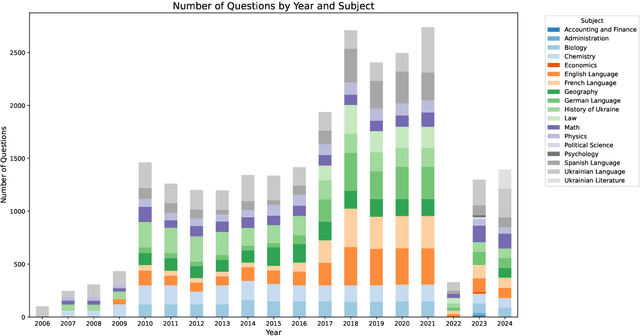
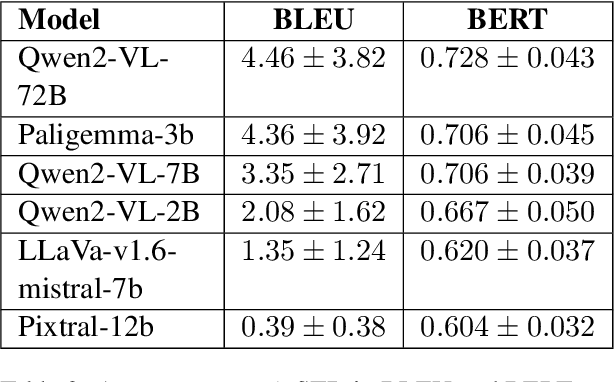
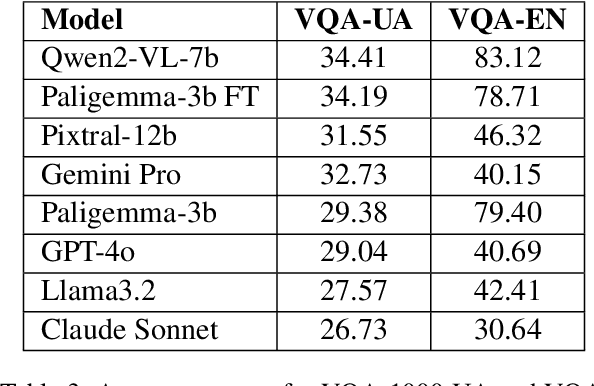
While the evaluation of multimodal English-centric models is an active area of research with numerous benchmarks, there is a profound lack of benchmarks or evaluation suites for low- and mid-resource languages. We introduce ZNO-Vision, a comprehensive multimodal Ukrainian-centric benchmark derived from standardized university entrance examination (ZNO). The benchmark consists of over 4,300 expert-crafted questions spanning 12 academic disciplines, including mathematics, physics, chemistry, and humanities. We evaluated the performance of both open-source models and API providers, finding that only a handful of models performed above baseline. Alongside the new benchmark, we performed the first evaluation study of multimodal text generation for the Ukrainian language: we measured caption generation quality on the Multi30K-UK dataset, translated the VQA benchmark into Ukrainian, and measured performance degradation relative to original English versions. Lastly, we tested a few models from a cultural perspective on knowledge of national cuisine. We believe our work will advance multimodal generation capabilities for the Ukrainian language and our approach could be useful for other low-resource languages.
Unsupervised Data Validation Methods for Efficient Model Training
Oct 10, 2024This paper investigates the challenges and potential solutions for improving machine learning systems for low-resource languages. State-of-the-art models in natural language processing (NLP), text-to-speech (TTS), speech-to-text (STT), and vision-language models (VLM) rely heavily on large datasets, which are often unavailable for low-resource languages. This research explores key areas such as defining "quality data," developing methods for generating appropriate data and enhancing accessibility to model training. A comprehensive review of current methodologies, including data augmentation, multilingual transfer learning, synthetic data generation, and data selection techniques, highlights both advancements and limitations. Several open research questions are identified, providing a framework for future studies aimed at optimizing data utilization, reducing the required data quantity, and maintaining high-quality model performance. By addressing these challenges, the paper aims to make advanced machine learning models more accessible for low-resource languages, enhancing their utility and impact across various sectors.
Setting up the Data Printer with Improved English to Ukrainian Machine Translation
Apr 23, 2024To build large language models for Ukrainian we need to expand our corpora with large amounts of new algorithmic tasks expressed in natural language. Examples of task performance expressed in English are abundant, so with a high-quality translation system our community will be enabled to curate datasets faster. To aid this goal, we introduce a recipe to build a translation system using supervised finetuning of a large pretrained language model with a noisy parallel dataset of 3M pairs of Ukrainian and English sentences followed by a second phase of training using 17K examples selected by k-fold perplexity filtering on another dataset of higher quality. Our decoder-only model named Dragoman beats performance of previous state of the art encoder-decoder models on the FLORES devtest set.