 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom RAG to Agentic RAG for Faithful Islamic Question Answering
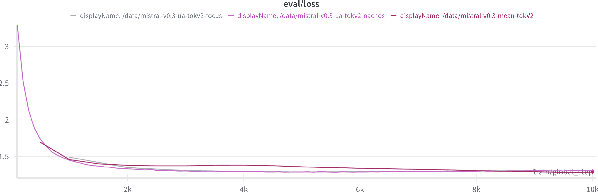
Jan 12, 2026LLMs are increasingly used for Islamic question answering, where ungrounded responses may carry serious religious consequences. Yet standard MCQ/MRC-style evaluations do not capture key real-world failure modes, notably free-form hallucinations and whether models appropriately abstain when evidence is lacking. To shed a light on this aspect we introduce ISLAMICFAITHQA, a 3,810-item bilingual (Arabic/English) generative benchmark with atomic single-gold answers, which enables direct measurement of hallucination and abstention. We additionally developed an end-to-end grounded Islamic modelling suite consisting of (i) 25K Arabic text-grounded SFT reasoning pairs, (ii) 5K bilingual preference samples for reward-guided alignment, and (iii) a verse-level Qur'an retrieval corpus of $\sim$6k atomic verses (ayat). Building on these resources, we develop an agentic Quran-grounding framework (agentic RAG) that uses structured tool calls for iterative evidence seeking and answer revision. Experiments across Arabic-centric and multilingual LLMs show that retrieval improves correctness and that agentic RAG yields the largest gains beyond standard RAG, achieving state-of-the-art performance and stronger Arabic-English robustness even with a small model (i.e., Qwen3 4B). We will make the experimental resources and datasets publicly available for the community.
From English-Centric to Effective Bilingual: LLMs with Custom Tokenizers for Underrepresented Languages
Oct 24, 2024


In this paper, we propose a model-agnostic cost-effective approach to developing bilingual base large language models (LLMs) to support English and any target language. The method includes vocabulary expansion, initialization of new embeddings, model training and evaluation. We performed our experiments with three languages, each using a non-Latin script - Ukrainian, Arabic, and Georgian. Our approach demonstrates improved language performance while reducing computational costs. It mitigates the disproportionate penalization of underrepresented languages, promoting fairness and minimizing adverse phenomena such as code-switching and broken grammar. Additionally, we introduce new metrics to evaluate language quality, revealing that vocabulary size significantly impacts the quality of generated text.
Nabra: Syrian Arabic Dialects with Morphological Annotations
Oct 26, 2023
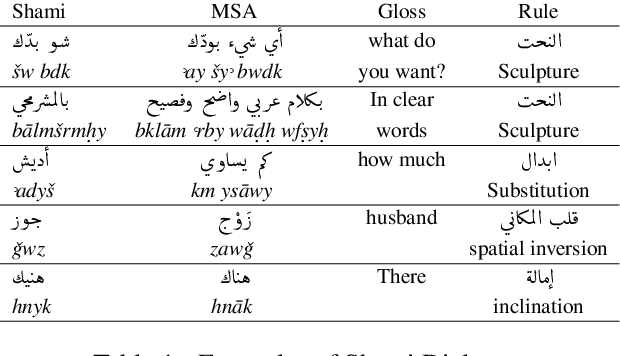

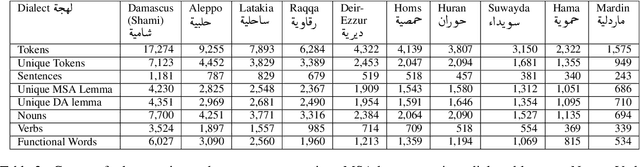
This paper presents Nabra, a corpora of Syrian Arabic dialects with morphological annotations. A team of Syrian natives collected more than 6K sentences containing about 60K words from several sources including social media posts, scripts of movies and series, lyrics of songs and local proverbs to build Nabra. Nabra covers several local Syrian dialects including those of Aleppo, Damascus, Deir-ezzur, Hama, Homs, Huran, Latakia, Mardin, Raqqah, and Suwayda. A team of nine annotators annotated the 60K tokens with full morphological annotations across sentence contexts. We trained the annotators to follow methodological annotation guidelines to ensure unique morpheme annotations, and normalized the annotations. F1 and kappa agreement scores ranged between 74% and 98% across features, showing the excellent quality of Nabra annotations. Our corpora are open-source and publicly available as part of the Currasat portal https://sina.birzeit.edu/currasat.
Curras + Baladi: Towards a Levantine Corpus
May 19, 2022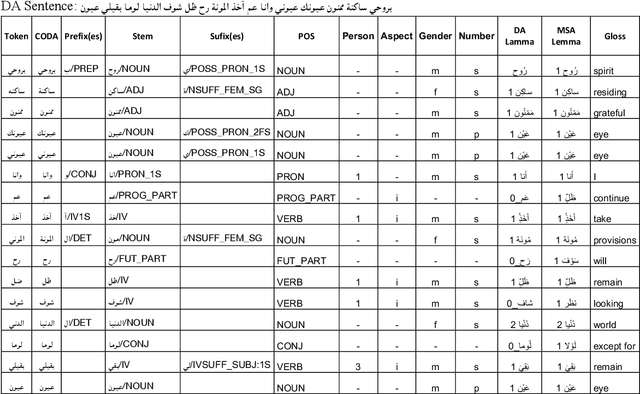
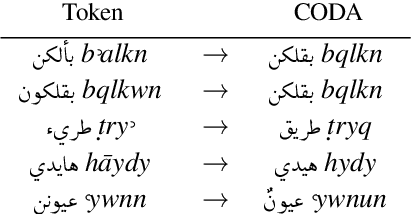
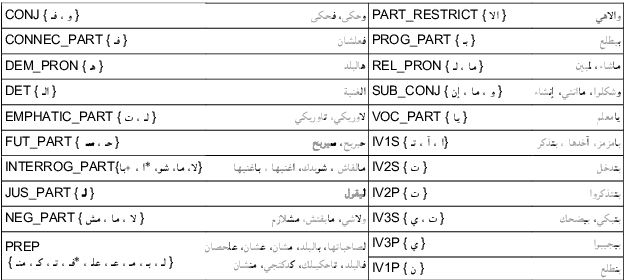
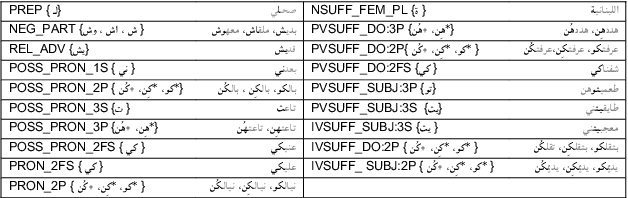
The processing of the Arabic language is a complex field of research. This is due to many factors, including the complex and rich morphology of Arabic, its high degree of ambiguity, and the presence of several regional varieties that need to be processed while taking into account their unique characteristics. When its dialects are taken into account, this language pushes the limits of NLP to find solutions to problems posed by its inherent nature. It is a diglossic language; the standard language is used in formal settings and in education and is quite different from the vernacular languages spoken in the different regions and influenced by older languages that were historically spoken in those regions. This should encourage NLP specialists to create dialect-specific corpora such as the Palestinian morphologically annotated Curras corpus of Birzeit University. In this work, we present the Lebanese Corpus Baladi that consists of around 9.6K morphologically annotated tokens. Since Lebanese and Palestinian dialects are part of the same Levantine dialectal continuum, and thus highly mutually intelligible, our proposed corpus was constructed to be used to (1) enrich Curras and transform it into a more general Levantine corpus and (2) improve Curras by solving detected errors.