 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNabra: Syrian Arabic Dialects with Morphological Annotations
Oct 26, 2023
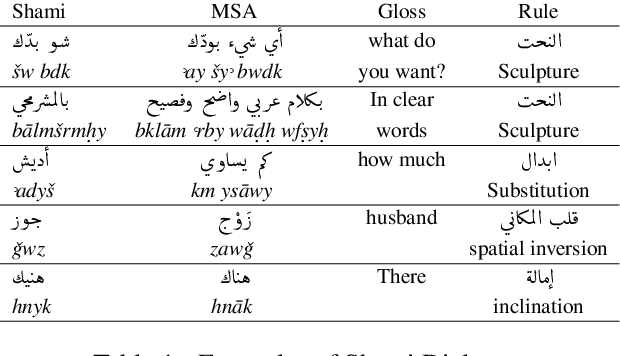

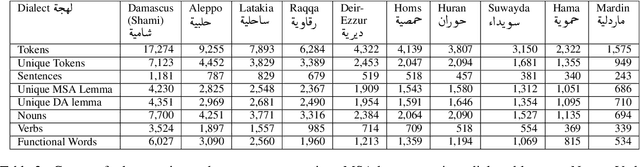
This paper presents Nabra, a corpora of Syrian Arabic dialects with morphological annotations. A team of Syrian natives collected more than 6K sentences containing about 60K words from several sources including social media posts, scripts of movies and series, lyrics of songs and local proverbs to build Nabra. Nabra covers several local Syrian dialects including those of Aleppo, Damascus, Deir-ezzur, Hama, Homs, Huran, Latakia, Mardin, Raqqah, and Suwayda. A team of nine annotators annotated the 60K tokens with full morphological annotations across sentence contexts. We trained the annotators to follow methodological annotation guidelines to ensure unique morpheme annotations, and normalized the annotations. F1 and kappa agreement scores ranged between 74% and 98% across features, showing the excellent quality of Nabra annotations. Our corpora are open-source and publicly available as part of the Currasat portal https://sina.birzeit.edu/currasat.